Data management for microservice architecture
Source: Microservices Data Management
In a microservice architecture, an application is composed of many independently deployable services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. Effective data management becomes crucial in such an architecture for several reasons. Below are the key reasons why data management is vital in microservice architecture:
- Resilience and Fault Isolation: Microservices are designed to be resilient. By decentralizing data management, services can remain insulated from the failures of others. If one microservice has a database issue, it won't necessarily bring down other services.
- Scalability: Different microservices may have different data storage and throughput requirements. By having a separate data management strategy, each service can scale its data independently, optimizing resource utilization and cost.
- Flexibility in Data Storage Options: Different types of data may require different storage solutions. For example, a user service may use a relational database, whereas a logging service might use a NoSQL database for better write performance.
- Simplified Development and Maintenance: Microservices allow teams to work independently. With dedicated data management for each service, developers can implement, update, and scale their service without coordinating with other teams.
- Domain-Driven Design (DDD): DDD focuses on clear boundaries and the autonomy of various components within a system. Data management within microservices aids in achieving these precise boundaries, allowing each service to have its own domain logic and data model.
Overview
Microservices data management patterns help manage the data of different components of the software. The data management patterns facilitate communication between databases of two or more software components.
In this article, we'll take a look at different types of microservices data management patterns which are:
- Database per Service - each service has its own private database
- Saga - use sagas, which a sequences of local transactions, to maintain data consistency across services
- CQRS - implement queries by maintaining one or more materialized views that can be efficiently queried
- Event sourcing - persist aggregates as a sequence of events
XXX per service
The service’s database is effectively part of the implementation of that service. It cannot be accessed directly by other services.
There are a few different ways to keep a service’s persistent data private. You do not need to provision a database server for each service. For example, if you are using a relational database then the options are:
- Private-tables-per-service – each service owns a set of tables that must only be accessed by that service
- Schema-per-service – each service has a database schema that’s private to that service
- Database-server-per-service – each service has it’s own database server.
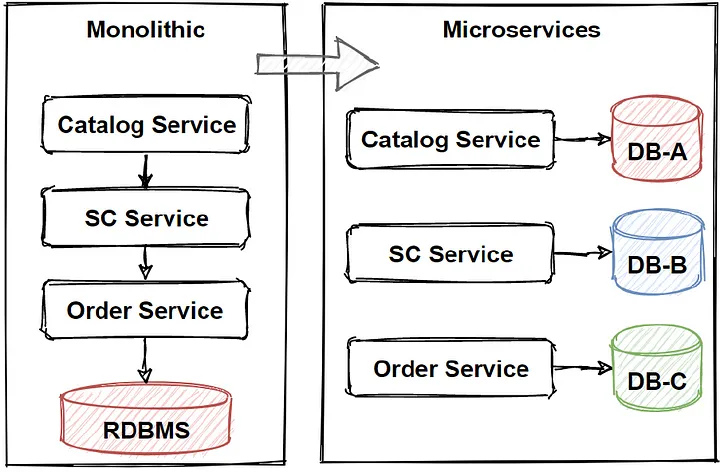
Database per service
Here's a simple diagram that illustrates the Database per Service pattern:
In the diagram above:
- Each "Service" (A, B, C) is represented as a microservice in the system.
- Each service has its own API endpoint (API A, API B, API C).
- Each service manages its own database (Database A, Database B, Database C).
- A client interacts with each microservice only through its API endpoints.
Benefits
- Helps ensure that the services are loosely coupled. Changes to one service’s database does not impact any other services.
- Each service can use the type of database that is best suited to its needs. For example, a service that does text searches could use ElasticSearch. A service that manipulates a social graph could use Neo4jc.
Drawbacks
- Implementing business transactions that span multiple services is not straightforward. Distributed transactions are best avoided because of the CAP theorem. Moreover, many modern (NoSQL) databases don’t support them.
- Implementing queries that join data that is now in multiple databases is challenging.
- Complexity of managing multiple SQL and NoSQL databases
There are various patterns/solutions for implementing transactions and queries that span services:
- Implementing queries that span services:
- Implementing transactions that span services - use the Saga pattern.
