Normalization
By limiting a table to one purpose, you reduce the number of duplicate data that is contained within your database, which helps eliminate some issues stemming from database modifications. To assist in achieving these objectives, some rules for database table organization have been developed. The stages of organization are called normal forms; there are three normal forms most databases adhere to using. As tables satisfy each successive normalization form, they become less prone to database modification anomalies and more focused toward a sole purpose or topic.
Reasons for Normalization
There are three main reasons to normalize a database. The first is to minimize duplicate data, the second is to minimize or avoid data modification issues, and the third is to simplify queries. As we go through the various states of normalization, we’ll discuss how each form addresses these issues, but to start, let’s look at some data which hasn’t been normalized and discuss some potential pitfalls. Once these are understood, I think you’ll better appreciate the reason to normalize the data. Consider the following table:

Note: The primary key columns are underlined. The first thing to notice is this table serves many purposes including:
- Identifying the organization’s salespeople
- Listing the sales offices and phone numbers
- Associating a salesperson with a sales office
- Showing each salesperson’s customers
As a DBA, this raises a red flag. In general, I like to see tables that have one purpose. Having the table serve many purposes introduces many of the challenges; namely, data duplication, data update issues, and increased effort to query data.
Data Duplication and Modification Anomalies
Notice that for each SalesPerson, we have listed both the SalesOffice and OfficeNumber. This information is duplicated for each SalesPerson. Duplicated information presents two problems:
It increases storage and decreases performance. It becomes more difficult to maintain data changes. For example:
- Consider if we move the Chicago office to Evanston, IL. To properly reflect this in our table, we need to update the entries for all the SalesPersons currently in Chicago. That potentially this could involve hundreds of updates.
- Also consider what would happen if John Hunt quits. If we remove his entry, then we lose the information for New York.
These situations are modification anomalies. There are three modification anomalies that can occur:
Insert Anomaly
There are facts we cannot record until we know information for the entire row. In our example, we cannot record a new sales office until we also know the sales person. Why? Because in order to create the record, we need provide a primary key. In our case, this is the EmployeeID.
Update Anomaly

The same information is recorded in multiple rows. For instance, if the office number changes, then there are multiple updates that need to be made. If these updates are not successfully completed across all rows, then an inconsistency occurs.
Deletion Anomaly

Deletion of a row can cause more than one set of facts to be removed. For instance, if John Hunt retires, then deleting that row causes us to lose information about the New York office.
Definition of Normalization
Theory of Data Normalization in SQL is still being developed further. For example, there are discussions even on 6th Normal Form. However, in most practical applications, normalization achieves its best in 3rd Normal Form. The evolution of Normalization theories is illustrated below.
![]()
Assume a video library maintains a database of movies rented out. Without any normalization, all information is stored in one table as shown below.
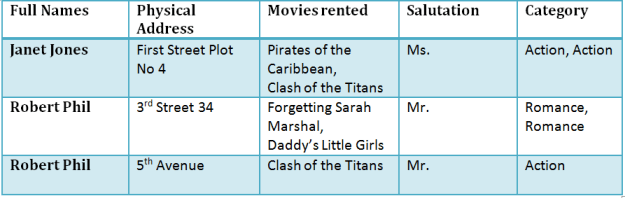
1NF Rules
- Each table cell should contain a single value.
