Cache
Caching is a critical element of system performance and scalability, providing rapid data access and reducing strain on key parts of the system. By harnessing the power of data locality, caching keeps frequently accessed data readily available for quicker retrieval, whether embedded within your local machine or deployed across massive internet applications.
How caching works
Caching can be manifested through various approaches:
- In-Memory Application Cache: Data stored directly within an app's memory is quick to access but requires more memory across servers, impacting cost.
- Database Cache: Databases themselves cache data to avoid repeated calculations or operations.
- [imoprtant] Distributed In-Memory Cache: Tools like Memcached or Redis offer communal cache storage, reducing duplication across servers.
- [imoprtant] File System Cache: A file system can also be used to store commonly accessed files; CDNs are one example of a distributed file system that take advantage of geographic locality.
2 Considerations
Caching policies
Caching strategies are a balance between data freshness (accuracy) and data retrieval speed (performance). Limited cache size and higher operational costs necessitate strategic selection and eviction of cached data, referred to as caching policies:
- First-in First-out (FIFO): The oldest data is evicted first.
- Least Recently Used (LRU): Data not accessed recently is the first to go.
- Least Frequently Used (LFU): The least accessed items are evicted, regardless of when they were last used. This simple strategy keeps the data stored in the cache relatively "relevant" - as long as you choose a cache eviction policy and limited TTL combination that matches data access patterns.
Maintaining cache accuracy often involves timed entry expiration and aligning cache updates with data storage operations, such as write-through or write-behind caching.
Cache Coherence
To maintain coherent caches, systems may use:
- Write-through cache: Synchronize the cache and main memory together.
- Write-behind cache: Asynchronously update the main memory.
- Cache-aside (or lazy loading): Fills the cache on-demand, based on application data requests.
| Cache Policy | Pros | Cons |
|---|---|---|
| Write-through | Ensures consistency. A good option if your application requires more reads than writes. | Writes are slow. |
| Write-behind | Speed (both reads and writes.) | Risky. You're more susceptible to issues with consistency and you may lose data during a crash. |
| Cache-aside / Lazy Loading | Simplicity and reliability. Also, only requested data is cached. | Cache misses cause delays. May result in stale data. |
Exploring detailed case studies, like Facebook's lessons with Memcache or Stack Overflow's caching strategies, provides valuable real-world insights.
Key Cache Design Decisions
You must determine:
- Cache Size: Balance user latency improvements against cost and system complexity. Aim for an optimal cache hit rate.
- Eviction Policy: Choose based on your use case; LRU is a common and generally effective choice.
- Expiration Policy: Apply a TTL that reflects your data's change rate and relevance.
In practice, optimizing your caching strategy will likely require iterative adjustment to align with user requirements and system characteristics.
Consistent Hashing
TL;DR - Consistent Hashing is a distributed hashing scheme that provides a way to evenly distribute data across a cluster of cache servers and minimizes re-distribution of data when servers are added or removed.
Caching is like having a fast-access notepad for frequently needed information, sparing you the need to dig through the filing cabinet that is primary storage. Distributed caching spreads this notepad's pages across multiple servers, akin to distributing a workload among several assistants, enabling the cache to expand without a hitch. Consistent hashing, a more sophisticated method than traditional hashing, organizes this process in an efficient, resilient, and dynamically adaptable manner.
The Significance of Consistent Hashing
In a dependable distributed system, consistent availability is paramount, especially when handling unpredictable traffic spikes and the inevitable realities of network and hardware snags. Since each server in a distributed cache has only a slice of storage real estate, storing, locating, and accessing data swiftly and systematically becomes crucial. This calls for a well-organized data structure, and the hash table steps up to the task.
Traditional hashing has its merits when there's a stable set of dependable servers. However, once the server landscape starts changing due to additions, removals, or failures, traditional hashing starts to stumble.
Traditional Hash Tables
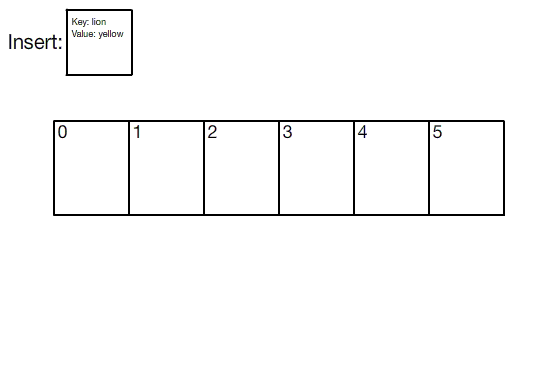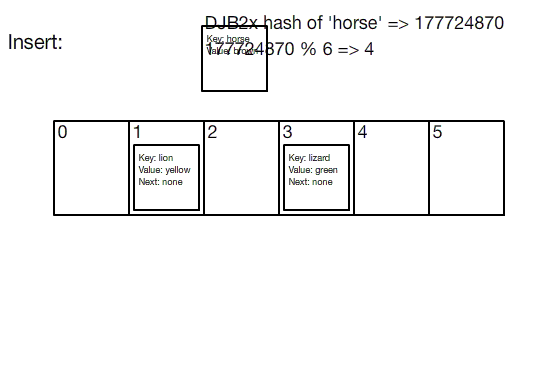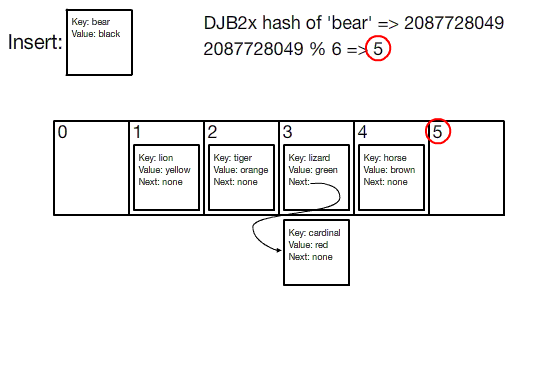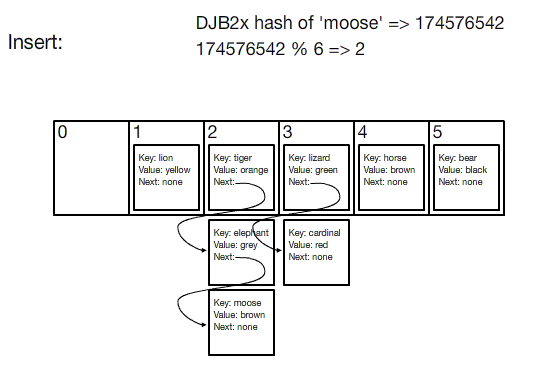
Source: Hash Tables
Picture a traditional hash table as a simple index. It includes:
- A key, the item you want to grab quickly later.