- API Composition - the application performs the join rather than the database. For example, a service (or the API gateway) could retrieve a customer and their orders by first retrieving the customer from the customer service and then querying the order service to return the customer’s most recent orders.
- Command Query Responsibility Segregation (CQRS) - maintain one or more materialized views that contain data from multiple services. The views are kept by services that subscribe to events that each services publishes when it updates its data. For example, the online store could implement a query that finds customers in a particular region and their recent orders by maintaining a view that joins customers and orders. The view is updated by a service that subscribes to customer and order events.
Event sourcing
The event sourcing pattern is typically used with the CQRS pattern to decouple read from write workloads, and optimize for performance, scalability, and security. Data is stored as a series of events, instead of directli storing the current state to data stores. Microservices replay events from an event store to compute the appropriate state of their own data stores.
Events represent the state transitions of things that have occurred in your system.
The pattern provides visibility for the current state of the application and additional context for how the application arrived at that state. The event sourcing pattern works effectively with the CQRS pattern because data can be reproduced for a specific event, even if the command and query data stores have different schemas.
By choosing this pattern, you can identify and reconstruct the application’s state for any point in time. This produces a persistent audit trail and makes debugging easier. However, data eventually becomes consistent and this might not be appropriate for some use cases.
What are the events really?
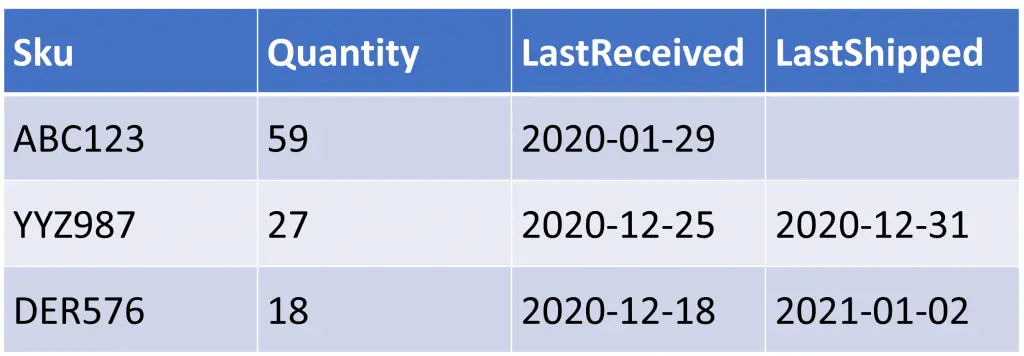
Source: Event Sourcing Example & Explained in plain English
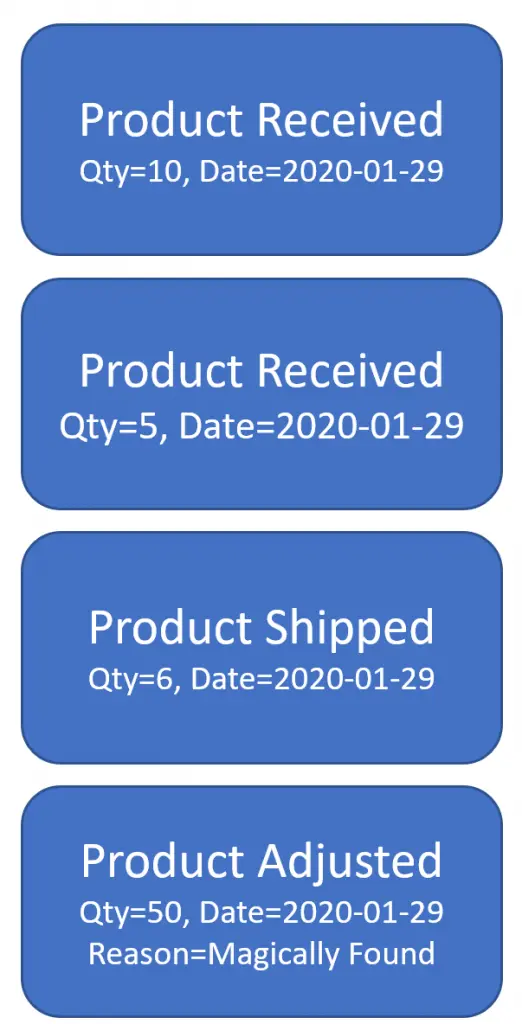
Source: Event Sourcing Example & Explained in plain English
Event Sourcing Architecture
Event Sourcing is an architectural design pattern that stores data in an append-only log. It is part of a wider ecosystem of design patterns that work together in various ways to allow developers to create the most effective architecture for their needs.
