S3
Amazon S3 (Simple Storage Service) is a scalable and highly durable object storage service which allows users to store and retrieve data, such as files, documents, images, and more, through a web interface. S3 is known for its reliability, low-latency access, and data protection features. It's widely used for data backup, website hosting, data archiving, and as a foundation for various cloud-based applications.
Basic
If you configured your server access logs this way, then there would be an infinite loop of logs. This is because when you write a log file to a bucket, the bucket is also accessed, which then generates another log. A log file would be generated for every log written to the bucket, which creates a loop. This would create many logs and increase your storage costs.
Source: Can I push server access logs about an Amazon S3 bucket into the same bucket?
What is prefix
In Amazon S3, you can use prefixes to organize your storage. A prefix is a logical grouping of the objects in a bucket. The prefix value is similar to a directory name that enables you to store similar data under the same directory in a bucket. When you programmatically upload objects, you can use prefixes to organize your data.
In the Amazon S3 console, prefixes are called folders. You can view all your objects and folders in the S3 console by navigating to a bucket. You can also view information about each object, including object properties.
Storage Types
-
S3 Intelligent-Tiering storage is designed to optimize costs by automatically moving data to the most cost-effective access tier, without performance impact or operational overhead.
-
S3 Standard-IA is for data that is accessed less frequently but requires rapid access when needed. (high durability, high throughput, and low latency).
If you need to access objects frequently and you don't need a big thoughput, don't use standard-IA. Because it will cost you a lot of money.
Behaviour
Strongly consistent
All S3 GET, PUT, and LIST operations, as well as operations that change object tags, ACLs, or metadata, are strongly consistent. What you write is what you will read, and the results of a LIST will be an accurate reflection of what’s in the bucket.
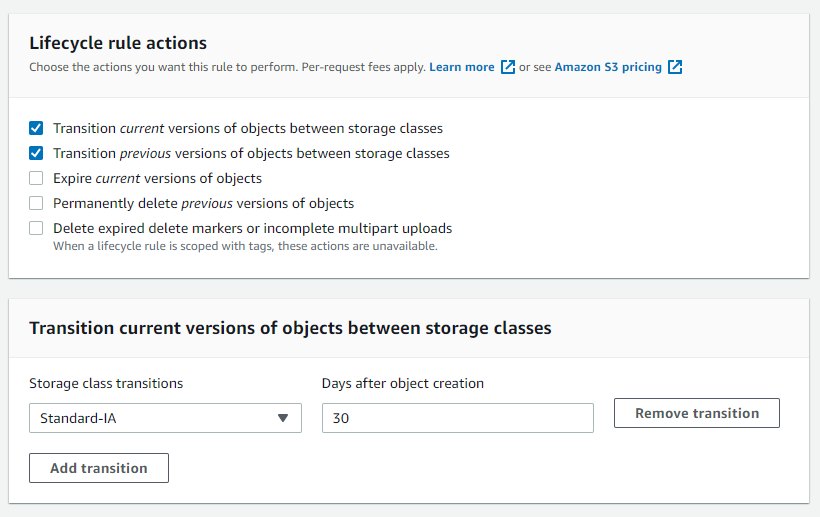
Lifecycle
You can add rules in an S3 Lifecycle configuration to tell Amazon S3 to transition objects to another Amazon S3 Using Amazon S3 storage classes.Amazon S3 supports a waterfall model for transitioning between storage classes, as shown in the following diagram.
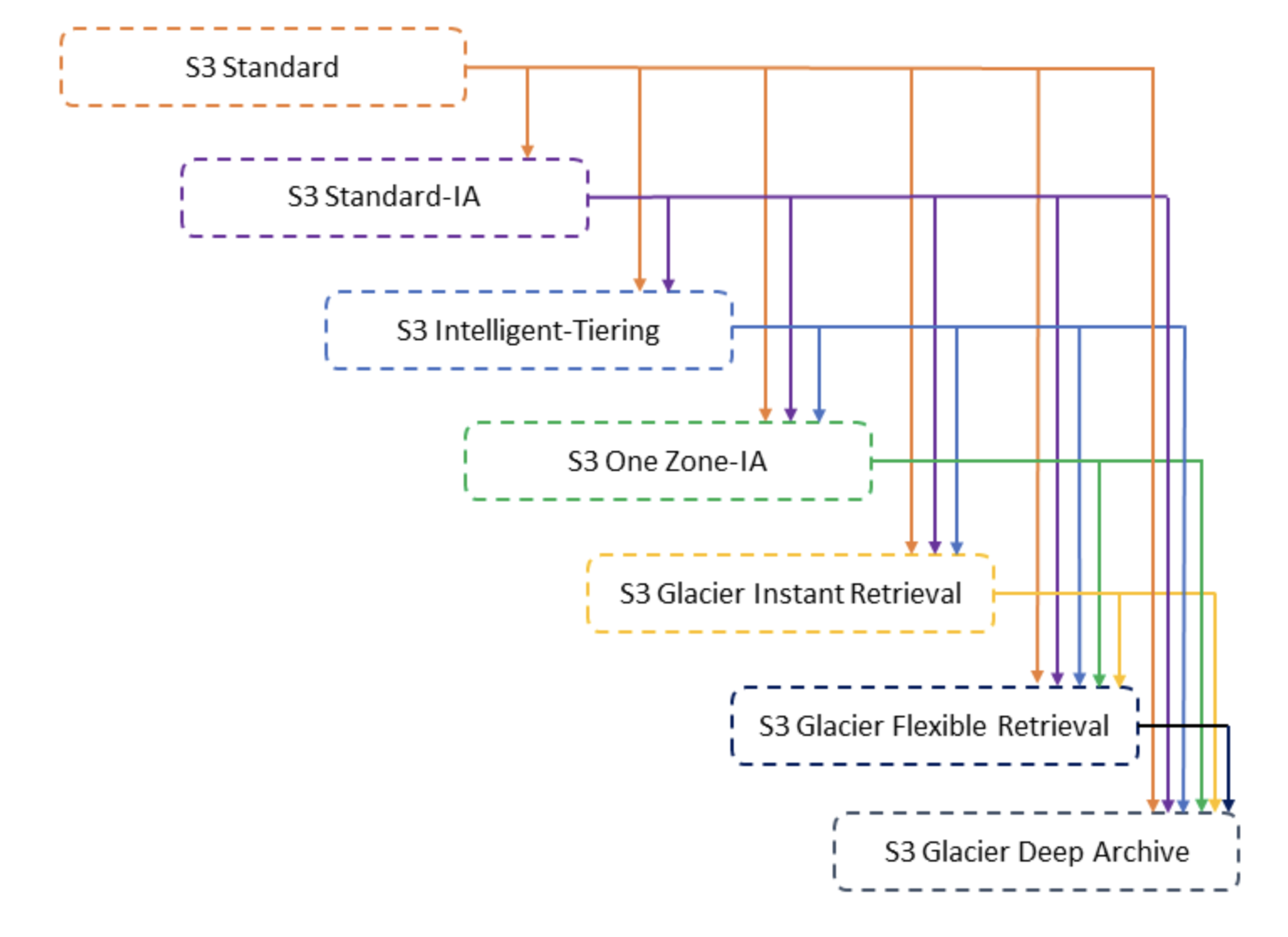 Source: Transitioning objects using Amazon S3 Lifecycle
Source: Transitioning objects using Amazon S3 Lifecycle
While Standard Infrequent Access and Standard offer the same durability (99.999999999%), One Zone IA does not. As its name implies, data is stored in a single Availability Zone, which means there is no cross-AZ data replication in the event of failure.
