Stateful vs Stateless
Stateless and stateful architecture defines the user experience in specific ways. See why stateless is the choice for cloud architects.
Stateful services keep track of sessions or transactions and react differently to the same inputs based on that history. Stateless services rely on clients to maintain sessions and center around operations that manipulate resources, rather than the state.
Two potential points for confusion in considering stateless and stateful architectures are:
- A stateless service as a whole usually still needs to handle state in some form. Stateless simply refers to the fact that this state isn't tracked in server-side sessions.
- "State" is a broad term that can mean different things in different contexts. In this context, it refers specifically to maintaining sessions for authentication and similar multi-action processes. However, this is unrelated to storing data permanently in a database, which stateless services still usually do.
A Brief Historical Context
Historically, clients or end-user machines were "thin"--very limited in both hardware and software, while all of the heavy lifting was done by powerful servers. Therefore, it made sense for nearly all complexity and functionality to be handled "server-side".
With the explosion of the world wide web and the related growth of the HyperText Transfer Protocol (HTTP), web browsers, PCs, and other end-user software and hardware became more powerful, and clients became "thicker"; they handled more and more functionality that was previously handled by servers.
As software and digital systems grew in complexity, so did the requirements for sessions. Because HTTP is a stateless protocol, it's challenging for software to carry out long-running transactions, where system behavior depends on what happened previously.
For example, when you use online banking, you probably send several instructions to your bank, a simplified version of which, might be similar to:
- Hi, I'm me and I can prove it by entering this password.
- Hi, remember me? I just logged in, please transfer $1,000 to John.
- Yes, I have checked all the details and I would like to confirm this transfer.
In order to correctly execute the last two steps, your bank has to remember that step 1 was successful. Because HTTP (the protocol that your web browser uses to talk to your bank) is stateless, this isn't as simple as it may initially seem.
If you've seen the film Finding Nemo, you can think about using HTTP for any multi-step process as similar to trying to have a conversation with Dory who is incessantly forgetful.
There are two primary ways to handle this problem of "forgetfulness":
- Stateful: Store additional information server-side (on the bank's server), recording the state of the current transaction and waiting for the next instructions.
- Stateless: Store additional information client-side (in your web browser), passing along additional information with each step 'reminding' the server of the previous steps. In practice, this is usually implemented using cookies or localStorage.
There are challenges with each of these approaches.
With the stateful approach, more care has to be taken so that information stored on the server is consistent and so that a specific server is reserved for a client for the entire transaction.
With either approach, it's necessary to use cryptography to ensure that the client isn't lying about the previous steps in the transaction (for example, faking a login).
Prior to the modern enhancements of the internet, interactions across the web were typically done using stateful architectures. This was for a number of reasons, including:
- Less demand for internet services and therefore fewer scaling requirements. Web services could often be run entirely off a single physical piece of hardware.
- Clients that were typically very limited in terms of both hardware and software.
- Simpler use cases for internet-connected applications: state was not as complicated, so maintaining stateful services was less of a burden.
As all of these have changed, there has been a move from stateful to stateless architectures.
Stateful vs Stateless: A Comparison
| Stateful | Stateless | |
|---|---|---|
| Performance | Faster, the session data sits in RAM(memory level) | Slower, it needs TCP(Network) to get data from DB |
| Horizontal scaling | Complex, server needs to send a cookie to retain the connection from a client to the same server | Easy, no matter which server handle the call, it treats the request as the first time |
| Server crash handling | Bad, when a server down, users probably need to logout and start from the beginning | Good, we can fail over to a new server |
In a stateless environment, caching enhances performance by reducing redundant computations or database queries, as each request contains self-contained details, making it conducive to storing and retrieving cached results without relying on server-side state.
SOAP-, REST-, and GraphQL-based Web Services
The paradigm shift from stateful to stateless architectures is closely linked to the popularity of different ways to build application programming interfaces (APIs) and web applications. In the early 2000s, SOAP (Simple Object Access Protocol) was the dominant methodology. While it's possible to create stateless SOAP-based architectures, the protocol also allowed for creating stateful services, maintaining state server-side. Many applications ultimately did this.
REST (REpresentational State Transfer) is a design pattern rather than a protocol like SOAP, and RESTful services can be built in different ways. Following this pattern, which is always fully stateless, RESTful grew in popularity and overtook SOAP.
GraphQL is the new kid on the block, starting to eat REST's lunch. Like RESTful services, GraphQL-based services are entirely stateless, and give clients even more control over what data is fetched from servers.