By deploying an Event Store as a design pattern within a wider architecture, it allows for the inclusion of other design patterns in the system that are the most suitable for the needs of the domain. For example, an event-sourced system works well within a CQRS architecture, however it's not necessary to use them together. Event Sourcing can be deployed alongside event driven architecture, or in conjunction with CQRS, an aggregate pattern, a command handler pattern, or one of many other patterns. Each individual pattern is a useful tool on its own, that can work in concert with other related patterns to make stronger, more specific patterns for your specific use case.
 Source: Event Sourcing Architecture
Source: Event Sourcing Architecture
An event store can be a key element of a system, and that system can be as simple or as complex as the business domain requires it to be. It's useful to consider putting an event-sourced system in a part of the architecture that requires the preservation of context for all events, as this is where Event Sourcing is most effective.
AWS implimentation
This pattern can be implemented by using either Amazon Kinesis Data Streams or Amazon EventBridge.
Amazon Kinesis Data Streams implementation
In the following illustration, Kinesis Data Streams is the main component of a centralized event store. The event store captures application changes as events and persists them on Amazon Simple Storage Service (Amazon S3).
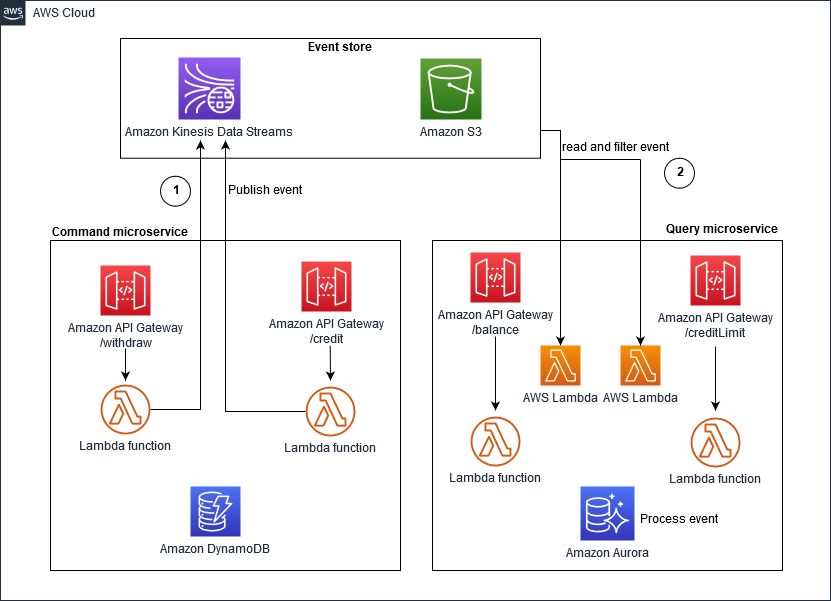 Source: Event sourcing pattern
Source: Event sourcing pattern
Amazon EventBridge implementation
In the following illustration, EventBridge is used as an event store. EventBridge provides a default event bus for events that are published by AWS services, and you can also create a custom event bus for domain-specific buses.