It isn't resilient to the physical loss of an Availability Zone resulting from disasters, such as earthquakes and floods. If the AZ is destroyed, so is your data.
Glacier
In Amazon S3 Glacier, an archive is any object, such as a photo, video, or document that you store in a vault. It is a base unit of storage in Glacier. Each archive has a unique ID and an optional description. When you upload an archive, Amazon S3 Glacier returns a response that includes an archive ID. This archive ID is unique in the region in which the archive is stored.
- Glacier Vault and Glacier Deep Archive Vault are one of the S3 storage classes.
- Glacier Vault provides S3 Glacier Vault Lock to prevent future changes for WORM compliance. (The setting format is like IAM policy)
- A vault lock policy is different than a vault access policy. Both policies govern access controls to your vault. However, a vault lock policy can be locked to prevent future changes, providing strong enforcement for your compliance controls. You can use the vault lock policy to deploy regulatory and compliance controls, which typically require tight controls on data access.
- In contrast, you use a vault access policy to implement access controls that are not compliance related, temporary, and subject to frequent modification. Vault lock and vault access policies can be used together.
- In Amazon S3 Glacier, you cannot assign a key name to the archives that you upload. The Lifecycle policies can then be used to transition the storage class of the object to Glacier, which will preserve the filename of your uploaded archive.
- You can retrieve 10 GB of your Amazon S3 Glacier data per month for free :::
Delete Bucket
Delete Bucket is Eventually consistent
If you delete a bucket and immediately list all buckets, the deleted bucket might still appear in the list - *Bucket configurations have an eventual consistency model *.
Condition of using CLI to delete bucket
You can delete a bucket that contains objects using the AWS CLI only if:
- The bucket doesn't have versioning enabled.
- The bucket is completely empty of objects and versioned objects.
If your bucket does not have versioning enabled, you can use the rb (remove bucket) AWS CLI command with the --force parameter to remove a non-empty bucket.
Tools
Inventory
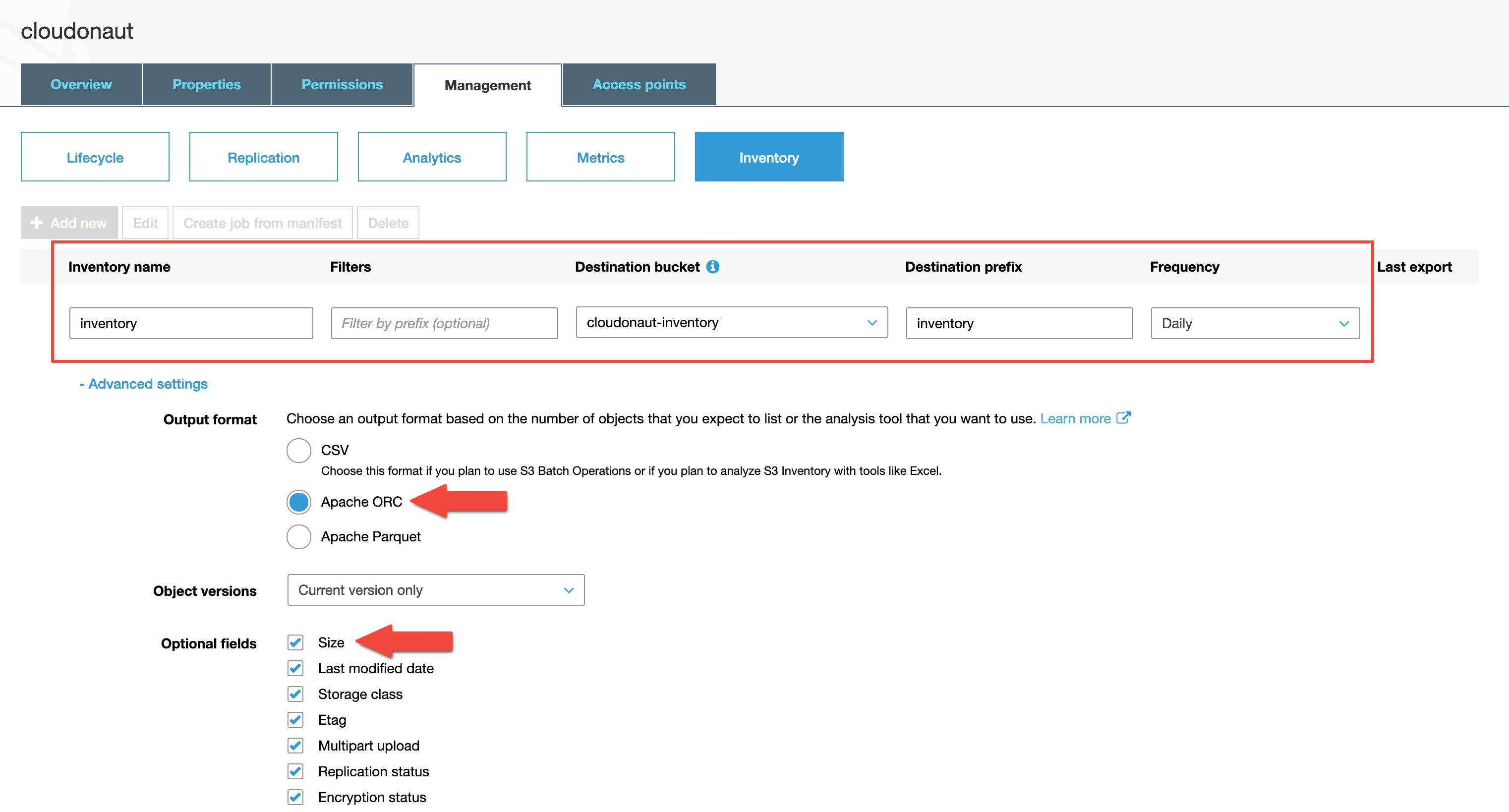
Amazon S3 Inventory helps manage storage by providing reports on object replication status and encryption status for business, compliance, and regulatory needs. It offers a scheduled alternative to S3 synchronous List API operations, simplifying and speeding up workflows and big data jobs without affecting bucket request rates.
