Disaster Recovery
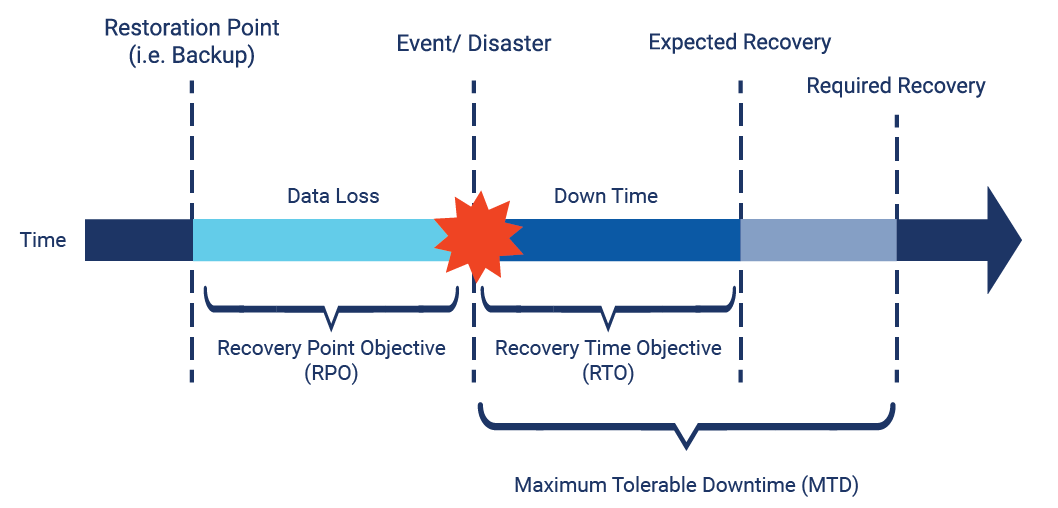
- Recovery time objective (RTO) – The time it takes a system to return to a working state after a disaster. In other words, RTO measures downtime.
- Recovery point objective (RPO) – The amount of data that can be lost (measured in time). For an Aurora global database in AWS, RPO is typically measured in seconds.
- Maximum Tolerable Downtime (MTD) - Maximum tolerable downtime, also sometimes referred to as Maximum Allowable Downtime (MAD), represents the total amount of downtime that can occur without causing significant harm to the organization's mission.
When a snapshot is needed to replace the production database
In some unfortunate situation, you may face a data lose problem due to the below reasons:
- Incorrect deployments or schema changes: As in your case, this is a frequent cause.
- Human errors: Often due to accidental deletions or incorrect scripts.
- Application bugs or logic errors: Can lead to partial or complete data loss.
- Infrastructure failures: Disks, power, or network failures can cause data corruption or loss.
- Security breaches: Malicious actors may delete or encrypt data.
- Software upgrades: Mismanaged upgrades can result in loss or corruption.
- Replication/backup misconfiguration: Poorly configured systems may not retain the latest data.
In most production environments, the use of transaction logging (e.g., Write-Ahead Logging (WAL) in PostgreSQL or binary logs in MySQL) is typically preferred over using a DB dump for data recovery. This is because transaction logs offer granular, automated recovery that minimizes data loss, while DB dumps are usually employed as a last-resort or manual recovery option.
Why Transaction Logging is Preferred
- Granular Recovery (Point-in-Time Recovery - PITR):
- Transaction logs capture every change made to the database, allowing point-in-time recovery (PITR). This enables you to recover the database to an exact point in time, such as just before the data loss or corruption occurred.
- With WAL (Write-Ahead Logs) in PostgreSQL or Binary Logs in MySQL, you can replay transactions after restoring a base backup (e.g., a snapshot), ensuring that all data changes are recovered with minimal loss.
- Continuous and Automated:
- Transaction logs are continuously maintained in the background as part of the database’s normal operation. This means the database always has a record of changes, making recovery automated and fast compared to manually restoring a DB dump.
- In contrast, DB dumps are typically taken at intervals (e.g., daily or weekly), meaning any data changes after the last dump are lost if you rely on just a DB dump for recovery.
- Minimal Data Loss:
- Since transaction logs capture each individual operation in real time, recovering from them usually results in minimal or no data loss. DB dumps, on the other hand, only capture the database state at the time the dump was taken, so any data created or modified after the dump is lost unless it’s backed up again.
- Smaller and Faster Backups:
- Transaction logs are much smaller in size compared to full DB dumps, which means they can be stored more frequently and replayed quickly for recovery.
- A DB dump can be very large and takes longer to restore, especially for larger databases.
When DB Dumps Are Used
DB dumps are still an important part of the backup strategy but are usually used in conjunction with transaction logs for the following reasons:
- Full Database Restore: If a full restore is needed (e.g., after catastrophic failure or corruption), you first restore the DB dump, and then use transaction logs to bring the database up to the latest point in time.
- Long-Term Backup: DB dumps can be stored offsite or in secure locations for disaster recovery purposes. They serve as a snapshot of the database at a specific time.
- Non-transactional Systems: In some environments where transaction logs aren’t available (e.g., certain NoSQL databases or environments without logging configured), a DB dump is the only way to recover data.
Combined Approach: DB Dump + Transaction Logs
The industry standard is to combine both approaches for a complete backup and recovery strategy:
- Frequent Full Backups (DB Dump): Take regular full database backups (e.g., weekly or daily) to serve as a base for recovery.
- Transaction Logs (WAL/Binary Logs): Enable continuous transaction logging to capture incremental changes between full backups.
- Point-in-Time Recovery: Use a combination of the latest DB dump and the transaction logs to perform a point-in-time recovery, minimizing the risk of data loss.
- Take a daily DB dump of the production database and store it.
- Enable continuous WAL logging (in PostgreSQL) or binary logging (in MySQL).
- If there’s data loss:
- Restore the most recent DB dump.
- Replay the transaction logs from the point of the DB dump to the time just before the issue occurred.
This way, the DB dump provides a baseline, and transaction logs ensure that you can recover the latest data with minimal loss.
High availability & Fault Tolerance
Both high availability and fault tolerance want to have the ability of a system to remain in operation even if some of components in the system fail. The difference between them is...
- High availability: There should be at least one running instances/servers in the event of component failures
- Fault Tolerance: The number of running instances/servers should not fail below a specific minimum number of instances