- Each record needs to be unique. (There are not repeating groups of column)
Before 1NF
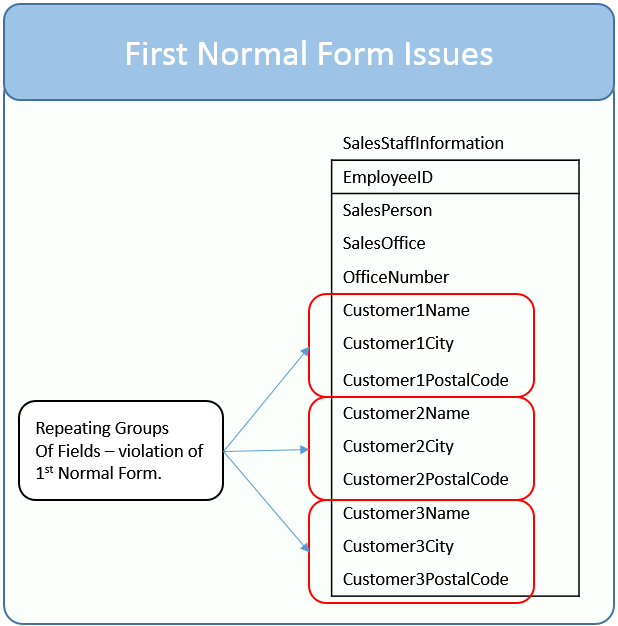 After 1NF
After 1NF
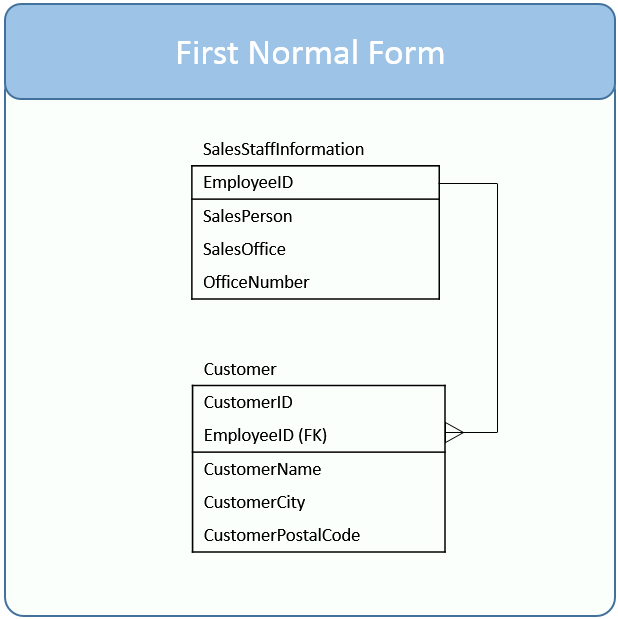
2NF Rules
- Rule 1- Be in 1NF
- Rule 2- All the columns depend on all its table’s primary key.
A table is in 2NF if it is in 1NF and if all non-key attributes are dependent on all of the key. Since a partial dependency occurs when a non-key attribute is dependent on only a part of the composite key, the definition of 2NF is sometimes phrased as: “A table is in 2NF if it is in 1NF and if it has no partial dependencies.”
In the other word, we can have composite keys if the non-key columns depend on all the candidate key.
It is clear that we can't move forward to make our simple database in 2nd Normalization form unless we partition the table above. Before 2NF
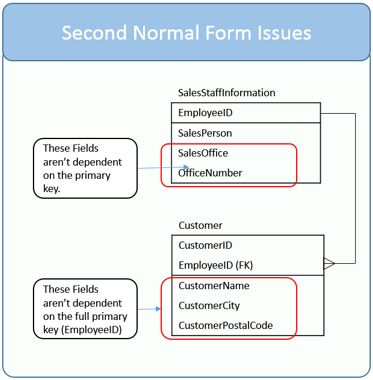 It stands to reason you should only need to know the CustomerID. Given this, the Customer table isn’t in 2nd normal form as there are columns that aren’t dependent on the full primary key. They should be moved to another table.
It stands to reason you should only need to know the CustomerID. Given this, the Customer table isn’t in 2nd normal form as there are columns that aren’t dependent on the full primary key. They should be moved to another table.