Reports are generated in CSV, ORC, or Parquet format on a daily or weekly basis, depending on your preference, for an S3 bucket or objects with shared prefixes. Weekly reports are generated every Sunday (UTC time zone) after the initial report.
If you notice a significant increase in the number of HTTP 503-slow down responses received for Amazon S3 PUT or DELETE object requests to a bucket that has versioning enabled, you might have one or more objects in the bucket for which there are millions of versions.
When you have objects with millions of versions, Amazon S3 automatically throttles requests to the bucket to protect the customer from an excessive amount of request traffic, which could potentially impede other requests made to the same bucket.
To determine which S3 objects have millions of versions, use the Amazon S3 inventory tool. The inventory tool generates a report that provides a flat file list of the objects in a bucket.
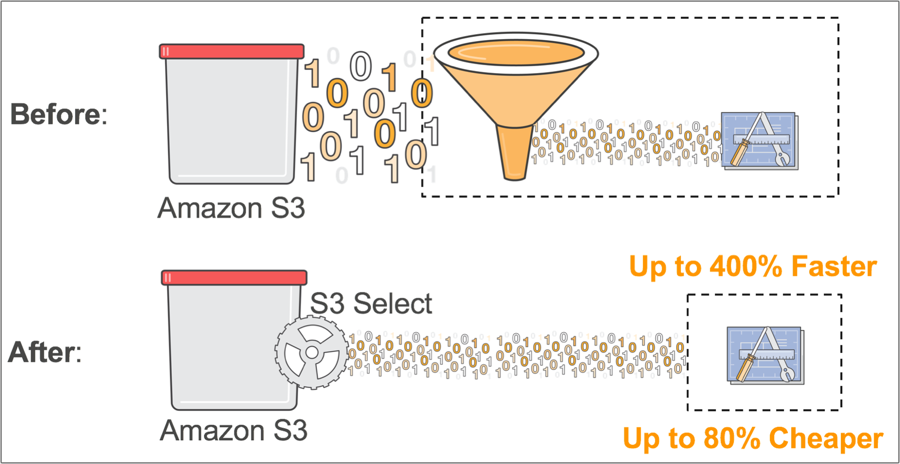
S3 Select
S3 Select, enables applications to retrieve only a subset of data from an object by using simple SQL expressions. By using S3 Select to retrieve only the data needed by your application, you can achieve drastic performance increases -- in many cases you can get as much as a 400% improvement.
As an example, let's imagine you're a developer at a large retailer and you need to analyze the weekly sales data from a single store, but the data for all 200 stores is saved in a new GZIP-ed CSV every day. Without S3 Select, you would need to download, decompress and process the entire CSV to get the data you needed. With S3 Select, you can use a simple SQL expression to return only the data from the store you're interested in, instead of retrieving the entire object. This means you're dealing with an order of magnitude less data which improves the performance of your underlying applications.
Let's look at a quick Python example, which shows how to retrieve the first column from an object containing data in CSV format.
import boto3
s3 = boto3.client('s3')
r = s3.select_object_content(
Bucket='jbarr-us-west-2',
Key='sample-data/airportCodes.csv',
ExpressionType='SQL',
Expression="select * from s3object s where s.\"Country (Name)\" like '%United States%'",
InputSerialization = {'CSV': {"FileHeaderInfo": "Use"}},
OutputSerialization = {'CSV': {}},
)
for event in r['Payload']:
if 'Records' in event:
records = event['Records']['Payload'].decode('utf-8')
print(records)
elif 'Stats' in event:
statsDetails = event['Stats']['Details']
print("Stats details bytesScanned: ")
print(statsDetails['BytesScanned'])
print("Stats details bytesProcessed: ")
print(statsDetails['BytesProcessed'])
We expect customers to use S3 Select to accelerate all sorts of applications. For example, this partial data retrieval ability is especially useful for serverless applications built with AWS Lambda. When we modified the Serverless MapReduce reference architecture to retrieve only the data needed using S3 Select we saw a 2X improvement in performance and an 80% reduction in cost.
Amazon Athena, Amazon Redshift, and Amazon EMR as well as partners like Cloudera, DataBricks, and Hortonworks will all support S3 Select.
Features
Object Lock
You can use S3 Object Lock to store objects using a write-once-read-many (WORM) model. Object Lock can help prevent objects from being deleted or overwritten for a fixed amount of time or indefinitely. You can use S3 Object Lock to meet regulatory requirements that require WORM storage, or add an extra layer of protection against object changes and deletion.
S3 Object Lock provides two retention modes:
- Governance mode
- In governance mode, users can’t overwrite or delete an object version or alter its lock settings unless they have special permissions. With governance mode, you protect objects against being deleted by most users, but you can still grant some users permission to alter the retention settings or delete the object if necessary. You can also use governance mode to test retention-period settings before creating a compliance-mode retention period.
- To override or remove governance-mode retention settings, a user must have the
s3:BypassGovernanceRetentionpermission and must explicitly includex-amz-bypass-governance-retention:trueas a request header with any request that requires overriding governance mode.
- Compliance mode
- In compliance mode, a protected object version can’t be overwritten or deleted by any user, including the root user in your AWS account. When an object is locked in compliance mode, its retention mode can’t be changed, and its retention period can’t be shortened. Compliance mode helps ensure that an object version can’t be overwritten or deleted for the duration of the retention period.