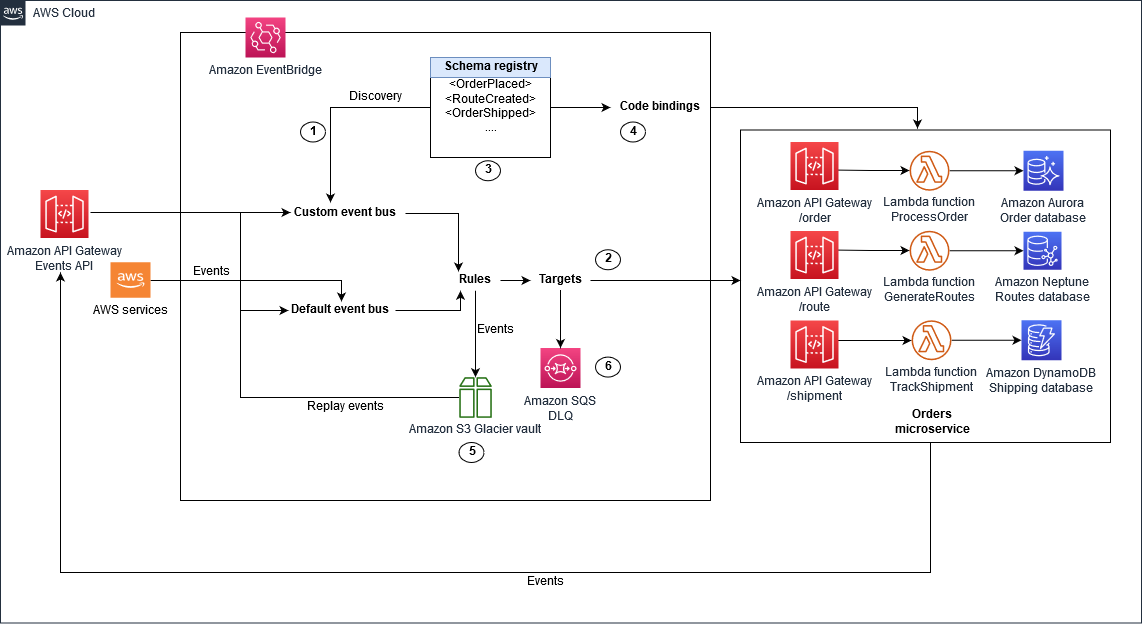 Source: Event sourcing pattern
Source: Event sourcing pattern
Command Query Responsibility Segregation (CQRS)
You have applied the Microservices architecture pattern and the Database per service pattern. As a result, it is no longer straightforward to implement queries that join data from multiple services. Also, if you have applied the Event sourcing pattern then the data is no longer easily queried.
Problem
How to implement a query that retrieves data from multiple services in a microservice architecture?
Solution
Define a view database, which is a read-only replica that is designed to support that query. The application keeps the replica up to data by subscribing to Domain events published by the service that own the data.
You can use the CQRS pattern to separate updates and queries if they have different requirements for throughput, latency, or consistency. The CQRS pattern splits the application into two parts: the command side and the query side (the same definition that is used by Meyer in Command and Query Separation, a command is any method that mutates state and a query is any method that returns a value).
- The command side handles
create,update, anddeleterequests. - The query side runs the
querypart by using the read replicas.
CQRS
 Source: EventStore - A Beginner’s Guide to Event Sourcing
Source: EventStore - A Beginner’s Guide to Event Sourcing
AWS implementation
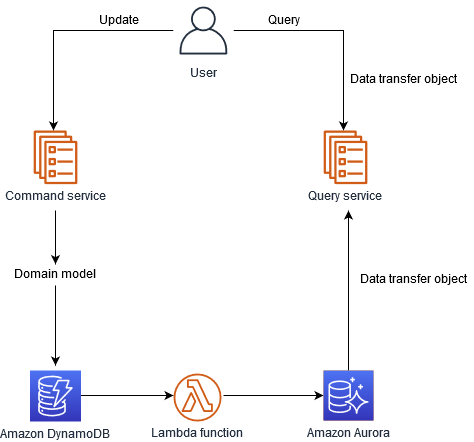 Source: CQRS pattern
Source: CQRS pattern
You should consider using this pattern if:
- You implemented the database-per-service pattern and want to join data from multiple microservices.
- Your read and write workloads have separate requirements for scaling, latency, and consistency.
- Eventual consistency is acceptable for the read queries.
The CQRS pattern typically results in eventual consistency between the data stores.
Sega pattern
The saga pattern is a failure management pattern that helps establish consistency in distributed applications, and coordinates transactions between multiple microservices to maintain data consistency. A microservice publishes an event for every transaction, and the next transaction is initiated based on the event's outcome. It can take two different paths, depending on the success or failure of the transactions.