After 2NF
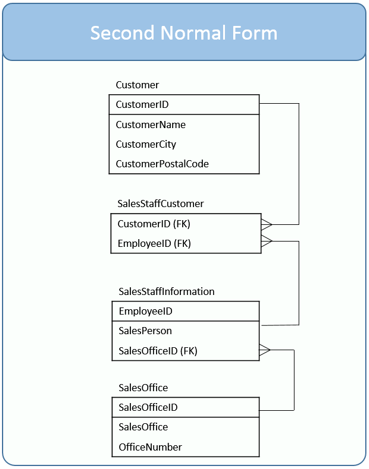 Now let’s create a table named SalesStaffCustomer to describe which customers a sales person calls upon. This table has two columns, CustomerID and EmployeeID. Together, they form a primary key. Separately, they are foreign keys to the Customer and SalesStaffInformation tables respectively
Now let’s create a table named SalesStaffCustomer to describe which customers a sales person calls upon. This table has two columns, CustomerID and EmployeeID. Together, they form a primary key. Separately, they are foreign keys to the Customer and SalesStaffInformation tables respectively
3NF Rules
- Rule 1- Be in 2NF
- Rule 2- Has no transitive functional dependencies
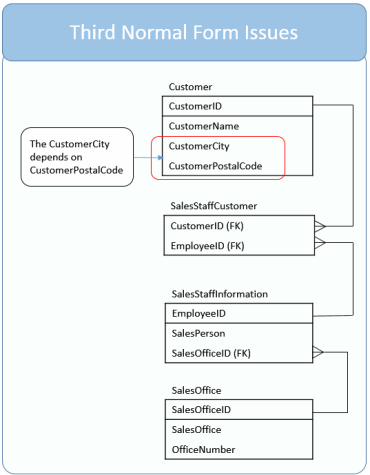
Table 1 Customer ID is foreign to primary key in below table
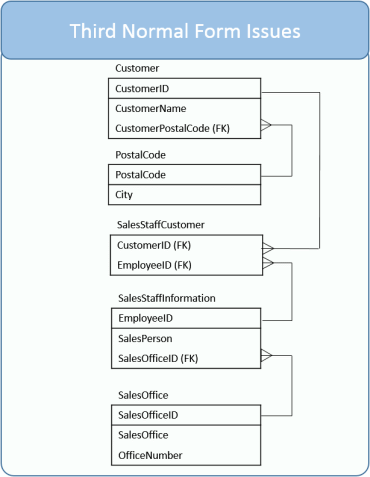
This table we have Customer ID as primary key
Can Normalization Get out of Hand?
Can database normalization be taken too far? You bet! There are times when it isn’t worth the time and effort to fully normalize a database. In our example, you could argue to keep the database in second normal form, that the CustomerCity to CustomerPostalCode dependency isn’t a deal breaker.
I think you should normalize if you feel that introducing update or insert anomalies can severely impact the accuracy or performance of your database application. If not, then determine whether you can rely on the user to recognize and update the fields together.
There are times when you’ll intentionally denormalize data. If you need to present summarized or complied data to a user, and that data is very time consuming or resource intensive to create, it may make sense to maintain this data separately.
Several years ago, I developed a large engineering change control system which, on the home page, showed each engineer’s the parts, issues, and tasks requiring their attention. It was a database wide task list. The task list was rebuilt on-the-fly in real-time using views. Performance was fine for a couple of years, but as the user base grew, more and more DB resources were being spent to rebuild the list each time the user visited the home page.
I finally had to redesign the DB. I replaced the view with a separate table that was initially populated with the view data and then maintained with code to avoid anomalies. We needed to create complicated application code to ensure it was always up-to-date.
For the user experience, it was worth it. We traded off complexity in dealing with update anomalies for improved user experience.
Types of dependencies
- Full dependencies are when the full key is required (all columns of the key) to determine another attribute.
- Partial dependencies are when the key is composite and some but not all of the columns of the key determine another attribute. (This may still be more than one column.)
- Transitive dependencies are when changing a non-key column, might cause any of the other non-key columns to change.

References
Get Ready to Learn SQL: 8. Database Normalization Explained in Simple English