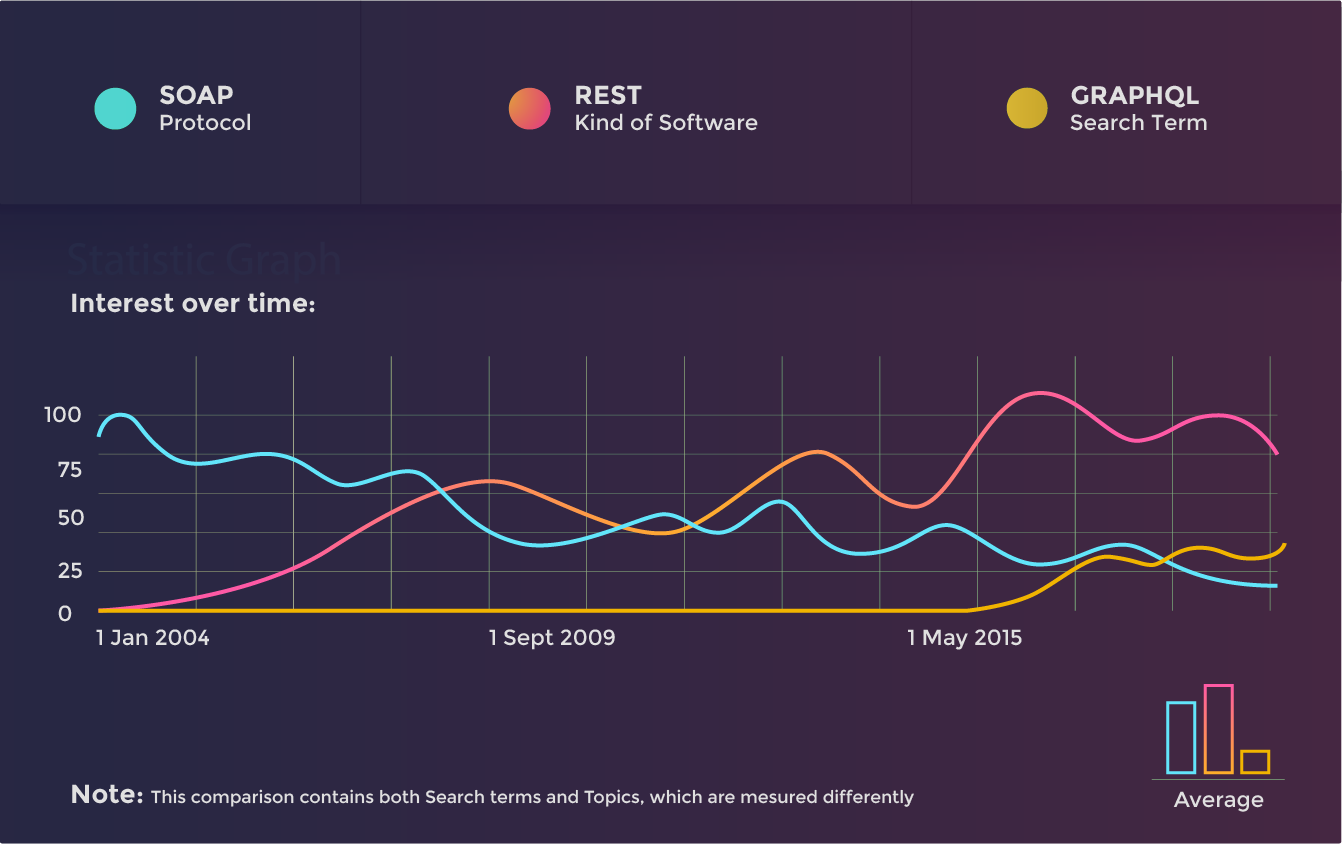
Source: Stateful vs Stateless Architecture: Why Stateless Won
The Advantages of Stateless Solutions
Incorporating a stateless solution to a web service or app has a number of advantages over an equivalent stateful implementation.
For starters, stateful server implementations are complex to configure. They require the ability to reference (potentially multiple) states, which could lead to a number of incomplete transactions and sessions throughout a system. Connection management from the client to the server is also a factor: it requires a "sticky" connection between each client and server pair, which is an inherently a hard-to-scale limitation.
One of the biggest drawbacks of stateful architecture is its inability to scale easily and efficiently. If the state is managed server-side, it means each step in a long-running transaction has to be handled by the same server.
For small-scale services where only a single physical server is required, it's easier to keep track of state. However, if more servers are required to handle the load from thousands or millions of users, it's inconvenient to
- To have to ensure a specific user's requests always hit the same server,
- To synchronize the state for each user across all servers.
With a stateless architecture, a user could hit a different server on each step of the transaction because it doesn't matter if one of the servers is too busy or goes down; the transaction can continue without issue.
Stateless: Laying Foundations for Cloud-Based Microservices
The independence or loose coupling between client and server allows for more flexibility when developing a solution that would, otherwise, rely heavily on server-side complexity that is characteristic of stateful systems.
What this means for modern-day technology stacks is that they have become far more modular. Stateless architectures have increasingly advocated for the use of smaller, simpler microservices, which help move us away from the monolithic solutions of the past.
While stateless services don't necessarily equate to microservices or cloud-based solutions, there is a correlated trend. A business that has already implemented stateless services can more easily break separate functionality into different microservices. And a business that has already implemented microservices can more easily do a staged migration to the cloud, moving one service at a time without impacting the others.
Compared to older patterns of monolithic, stateful services, this makes it easier to keep up with more modern demands of scaling globally and following agile methodologies to release new features far more frequently than was previously expected.
This, in turn, allows for easier horizontal scaling of services. Adding more servers to a fleet is far more straightforward if these servers don't have to worry about tracking state, and this can result in cost savings for the business as they can quickly provision more servers to deal with demand peaks. Following these patterns, an e-commerce site, for example, can double or triple its capacity when there is demand, without having to pay for additional computing power when demand decreases.
Based on these factors, choosing a stateless architecture for any modern-day, online service is almost always the correct path.
Looking Forward
Stateful architecture made sense in a server-focused world where clients were merely thin interfaces to more powerful servers. When services only needed to scale to hundreds or thousands of users, having a strong coupling between users and servers wasn't an issue.
Now that we have powerful client machines and web services are often required to scale to millions or even billions of users, we've needed to evolve not only hardware and software, but also design patterns and concepts.