CORS
Cross-origin resource sharing (CORS) defines a way for client web applications that are loaded in one domain to interact with resources in a different domain. With CORS support, you can build rich client-side web applications with Amazon S3 and selectively allow cross-origin access to your Amazon S3 resources.
S3 encryption
You have three mutually exclusive options depending on how you choose to manage the encryption keys:
- SSE-KMS, you can..
- define access controls and audit the customer-managed CMK
- manage the lifecycle of the key material
- create, rotate, and disable customer-managed CMK
- SSE-S3, you can't do audit trail and lifecycle management
- SSE-C, You manage the encryption keys, and Amazon S3 manages the encryption.
S3 Access Points
TL;DR - An indepentent DNS access folder which you can use access poing policy to control permission, so that you don't need to create a complicated S3 bucket policy for multiple group of users.
Amazon S3 Access Points simplify data access management for shared datasets on S3. They provide unique hostnames with distinct permissions and network controls for each application, allowing easy scaling for hundreds of applications.
Access points can be restricted to VPCs to secure S3 data access within private networks. Each access point is associated with a single bucket and configured with specific access policies, providing granular control over data access. S3 Access Points are available in all regions at no extra cost and offer an auditable way to enforce VPC restrictions using AWS Service Control Policies(SCPs).
MFA-Delete
MFA-Delete represents another layer of security wherein you can configure a bucket to enable MFA-Delete, which requires additional authentication for either of the following operations:
- Change the versioning state of your bucket
- Permanently delete an object version
Before jump to the answer, you should know:
- Only the bucket owner (root account) can enable/suspend the MFA-Delete on the objects.
- However, both the bucket owner(root account) and all authorized IAM users can enable versioning.
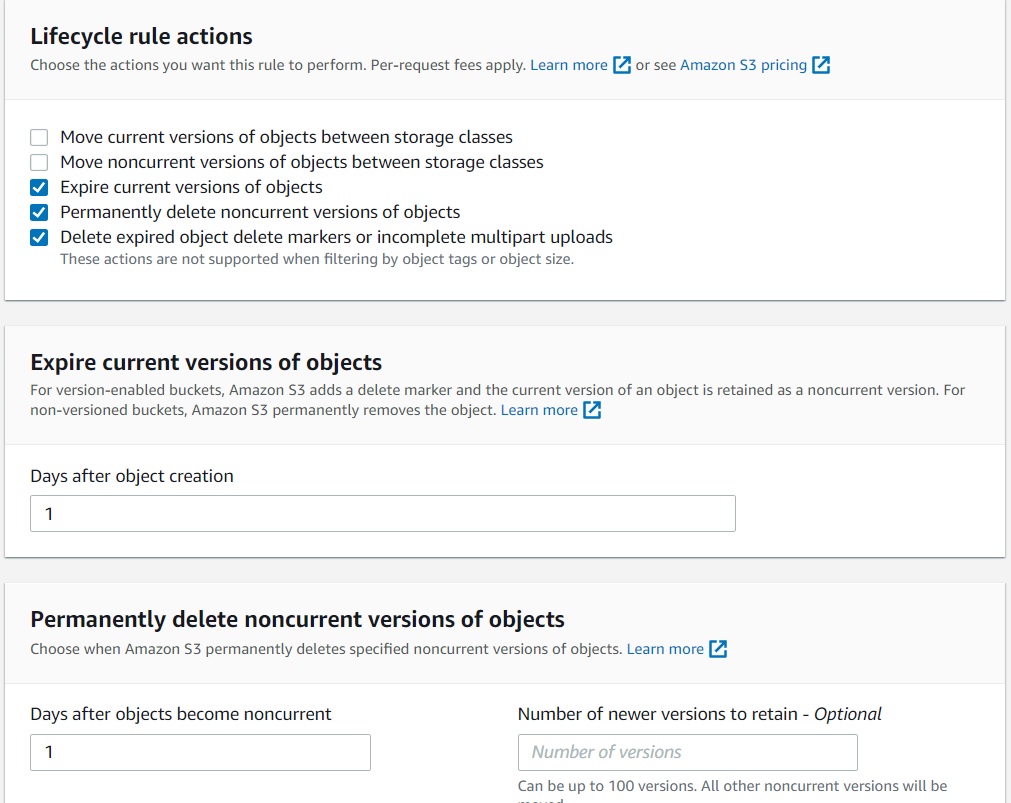
To simplify the deletion of both objects and versioned objects, you can set a lifecycle rule to remove all objects in a bucket one day after creation. If your bucket has versioning enabled, you can configure the rule to expire non-current objects.
Reference: Configuring MFA delete
Pre-signed URL max validation time
You create a pre-signed URL for your object, you must provide your security credentials, specify a bucket name, an object key, specify the HTTP method (GET to download the object) and expiration date and time. The pre-signed URLs are valid only for the specified duration.
The default pre-signed URL expiration time is 15 minutes and maximum valid up to 6 hours. Make sure to adjust this value to your specific needs. Security-wise, you should keep it to the minimum possible — eventually, it depends on your design.
Server access logging
Server access logging in Amazon S3 provides detailed records of requests made to a bucket, which can be valuable for security, access audits, understanding customer behavior, and monitoring costs. Enabling server access logging tracks access requests and generates logs with information such as requester, bucket name, request time, action, response status, and error codes.
- Enabling logging is free, but log files stored in the bucket incur storage charges.
- You can delete log files as needed, and subsequent access to log files incurs standard charges.
- Logging is disabled by default, and logs are stored in the same AWS Region as the source bucket.
Notification feature
AWS notification feature enables you to receive notifications when certain events happen in your bucket. Amazon S3 supports the following destinations where it can publish events:
- SNS topic
- Standard SQS queue (FIFO SQS queue is not allowed)
- AWS Lambda
- New object-created events
- Object removal events
- Restore object events
- Reduced Redundancy Storage (RRS) object lost events
- Replication events
If two writes are made to a single non-versioned object at the same time, it is possible that only a single event notification will be sent. If you want to ensure that an event notification is sent for every successful write, you can enable versioning on your bucket. With versioning, every successful write will create a new version of your object and will also send an event notification.
