High Performance Computing
Background
High Performance Computing (HPC) clusters are created to provide extreme computational power to large scale applications. This computational power often results in the creation of very large amounts of data as well as very large individual files. For quite some time, the speed of processors and memory have risen sharply, but the performance of I/O systems has lagged behind.
While processors and memory have improved in cost/performance exponentially over the last 20 years, disk drives still essentially spin at the same speeds, and drive access times are still measured in numbers of milliseconds. As such, poor I/O performance can severely degrade the overall performance of even the fastest clusters. This is especially true of today's multi-petabyte clusters.
The Lustre file system is a parallel file system used in a wide range of HPC environments, small to large, such as AI/ML, oil and gas, seismic processing, the movie industry, and scientific research to address a common problem they all have and that is the ever increasing large amounts of data being created and needing to be processed in a timely manner. In fact it is the most widely used file system by the world's Top 500 HPC sites.
With Lustre in use it's common to see end-to-end data throughput over 100GigE networks in excess of 10 GB/sec and InfiniBand EDR links reach bandwidths up to 10 GB/sec. Lustre can scale to tens of thousands of clients. At Oak Ridge National Laboratory their production file system, Spider, runs Lustre with over 25,000 clients, over 20PB of storage, and achieves a peak aggregate IO throughput of 2TB/sec.
This page addresses the many advantages that the Lustre file system offers to High Performance Computing clusters and how Lustre, a parallel file system, improves the overall scalability and performance of HPC clusters.
HPC Building blocks
When designing a High Performance Computing (HPC) cluster, the HPC architect has three common file system options for providing access to the storage hardware. Perhaps the most common is the Network File System (NFS). NFS is a standard component in cloud computing environments. NFS is commonly included in what is known as a NAS, or Network Attached Storage architectures. A second option available to choose is SAN file systems, or Storage Area Network file systems. And last, but not least, are parallel file systems. Lustre is the most widely used file system on the top 500 fastest computers in the world. Lustre is the file system of choice on 7 out of the top 10 fastest computers in the world today, over 70% of the top 100, and also for over 60% of the top 500. This paper describes why Lustre dominates the top 500 (www.top500.org) and why you would use it for your high performance IO requirements.
NFS (Network File System)
NFS has been around for over 20 years, is very stable, easy to use and most systems administrators, as well as users, are generally familiar with its strengths and weaknesses. In low end HPC storage environments, NFS can still be a very effective medium for distributing data, where low end HPC storage systems are defined as capacity under 100TB and high end generally above 1PB. However, for high end HPC clusters, the NFS server can quickly become a major bottleneck as it does not scale well when used in large cluster environments. The NFS server also becomes a single point of failure, for which the consequences of it crashing can become severe.
SAN (Storage Area Networks)
SAN file systems are capable of very high performance, but are extremely expensive to scale up since they are implemented using Fibre Channel and therefore, each node that connects to the SAN must have a Fibre Channel card to connect to the Fibre channel switch.
Lustre (a Distributed Parallel File System)
The main advantage of Lustre, a global parallel file system, over NFS and SAN file systems is that it provides; wide scalability, both in performance and storage capacity; a global name space, and the ability to distribute very large files across many nodes. Because large files are shared across many nodes in the typical cluster environment, a parallel file system, such as Lustre, is ideal for high end HPC cluster I/O systems. This is why it is in such widespread use today, and why at Whamcloud we have an organization of Lustre engineers dedicated to its support, service, and continued feature enhancements.
Amazon FSx
Multi-AZ deployment
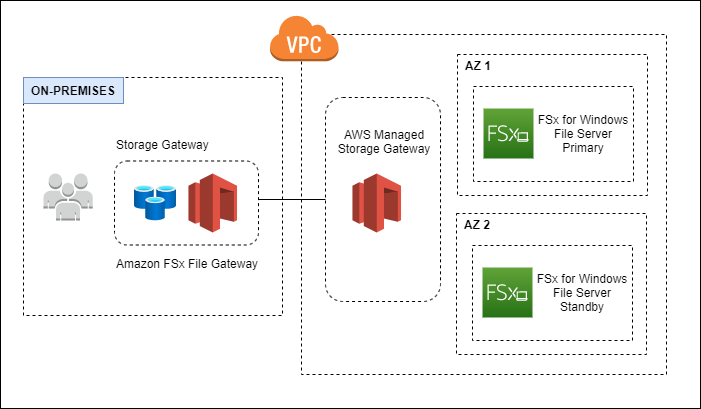
In a Multi-AZ deployment, Amazon FSx automatically provisions and maintains a standby file server in a different Availability Zone. Any changes written to disk in your file system are synchronously replicated across Availability Zones to the standby. With Amazon FSx, Multi-AZ deployments can enhance availability during planned system maintenance, and help protect your data against instance failure and Availability Zone disruption. If there is planned file system maintenance or unplanned service disruption, Amazon FSx automatically fails over to the secondary file server, allowing you to continue accessing your data without manual intervention.
