Swarm
The problem
Without all those platform features, how do we easily deploy and maintain our dozens, or hundreds, or even thousands of containers across many servers or instances? That brings to bear some really new problems that weren't previously problems for small organizations.
- How do we automate container lifecycle?
- How can we easily scale out/in/up/down?
- How can we ensure our containers are re-created if they fail?
- How can we replace containers without downtime (blue/green deploy)?
- How can we control/track where containers get started?
- How can we create cross-node virtual networks?
- How can we ensure only trusted servers run our containers?
- How can we store secrets, keys, passwords and get them to the right container (and only that container)?
The solution
Swarm is a server clustering solution that brings together different operating systems or hosts, or nodes, or whatever you want to call them, into a single manageable unit that you can then orchestrate the lifecycle of your containers in.
Swarm isn't eabled by default. That was one of the design goals was that none of the Swarm code would affect the existing Docker daemon, and that all the tools and systems out there that were already relying on Docker, or maybe they had their own orchestration on top of Docker, would continue to function and not be interfered with by Swarm.
Overview
Docker Engine v1.12.0 and later allow developers to deploy containers in Swarm mode. A Swarm cluster consists of Docker Engine deployed on multiple nodes. Manager nodes perform orchestration and cluster management. Worker nodes receive and execute tasks from the manager nodes.
A service, which can be specified declaratively, consists of tasks that can be run on Swarm nodes. Services can be replicated to run on multiple nodes. In the replicated services model, ingress load balancing and internal DNS can be used to provide highly available service endpoints. (Source: Docker Docs: Swarm mode)
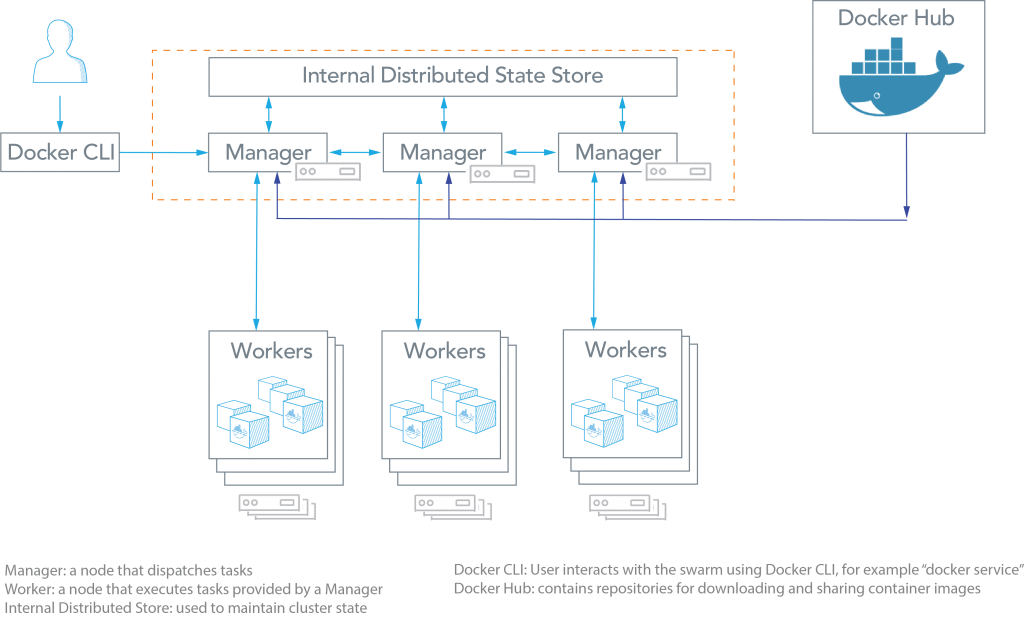
As can be seen from the figure above, the Docker Swarm architecture consists of managers and workers. The user can declaratively specify the desired state of various services to run in the Swarm cluster using YAML files. Here are some common terms associated with Docker Swarm:
Manager node & worker node
- Node: A node is an instance of a Swarm. Nodes can be distributed on-premises or in public clouds.
- Swarm: a cluster of nodes (or Docker Engines). In Swarm mode, you orchestrate services, instead of running container commands.
- Worker Nodes: These nodes collect and run tasks from manager nodes.
- Manager Nodes: These nodes receive service definitions from the user, and dispatch work to worker nodes. Manager nodes can also perform the duties of worker nodes.