With versioning, you can easily recover from both unintended user actions and application failures. When you enable versioning for a bucket, if Amazon S3 receives multiple write requests for the same object simultaneously, it stores all of the objects.
Versioning-enabled buckets enable you to recover objects from accidental deletion or overwrite. For example:
- If you delete an object, instead of removing it permanently, Amazon S3 inserts a delete marker, which becomes the current object version. You can always restore the previous version.
- If you overwrite an object, it results in a new object version in the bucket. You can always restore the previous version.
Configure bucket as a static website
When you configure your bucket as a static website, the website is available at the AWS Region-specific website endpoint of the bucket.
Depending on your Region, your Amazon S3 website endpoints follow one of these two formats.
- s3-website dash (-) Region
- s3-website dot (.) Region
These URLs return the default index document that you configure for the website.
If your Amazon S3 bucket is configured as a website endpoint, you can't configure CloudFront to use HTTPS to communicate with your origin because Amazon S3 doesn't support HTTPS connections in that configuration.
When you configure an Amazon S3 bucket for website hosting, you must give the bucket the same name as the record that you want to use to route traffic to the bucket.
For example, to route traffic for "example.com" to an Amazon S3 bucket that's configured for website hosting, the bucket name must be "example.com".
Retention period
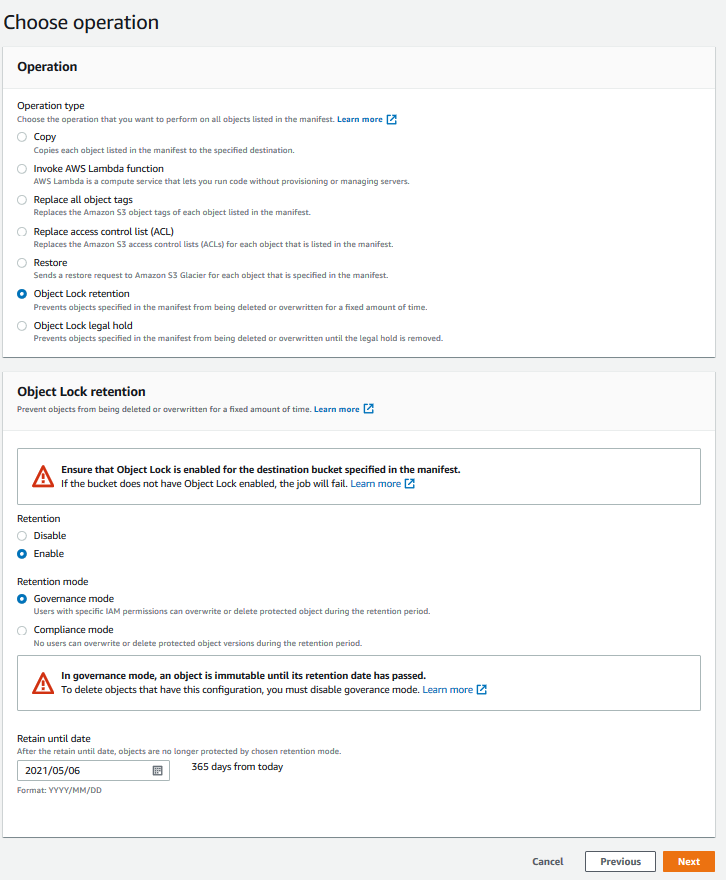
A retention period in AWS S3 protects an object version for a specific duration. It is set either explicitly with a Retain Until Date on an object version or through a bucket default setting. After the period expires, the object version can be overwritten or deleted, unless a legal hold is in place. Each object version can have its own retention mode and period, and you can extend the retention period by submitting a new lock request with a later date.
Performance
Byte-Range Fetches
Byte-Range Fetches is an option that allows you to read a file in the most efficient way. Using the Range HTTP header in a GET Object request, you can fetch a byte-range from an object, transferring only the specified portion. You can use concurrent connections to Amazon S3 to fetch different byte ranges from within the same object.
- This helps you achieve higher aggregate throughput versus a single whole-object request.
- Fetching smaller ranges of a large object also allows your application to improve retry times when requests are interrupted. For more information, see Getting Objects.
Typical sizes for byte-range requests are 8 MB or 16 MB. If objects are PUT using a multipart upload, it's a good practice to GET them in the same part sizes (or at least aligned to part boundaries) for best performance. GET requests can directly address individual parts; for example, GET ?partNumber=N.
You can implement byte-range fetches in 2 different ways Parallelize GETs and retrieve only partial data.
- Parallelize GETs
- Retrieve only partial data
It is to parallelize GETs by requesting a specific byte range. In case of failure, it has better resilience. Hence, it could be used to speed up downloads.

Source: Optimize Your AWS S3 Performance
The second use-case in which S3 Byte-Range Fetches could be used is to retrieve only partial data. For example, when you know the first XX bytes is the header of a file, in this case, it could be used.
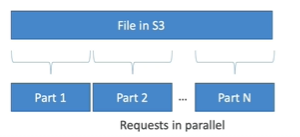
Source: Optimize Your AWS S3 Performance
# S3 Byte-Range Fetches via cURL
$ curl -r -1024 https://s3.amazonaws.com/mybucket/myobject -o parti
$ curl -r 1025- https://s3.amazonaws.com/mybucket/myobject -o part2
$ cat parti part2 > myobject
// S3 Byte-Range Fetches with AWS SDK
var s3 = new AWS.530);
var file = require('fs').createWriteStream('parti');
var params = {
Bucket: 'my bucket',
Key: 'myobject',
Range: 'bytes=-1024
};
s3.getObject(params).createReadStream().pipe(file);
Read Replicas
Amazon RDS Read Replicas provide enhanced performance and durability for RDS database (DB) instances. They make it easy to elastically scale out beyond the capacity constraints of a single DB instance for read-heavy database workloads. Read replicas can be within an Availability Zone, Cross-AZ, or Cross-Region.
When to use multipart uploading?
via - https://docs.aws.amazon.com/AmazonS3/latest/dev/UploadingObjects.html
In general, when your object size reaches 100 MB, you should consider using multipart uploads instead of uploading the object in a single operation.
- If you're uploading large objects over a stable high-bandwidth network, use multipart uploading to maximize the use of your available bandwidth by uploading object parts in parallel for multi-threaded performance.