Sagas can introduce quite a lot of complexity into your system. You'll have to build the set(s) of compensating transactions that are triggered by different failures. Depending on your application, this might require substantial work upfront to understand user behavior and potential failure modes.
Why is this a failure management pattern?
In a distributed transaction, multiple services can be called before a transaction is completed. When the services store data in different data stores, it can be challenging to maintain data consistency across these data stores.
To maintain consistency in a transaction, relational databases provide two-phase commit (2PC). This consists of a prepare phase and a commit phase.
- In the prepare phase, the coordinating process requests the transaction’s participating processes (participants) to promise to commit or rollback the transaction.
- In the commit phase, the coordinating process requests the participants to commit the transaction. If the participants cannot agree to commit in the prepare phase, then the transaction is rolled back.
In distributed systems architected with microservices, two-phase commit is not an option as the transaction is distributed across various databases. In this case, one solution is to use the saga pattern.
For example, let’s imagine that you are building an e-commerce store where customers have a credit limit. The application must ensure that a new order will not exceed the customer’s credit limit. Since Orders and Customers are in different databases owned by different services the application cannot simply use a local ACID transaction.
- Maintains data consistency across multiple services.
- Well-suited to any microservice application where idempotency (the ability to apply the same operation multiple times without changing the result beyond the first try) is important, like when charging credit cards.
- Choreographed saga: For microservices in which there aren't many participants or the set of counter transactions required is discrete and small consider choreographed saga as there's no single point of failure.
- Orchestrated saga: For more complex microservices, consider orchestrated saga.
How to implement it?
Implement each business transaction that spans multiple services is a saga. A saga is a sequence of local transactions. Each local transaction updates the database and publishes a message or event to trigger the next local transaction in the saga. If a local transaction fails because it violates a business rule then the saga executes a series of compensating transactions that undo the changes that were made by the preceding local transactions.
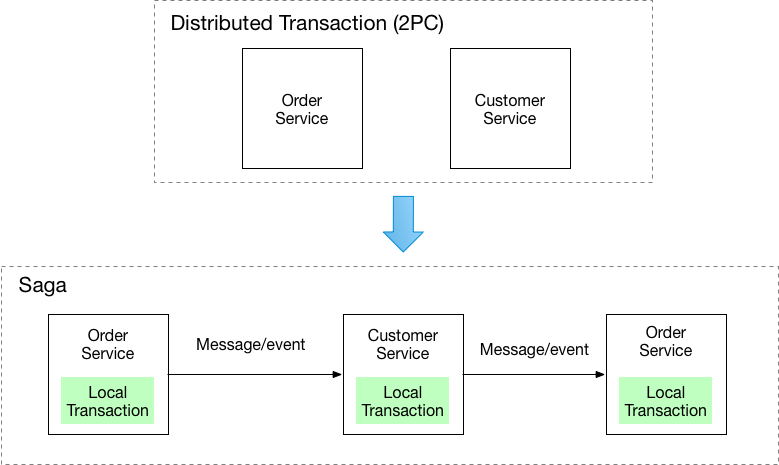 Source: Microservice Architecture by Kong
Source: Microservice Architecture by Kong
There are two ways of coordination sagas:
- Choreography - each local transaction publishes domain events that trigger local transactions in other services
- Orchestration - an orchestrator (object) tells the participants what local transactions to execute
Choreography strategy
Choreography is the simplest way to implement SAGA pattern. Each local transaction in chain is independent as they don’t have direct knowledge of each other. If your distributed transaction only includes from 2 to 4 local transactions then Choreography is very fit option. But having too many local transactions will make tracking which services listen to which events becomes very complex.