For Lustre(Linux)
 Source: AWS - Offical document
Source: AWS - Offical document
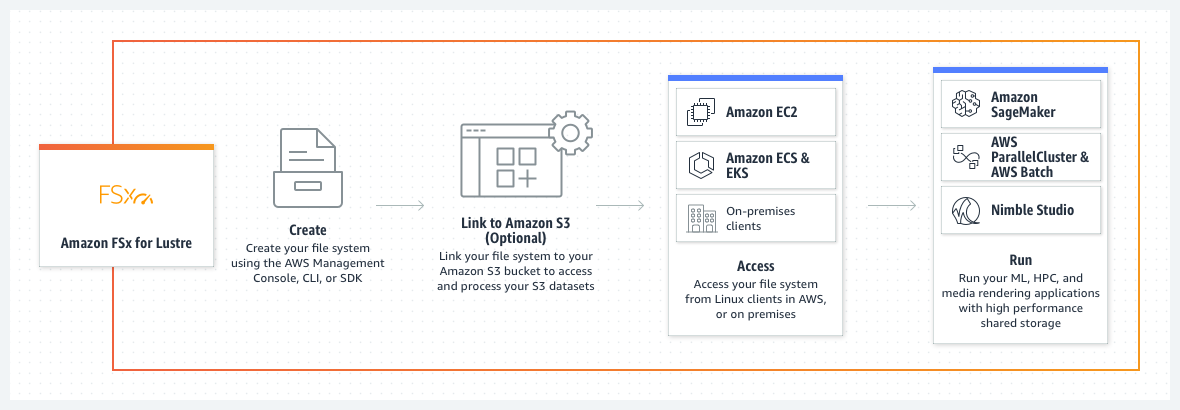
Amazon FSx for Lustre makes it easy and cost-effective to launch and run the world’s most popular high-performance file system. It is used for workloads such as machine learning, high-performance computing (HPC), video processing, and financial modeling. The open-source Lustre file system is designed for applications that require fast storage – where you want your storage to keep up with your compute.
FSx for Lustre integrates with Amazon S3, making it easy to process data sets with the Lustre file system. When linked to an S3 bucket, an FSx for Lustre file system transparently presents S3 objects as files and allows you to write changed data back to S3.
FSx for Lustre provides the ability to both process the 'hot data' in a parallel and distributed fashion as well as easily store the 'cold data' on Amazon S3. Therefore this option is the BEST fit for the given problem statement.
For Windows File Server
 Source: AWS - Offical document
Source: AWS - Offical document
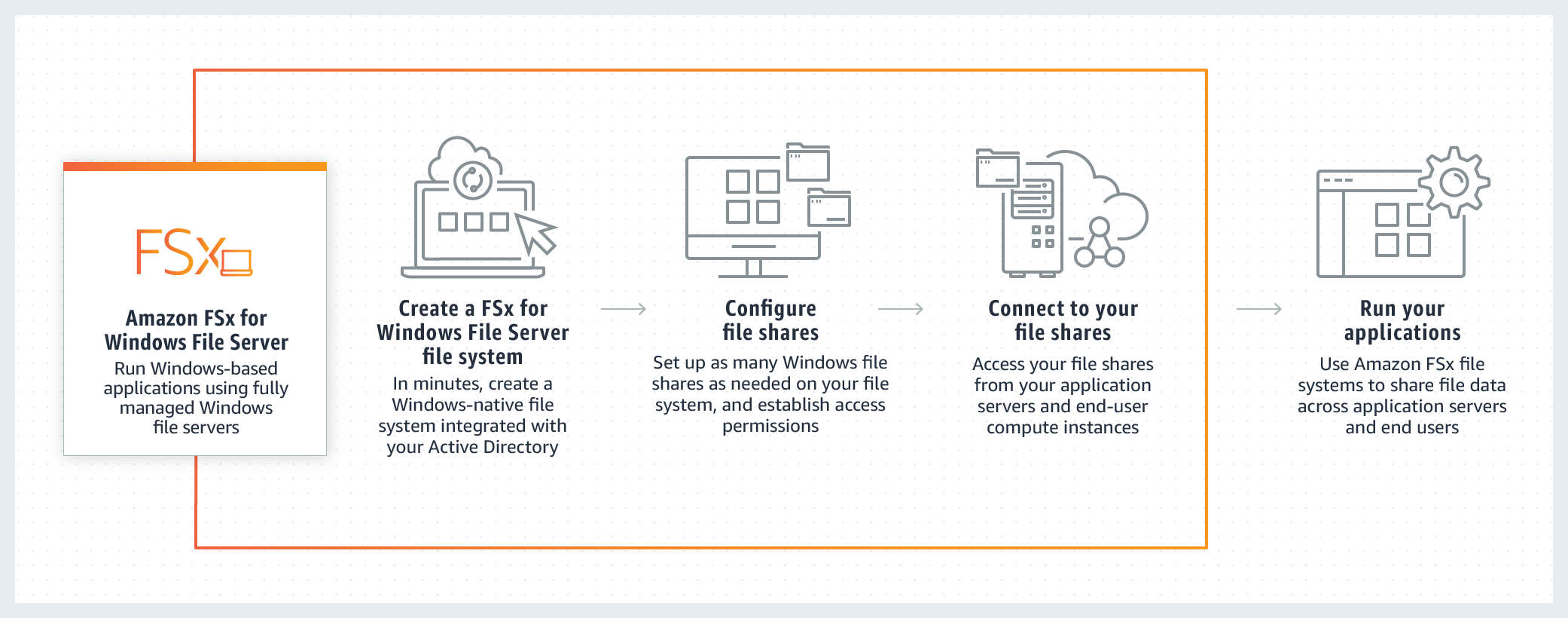
Amazon FSx for Windows File Server provides fully managed, highly reliable file storage that is accessible over the industry-standard Service Message Block (SMB) protocol. It is built on Windows Server, delivering a wide range of administrative features such as user quotas, end-user file restore, and Microsoft Active Directory (AD) integration. Amazon FSx supports the use of Microsoft’s Distributed File System (DFS) to organize shares into a single folder structure up to hundreds of PB in size.
FSx for Windows does not allow you to present S3 objects as files and does not allow you to write changed data back to S3. Therefore you cannot reference the "cold data" with quick access for reads and updates at low cost.