- If you're uploading over a spotty network, use multipart uploading to increase resiliency to network errors by avoiding upload restarts.
Upload and download speed
There are 2 approaches to improve both upload and download speed across different regions. They're S3 Transfer Acceleration and Amazon CloudFront’s PUT/POST. According to AWS- General S3 FAQs, we should choose..
- If you have objects that are smaller than 1 GB or if the data set is less than 1 GB in size, you should consider using Amazon CloudFront's PUT/POST commands for optimal performance.
- S3 Transfer Acceleration optimizes the TCP protocol and adds additional intelligence between the client and the S3 bucket, making it a better choice if a higher throughput is desired..
In terms of AWS pricing, you will be charged for "Regional Data Transfer Out to Origin" (0.16/GB depending on region) compared with S3 Transfer Acceleration charges (0.08/GB depending on region.)
- S3 Transfer Acceleration
- CloudFront distribution
Amazon S3 transfer acceleration uses Cloudfront under the scene. As the data arrives at an edge location, data is routed to Amazon S3 over an optimized network path.
Amazon S3 Transfer Acceleration can speed up content transfers to and from Amazon S3 by as much as 50-500% for long-distance transfer of larger objects. Transfer Acceleration takes advantage of Amazon CloudFront’s globally distributed edge locations. As the data arrives at an edge location, data is routed to Amazon S3 over an optimized network path.
Plain English - When an object from S3 that is set up with CloudFront CDN is requested, the request would come through the Edge Location transfer paths only for the first request. Thereafter, it would be served from the nearest edge location to the users until it expires. So in this way, you can speed up uploads as well as downloads for the video files.
Use Amazon CloudFront distribution with origin as the S3 bucket to ingest S3 file uploads.
- Upload -
PUTandPOSToperations will be sent to the origin(e.g. Amazon S3). For a deep-dive reference, visit AWS document - Download - When an object from S3 that is set up with CloudFront CDN is requested, the request would come through the Edge Location transfer paths only for the first request. Thereafter, it would be served from the nearest edge location to the users until it expires.
Belows are the high level steps to create a cloudfront distribution. To check the detailed steps, visit StackOverflow - Uploads to S3 through CloudFront via Signed URLs?
- Create a new CF distribution
- Use target S3 bucket as origin
- Configure origin S3 bucket access to use a CloudFront origin access identity (OAI). While you can automatically update the bucket policy (with
s3:GetObjectaccess) as a starting point, we'll be adding/changing that tos3:PutObjectanyway.
- Configure S3 bucket policy
- Upload files to S3 using the CloudFront distribution
Once the distribution is updated, you would be able to add files to your bucket by making a PUT request to https://your-distribution-url/desired-s3-key-name using Postman or something. Remember to use a signed url here if that's what you've configured.
Your client connections to the CF edge should be consistently faster, while anecdotally S3 acceleration speed comparison isn't always favorable.
Security
Bucket owner
- As a bucket owner, how to give permissions on all objects created by AWS account A to another AWS account B?
- The bucket owner has no permissions on those objects created by other AWS accounts
- The AWS account that created the objects must first grant permission to the bucket owner for delegating permissions to other entities
Root user access
If an IAM user, with full access to IAM and Amazon S3, assigns a bucket policy to an Amazon S3 bucket and doesn't specify the AWS account root user as a principal, the root user is denied access to that bucket
However, as the root user, you can still access the bucket. To do that, modify the bucket policy to allow root user access from the Amazon S3 console or the AWS CLI. Use the following principal, replacing 123456789012 with the ID of the AWS account."Principal": { "AWS": "arn:aws:iam::123456789012:root" }
User Policy example
Q: Imagine there is an organization has multiple AWS accounts to manage different lines of business. A user from the Finance account has to access reports stored in Amazon S3 buckets of two other AWS accounts (belonging to the HR and Audit departments) and copy these reports back to the S3 bucket in the Finance account. How will you set up the identity-based IAM policies and ** resource-based** policies?
A: Create identity-based IAM policy in the Finance account that allows the user to make a request to the S3 buckets in the HR and Audit accounts. Also, create resource-based IAM policies in the HR, Audit accounts that will allow the requester from the Finance account to access the respective S3 buckets
User policies vs ACL vs Bucket Policies

Source: Background: Amazon S3 Access Control Tools
- User Policies: Use the AWS IAM policy syntax to grant access to IAM users in your account.
- Resource-based policies are policies that you can attach to your resources (buckets and objects)
- Bucket Policies: Use the AWS IAM policy syntax to manage access for a particular S3 bucket and the objects in it; (A bucket policy is a resource-based policy - Unlike an identity-based policy, a resource-based policy specifies who (which principal) can access that resource.)
- Access Control Lists (ACLs): It enables you to manage access to buckets and objects. Each bucket and object has an ACL attached to it as a subresource.
- User Policies
- ACL
- BucketPolicies
User policies are attached to a particular IAM user to indicate whether that user can access various S3 buckets and objects.
In contrast, bucket policies and ACLs are attached to the resource itself either an S3 bucket or an S3 object to control access.