AWS EventBridge can help provide a choreography-based implementation of sagas
 Source: AWS-Building a serverless distributed application using a saga orchestration pattern
Source: AWS-Building a serverless distributed application using a saga orchestration pattern
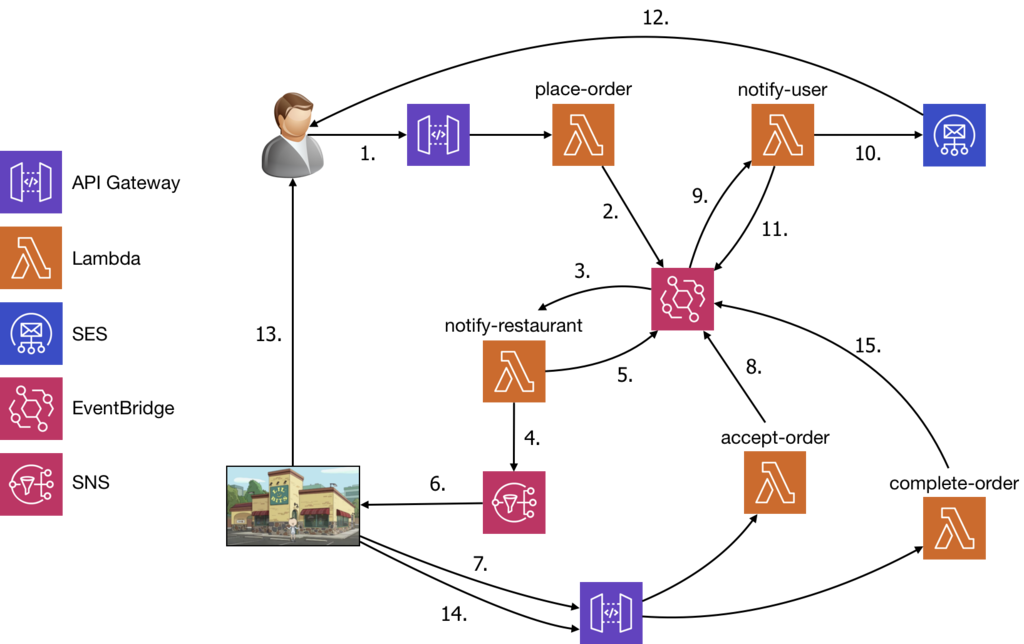 Source: Choreography vs Orchestration in the land of serverless
Source: Choreography vs Orchestration in the land of serverless
Orchestration strategy
- Easy to maintain the whole workflow in one place — Orchestrator.
- Avoid cyclic dependencies between services. All services only communicate with Orchestrator.
- The complexity of transaction remains linear when new steps are added.
AWS Step Functions can help provide an orchestration-style implementation of sagas
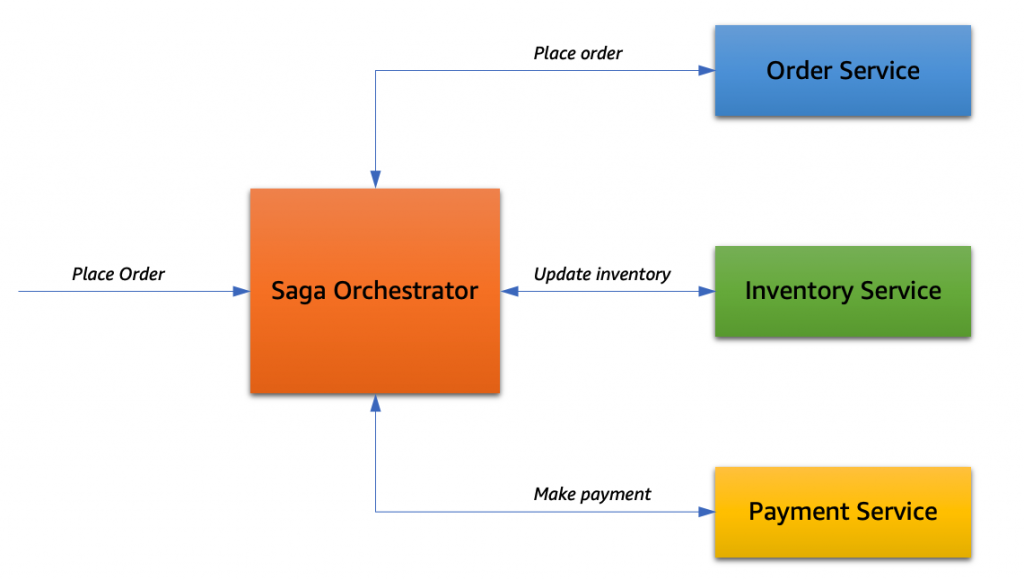 Source: AWS-Building a serverless distributed application using a saga orchestration pattern