Service & Task
With the Docker run command, we could only really deploy one container. Docker run command didn't have concepts around how to scale out or scale up. So we needed new commands to deal with that. That's where the Docker service command comes from.
In a swarm, it replaces the Docker run command, and allows us to add extra features to our container when we run it, such as replicas to tell us how many of those it wants to run. Those replicas are known as tasks. A single service can have multiple tasks, and each one of those tasks will launch a container.
- Service: A service specifies the container image and the number of replicas. Here is an example of a service command which will be scheduled on 2 available nodes:
docker service create --replicas 2 --name mynginx nginx - Task: A task is an atomic unit of a Service scheduled on a worker node. In the example above, two tasks would be scheduled by a master node on two worker nodes (assuming they are not scheduled on the Master itself). The two tasks will run independently of each other.
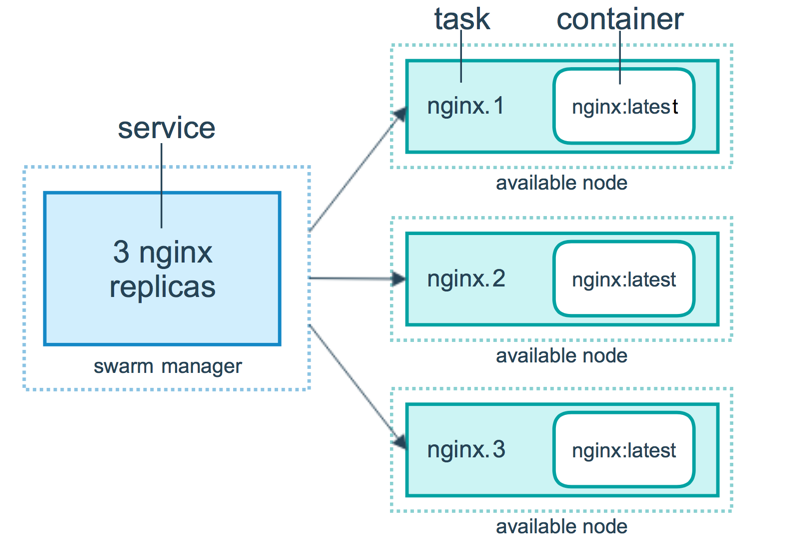 Source: Services, tasks, and containers
Source: Services, tasks, and containers
In this example, we've created a service using docker service create to spin up an Nginx service. But we've told it that we'd like three replicas. So it will use the manager nodes to decide where in the swarm to place those. By default, it tries to spread them out. Each node would get its own copy of the Nginx container up to the three replicas.
Tasks and scheduling
The underlying logic of Docker swarm mode is a general purpose scheduler and orchestrator. The service and task abstractions themselves are unaware of the containers they implement. Hypothetically, you could implement other types of tasks such as virtual machine tasks or non-containerized process tasks. The scheduler and orchestrator are agnostic about the type of task. However, the current version of Docker only supports container tasks.
The diagram below shows how swarm mode accepts service create requests and schedules tasks to worker nodes.
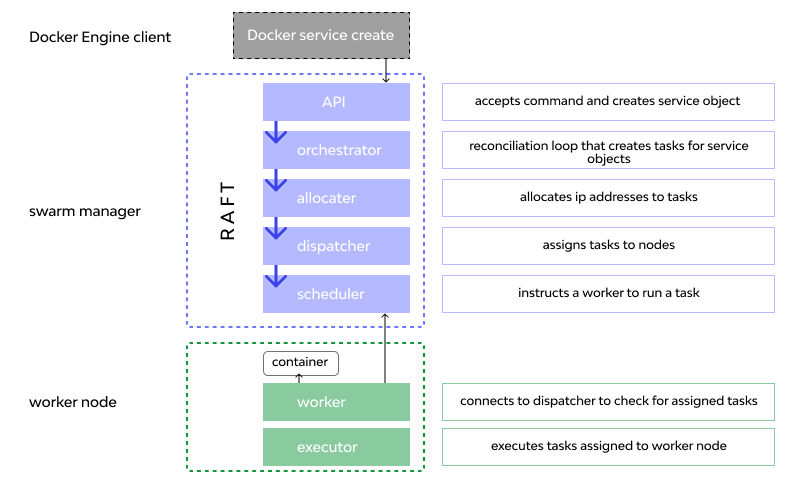 Source: Services, tasks, and containers
Source: Services, tasks, and containers
With Swarm, there're a bunch of background services, such as the scheduler, and the dispatcher, and the allocator and orchestrator, that help make decisions around what the workers should be executing at any given moment.