IAM roles and resource-based policies delegate access across accounts only within a single partition. For example, you can't add cross-account access between an account in the standard aws partition and an account in the aws-cn partition. (reference)
Diagram to show S3 Access Polices (Bucket and Object)
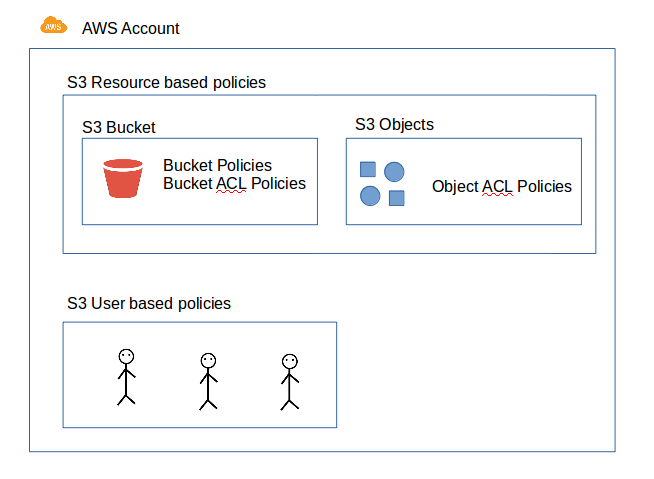
Source: Sample S3 Bucket Policies — Part 01
ACL in AWS console
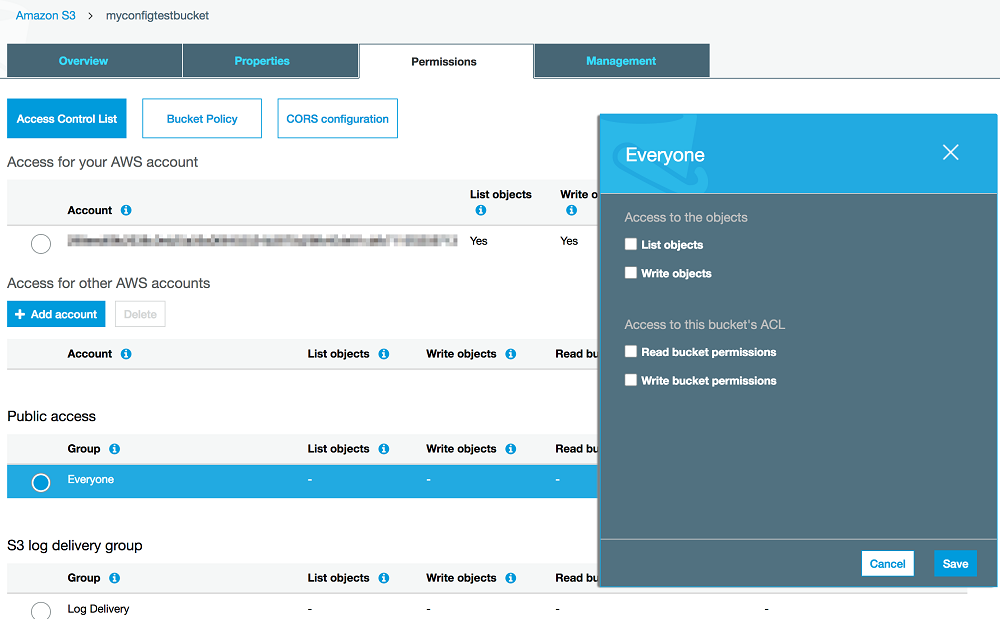
Source: An easier way to control access to aws resources by using the aws organization of iam principals
The below table is the set of ACL permissions is the same for an object ACL and a bucket ACL. The important one are WRITE_ACP and READ_ACP to control whether the grantee can read/create ACL or not Ref:What permissions can I grant?
ACL permissions | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Permission | When granted on a bucket | When granted on an object | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
READ | Allows grantee to list the objects in the bucket | Allows grantee to read the object data and its metadata | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
WRITE | Allows grantee to create new objects in the bucket. For the bucket and object owners of existing objects, also allows deletions and overwrites of those objects | Not applicable | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
READ_ACP | Allows grantee to read the bucket ACL | Allows grantee to read the object ACL | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
WRITE_ACP | Allows grantee to write the ACL for the applicable bucket | Allows grantee to write the ACL for the applicable object | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
FULL_CONTROL | Allows grantee the READ, WRITE, READ_ACP, and
WRITE_ACP permissions on the bucket | Allows grantee the READ, READ_ACP, and
WRITE_ACP permissions on the object | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
When creating an IAM policy for S3 uploads, you need to include specific permissions. Here are the essential ones:
s3:PutObject: This permission allows an IAM user to upload objects to a specified S3 bucket.s3:PutObjectAcl: This permission allows the user to modify the Access Control List (ACL) of an object. It’s necessary if you want to control who can access the uploaded objects.s3:ListBucket: This permission is required to list the objects in a bucket. It’s necessary for users to see what’s already in the bucket before uploading new objects.
The following example policy grants the s3:PutObject and s3:PutObjectAcl permissions to multiple AWS accounts and requires that any request for these operations include the public-read canned access control list (ACL). For more information, see Amazon S3 actions and Amazon S3 condition key examples.
Example Bucket policy
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AddCannedAcl",
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::111122223333:root",
"arn:aws:iam::444455556666:root"
]
},
"Action": [
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": "arn:aws:s3:::DOC-EXAMPLE-BUCKET/*",
"Condition": {
"StringEquals": {
"s3:x-amz-acl": [
"public-read"
]
}
}
}
]
}
Resources for corresponding actions
In this bucket policy, if you don't have either arn:aws:s3:::tutorialsdojo/* for s3:GetObject or arn:aws:s3:::tutorialsdojo for s3:ListBucket, you will be prompted with an "Action does not apply to any resource(s) in statement" error if you tried to apply this bucket policy.
{
"Id": "TutorialsDojo.com S3 Policy",
"Version": "2012-10-17",
"Statement": [
{
"Sid": "TutsDojo_S3_GetObject_and_ListBucket_Policy",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::tutorialsdojo/*",
"arn:aws:s3:::tutorialsdojo",
]
"Principal": "*"
}
]
}
HTTPS for encryption
Among all 4 encryption types, only SSE-C requires all the requests need to through HTTPS.
- SSE-C - Amazon S3 will reject any requests made over HTTP.
- SSE-KMS - It is not mandatory to use HTTPS.
- Client-Side Encryption - Client-side encryption is the act of encrypting data before sending it to Amazon S3. It is not mandatory to use HTTPS for this.
- SSE-S3 - It is not mandatory to use HTTPS. Amazon S3 encrypts your data at the object level as it writes it to disks in its data centers.
Force encryption in bucket policy
Reference: Amazon S3 now automatically encrypts all new objects
Amazon S3 now applies server-side encryption with Amazon S3 managed keys (SSE-S3) as the base level of encryption for every bucket in Amazon S3. Starting January 5, 2023, all new object uploads to Amazon S3 are automatically encrypted at no additional cost and with no impact on performance.
All Amazon S3 buckets have encryption configured by default, and all new objects that are uploaded to an S3 bucket are automatically encrypted at rest. Server-side encryption with Amazon S3 managed keys (SSE-S3) is the default encryption configuration for every bucket in Amazon S3. To use a different type of encryption, you can either specify the type of server-side encryption to use in your S3 PUT requests, or you can set the default encryption configuration in the destination bucket.