Source: AWS-Building a serverless distributed application using a saga orchestration pattern
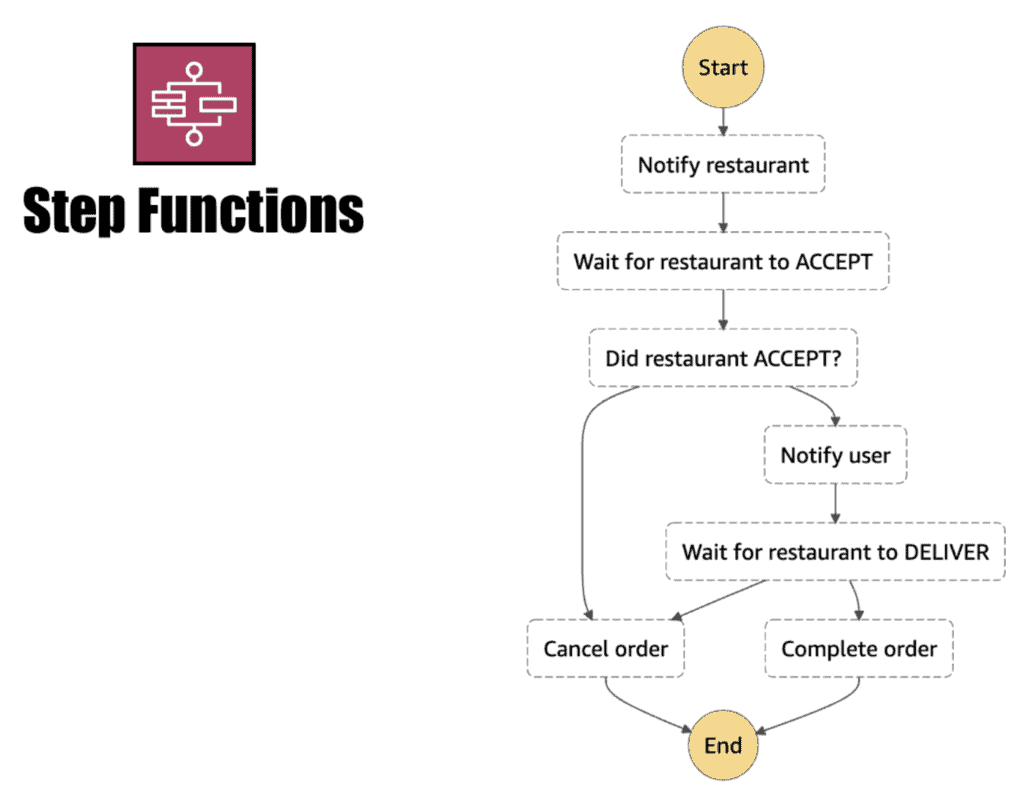 Source: Choreography vs Orchestration in the land of serverless
Source: Choreography vs Orchestration in the land of serverless
Why the hybrid approach is bad
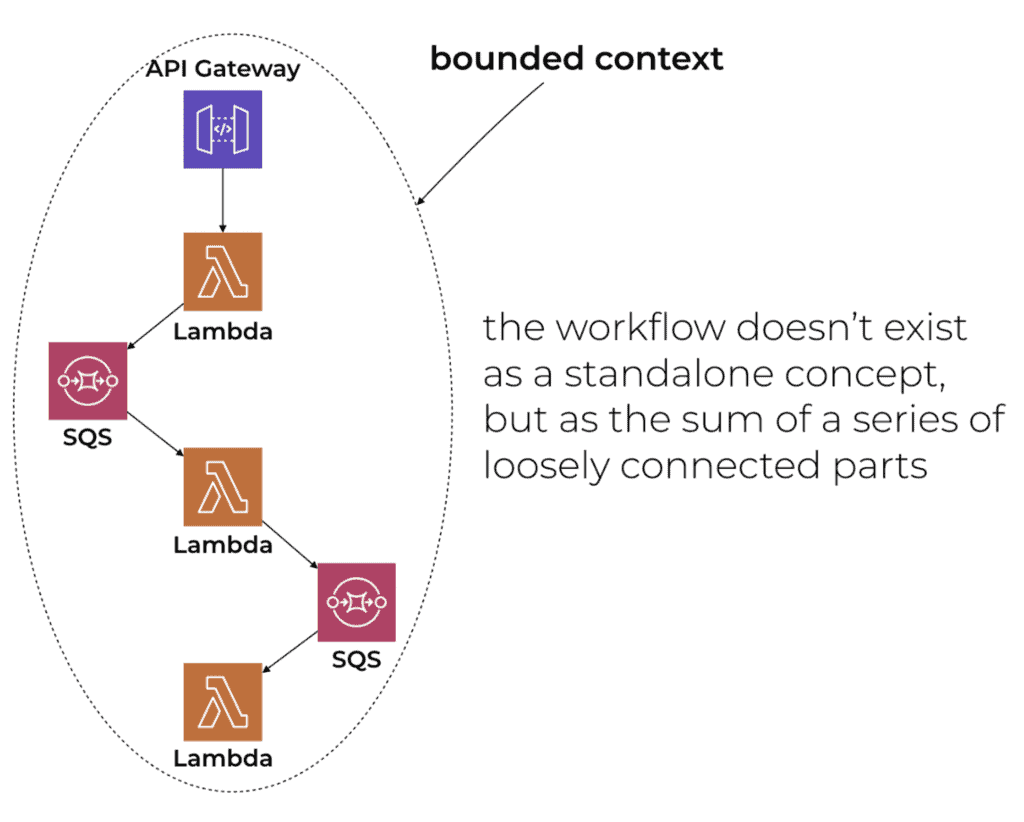 Source: Choreography vs Orchestration in the land of serverless
Source: Choreography vs Orchestration in the land of serverless
I love using events to integrate different services together in a loosely-coupled way. But I think it’s a bad idea when it’s done inside the same bounded context because the workflow doesn’t exist as a standalone concept that is explicitly captured and source controlled.