- The workers are constantly reporting in to the managers and asking for new work.
- The managers are constantly doling out new work and evaluating what you've told them to do against what they're actually doing.
Then if there's any reconciliation to happen, they will make those changes, such as to spin up three more replicate tasks in that service. The orchestrator will realize that and then issue orders down to the workers and so on.
The raft consensus group
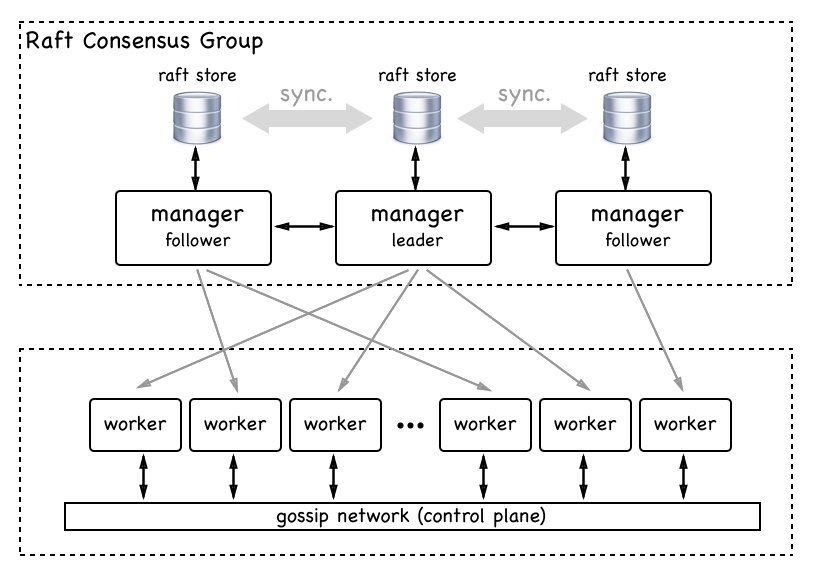 Source: The Docker Swarm architecture
Source: The Docker Swarm architecture
What is Raft
Raft is a distributed consensus algorithm designed to be understandable and durable. In general, the algorithm is useful when we want to order the events that happen in a distributed system on different nodes.
What is consensus?
Consensus is a fundamental problem in fault-tolerant distributed systems. Consensus involves multiple servers agreeing on values. Once they reach a decision on a value, that decision is final. Typical consensus algorithms make progress when any majority of their servers is available; for example, a cluster of 5 servers can continue to operate even if 2 servers fail. If more servers fail, they stop making progress (but will never return an incorrect result).
Consensus typically arises in the context of replicated state machines, a general approach to building fault-tolerant systems. Each server has a state machine and a log. The state machine is the component that we want to make fault-tolerant
- Manager node have a database locally on them known as the Raft Database. It stores their configuration and gives them all the information they need to have to be the authority inside a swarm.
- The managers themselves can also be workers. Of course, you can demote and promote workers and managers into the two different roles. When you think of a manager, typically think of a worker with permissions to control the swarm.
Odd number of node
Consensus algorithm (e.g. raft) requires the cluster contains an odd number of nodes to avoid the split-brain problem. You can start with one, but if you want true fault tolerance, you need three.
A cluster of N nodes, and if N is odd (N = 2k + 1), can handle k node fails. As long as a majority of nodes is alive, it can work normally. If one node fails, and we still have the majority, everything is fine. Only when you lose majority of nodes, you have a problem.
Majority: more than 50% of the nodes in a cluster
There is no reason to force the cluster to have an odd number of nodes, and implementations don't consider this as a problem and thus don't handle it (drop nodes). You can run a consensus algorithm on an even number of nodes, but it usually makes more sense to have it odd.
- 3 node cluster can handle 1 node fail (the majority is 2 nodes).
- 4 node cluster can handle 1 node fail (the majority is 3 nodes).
- 5 node cluster can handle 2 node fail (the majority is 3 nodes).
- 6 node cluster can handle 2 node fail (the majority is 4 nodes).
Further reading
- [Is Docker Swarm going to change how we do microservices APIs?](https://lab.wallarm.com/is-docker-swarm-going-to-change-how-we-do-microservices-apis-a7b2782a3dea/