- A hash function, a magical black box that turns the key into a numerical index within a certain range.
- The hash value, the outcome of the black box, pointing to where the key's information is stored.
This system is designed for speed. But if distributed caching relied on a traditional hash table, any change in the number of servers means having to re-index everything. Let's visualize the problem:
When a server crashes or a new one joins, the equation serverKey = (hash_function(key) % N) crumbles because N—the total number of servers—changes, necessitating a complete do-over of the key-server mapping.
Consistent Hashing
Consistent hashing comes to the rescue, negating the need for a mass migration of data keys every time the server ensemble undergoes a change. Imagine a circular track, where both servers and keys are slotted into positions determined by the hash function, spreading from 0 to 2π (fully around the circle).
You can assign keys to whichever server is next on the circular track in a clockwise direction. To enhance efficiency and balance server loads, we give multiple segments on the circular track to each server.
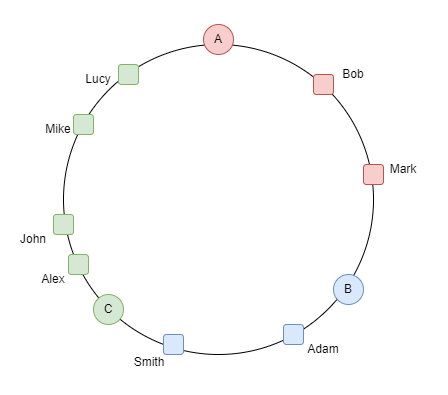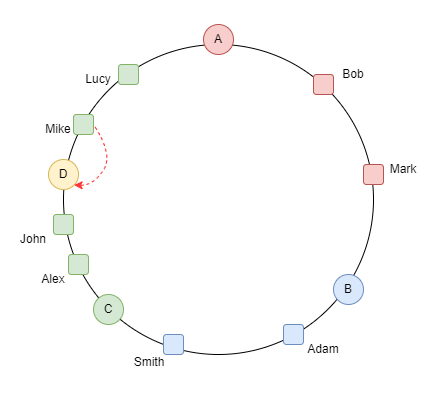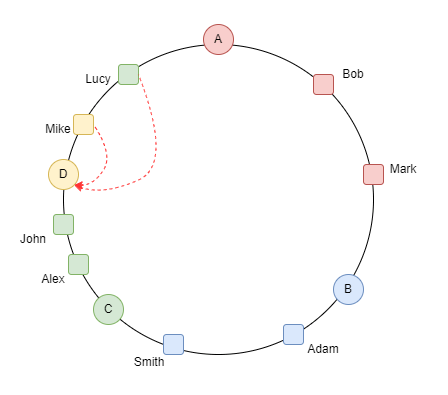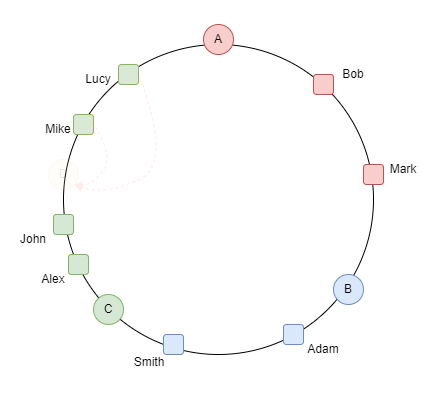
Source: Consistent Hashing in Action
So what if a server bites the dust? Unlike traditional methods, keys don't need rehashing. Their segments simply get reappointed to the next server along the circle's sweep. This approach offers clear advantages:
- Only a fraction of keys must be relocated to new servers.
- There's no need to recalculate hash values.
Consistent hashing presents a massive advance over traditional hashing techniques, by gracefully managing servers' dynamic dance of joining and departing. This way, it ensures a resilient and adaptable distributed cache, all while streamlining maintenance and scaling operations.
Real-world caching systems like Memcached and Redis harness consistent hashing, offering a seamless experience.