In these choreographed workflows, the workflow only exists as the sum of loosely connected functions. This makes them very difficult to reason about and debug. And there’s no easy way to implement even simple things like workflow level timeouts, or even task level tasks for that matter (e.g. timeout the order if the restaurant doesn’t accept or reject the order within 10 minutes).
If this is what you have today, you should consider moving these workflows to Step Functions instead.
But, between bounded contexts, I’ll publish and subscribe to events through SNS/EventBridge/Kinesis, etc. This is so that different parts of the larger system can stay loosely coupled and only build on each other’s events and can evolve and fail independently.
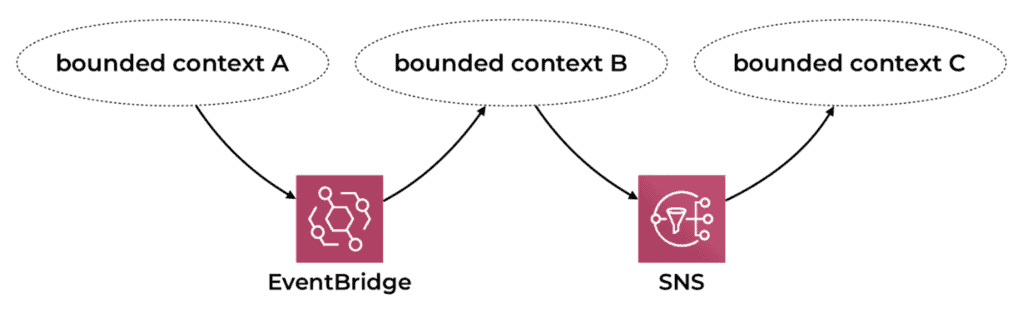 Source: Choreography vs Orchestration in the land of serverless
Source: Choreography vs Orchestration in the land of serverless
Reference: Saga pattern