If you want to specify a different encryption type in your PUT requests, you can use server-side encryption with AWS Key Management Service (AWS KMS) keys (SSE-KMS), dual-layer server-side encryption with AWS KMS keys (DSSE-KMS), or server-side encryption with customer-provided keys (SSE-C). If you want to set a different default encryption configuration in the destination bucket, you can use SSE-KMS or DSSE-KMS.
When using server-side encryption with customer-provided encryption keys (SSE-C), you must provide encryption key information using the following request headers:
x-amz-server-side-encryption-customer-algorithm: This header value must be "AES256".x-amz-server-side-encryption-customer-keyuse this header to provide the 256-bit, base64-encoded encryption key for Amazon S3 to use to encrypt or decrypt your data.x-amz-server-side-encryption-customer-key-MD5use this header to provide the base64-encoded 128-bit MD5 digest of the encryption key according to RFC 1321. Amazon S3 uses this header for a message integrity check to ensure the encryption key was transmitted without error.
In order to ensure that all objects uploaded to a S3 bucket are encrypted, you can configure the bucket policy to deny if the PutObject does not have an x-amz-server-side-encryption header set via HTTP.
'x-amz-server-side-encryption': 'AES256'AES256 equals SSE-S3- Amazon S3 server-side encryption uses one of the strongest block ciphers available to encrypt your data, 256-bit Advanced Encryption Standard (AES-256).
'x-amz-server-side-encryption': 'aws:kms'- Amazon S3 uses AWS KMS customer master keys (CMKs) to encrypt your Amazon S3 objects. AWS KMS encrypts only the object data. Any object metadata is not encrypted. You can use if you need more control over your keys like create, rotating, disabling them using AWS KMS. Otherwise, if you wish to let AWS S3 manage your keys just stick with SSE-S3.
If you need server-side encryption for all of the objects that are stored in a bucket, use a bucket policy. For example, the following bucket policy denies permissions to upload an object unless the request includes the x-amz-server-side-encryption header to request server-side encryption:
{
"Version": "2012-10-17",
"Id": "PutObjectPolicy",
"Statement": [
{
"Sid": "DenyIncorrectEncryptionHeader",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::awsexamplebucket1/*",
"Condition": {
"StringNotEquals": {
"s3:x-amz-server-side-encryption": "AES256"
}
}
},
{
"Sid": "DenyUnencryptedObjectUploads",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::awsexamplebucket1/*",
"Condition": {
"Null": {
"s3:x-amz-server-side-encryption": "true"
}
}
}
]
}
AWS document: Protecting data using server-side encryption
Client Side Encryption
If you have a proprietary encryption algorithm to do the encryption, you have to leverage client-side encryption. To enable client-side encryption, you have the following options:
- Use a customer master key (CMK) stored in AWS Key Management Service (AWS KMS).
- Use a master key you store within your application.
Generate CloudFron URL by Lambda
In general, if you’re using an Amazon S3 bucket as the origin for a CloudFront distribution, you can either
- allow everyone to have access to the files there
- or you can restrict access.
If you restrict access by using, for example, CloudFront signed URLs or signed cookies, you also won’t want people to be able to view files by simply using the direct Amazon S3 URL for the file. Instead, *you want them to only access the files by using the CloudFront URL *, so your content remains protected.
Restricting only CloudFront access
Use an Origin Access Identity (OAI) in AWS S3 when you want to securely deliver private content stored in an S3 bucket through a CloudFront distribution. OAI restricts direct access to S3 objects while allowing controlled distribution via CloudFront edge locations, enhancing performance and security for delivering sensitive or restricted content to users.
If you use an Amazon S3 bucket configured as a website endpoint, you must set it up with CloudFront as a custom origin. That means you can't use OAC (or OAI). However, you can restrict access to a custom origin by setting up custom headers and configuring the origin to require them. For more information, see Restricting access to files on custom origins.
CloudFront provides two ways to send authenticated requests to an Amazon S3 origin: origin access control (OAC) and origin access identity (OAI). We recommend using OAC because it supports:
- All Amazon S3 buckets in all AWS Regions, including opt-in Regions launched after December 2022
- Amazon S3 server-side encryption with AWS KMS (SSE-KMS)
- Dynamic requests (
PUTandDELETE) to Amazon S3
Reference: Restricting access to an Amazon S3 origin
Availabiltiy
Multi-AZ
Multi-AZ for the RDS database helps make our database highly-available, but the standby database is not accessible and cannot be used for reads or write. It's just a database that will become primary when the other database encounters a failure.
Limitation
Request per sec
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. Your applications can easily achieve thousands of transactions per second in request performance when uploading and retrieving storage from Amazon S3. Amazon S3 automatically scales to high request rates.
For example, your application can achieve at least 3,500 PUT/COPY/POST/DELETE or 5,500 GET requests per second per prefix in a bucket.
There are no limits to the number of prefixes in a bucket. You can increase your read or write performance by parallelizing reads. For example, if you create 10 prefixes in an Amazon S3 bucket to parallelize reads, you could scale your read performance to 55,000 read requests per second(10*5,500 GET/HEAD).
For many purposes, it's often enough for applications to mitigate 503 SlowDown errors without having to randomize prefixes.
However, if the the limits are not sufficient, prefixes would need to be used. A prefix has no fixed number of characters. It is any string between a bucket name and an object name, for example:
- bucket/folder1/sub1/file
- bucket/folder1/sub2/file
- bucket/1/file
- bucket/2/file
Prefixes of the object 'file' would be: /folder1/sub1/ , /folder1/sub2/, /1/, /2/. In this example, if you spread reads across all four prefixes evenly, you can achieve 22,000 requests per second.
Snowball
AWS Snowball is a physical data transfer device offered by Amazon Web Services (AWS) that simplifies the process of moving large volumes of data between on-premises locations and the AWS cloud. It is designed to overcome challenges related to network limitations, long transfer times, and high costs associated with transferring large amounts of data over the internet.
*You can't move data directly from Snowball into a Glacier Vault or a Glacier Deep Archive Vault *. You need to go through S3 first and then use a lifecycle policy.
AWS OpsHub presents all Snowball API as a graphical user interface. This interface helps you quickly migrate data to the AWS Cloud and deploy edge computing applications on Snow Family Devices.
When your Snow device arrives at your site, you download, install, and launch the AWS OpsHub application on a client machine, such as a laptop. After installation, you can unlock the device and start managing it and using supported AWS services locally.