Reverse Proxy
TL;DR - Load balancers are most commonly deployed when a site needs multiple servers because the volume of requests is too much for a single server to handle efficiently. Whereas deploying a load balancer makes sense only when you have multiple servers, it often makes sense to deploy a reverse proxy even with just one web server or application server.

Source: What is a reverse proxy?
A proxy server is a go‑between or intermediary server that forwards requests for content from multiple clients to different servers across the Internet. A reverse proxy server is a type of proxy server that typically sits behind the firewall in a private network and directs client requests to the appropriate backend server. A reverse proxy provides an additional level of abstraction and control to ensure the smooth flow of network traffic between clients and servers. The benefits are two-fold:
- Web acceleration – Reverse proxies can compress inbound and outbound data, as well as cache commonly requested content, both of which speed up the flow of traffic between clients and servers. They can also perform additional tasks such as SSL encryption to take load off of your web servers, thereby boosting their performance.
- Security and anonymity – Because clients see only the reverse proxy’s IP address, you are free to change the configuration of your backend infrastructure. It also ensures that multiple servers can be accessed from a single record locator or URL regardless of the structure of your local area network.
What’s a proxy and the difference between the forward & reverse proxy?

Source: What is a reverse proxy?
TL;DR - To summarise, the forward proxy hides the clients whereas a reverse proxy hides the servers.
A simple definition for “proxy” means that data is passing through a third party, before reaching to the actual location. Forward or regular proxies are servers that encapsulate the original identity of the requestor i.e., users stay anonymous to the host server.
Reserve proxy is important in Microservice architectures
To read to rest of this article, please go to AWS: Serving Content Using a Fully Managed Reverse Proxy Architecture in AWS
With the trends to autonomous teams and microservice style architectures, web frontend tiers are challenged to become more flexible and integrate different components with independent architectures and technology stacks. Two scenarios are prominent:
- Micro-Frontends, where there is a single page application and components within this page are owned by different teams
- Web portals, where there is a landing page and subsections of the presence are owned by different teams. In the following we will refer to these as components as well.
What these scenarios have in common is that they consist of loosely coupled components that are seamlessly hidden to the end user behind a common interface. Often, a reverse proxy serves content from one single entry domain but retrieves the content from different origins. In the example in Figure 1 (below) we want to address one specific domain name, and depending on the path prefix, we retrieve the content from an on-premises webserver, from a webserver running on Amazon Elastic Cloud Compute (EC2), or from Amazon S3 Static Hosting, in the figure represented by the prefixes /hotels, /pets, and /cars, respectively.
If we forward the path to the webserver without the path prefix, the component would not know what prefix it is run under and the prefix could be changed any time without impacting the component, thus making the component context-unaware.
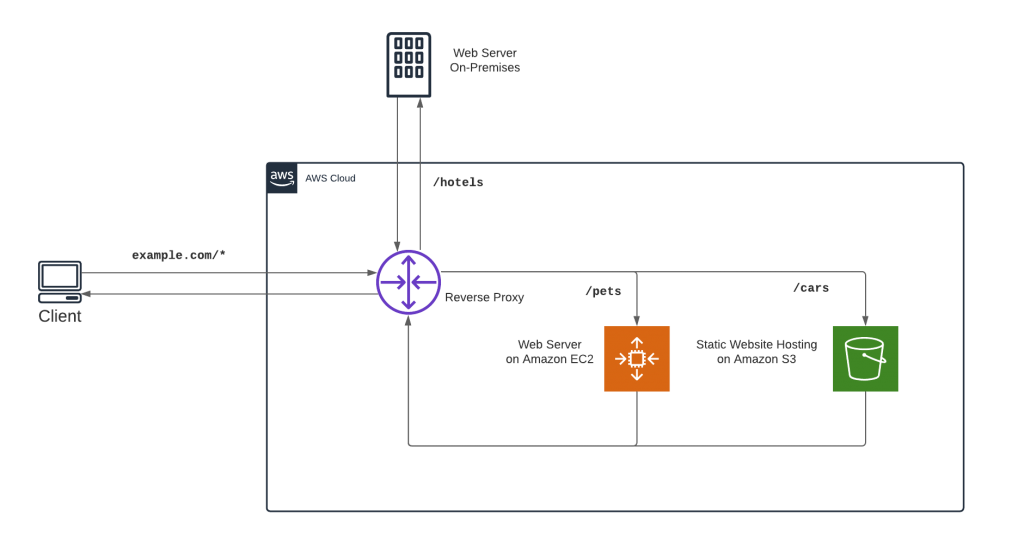 Source: Architecture, AWS Amplify Console
Source: Architecture, AWS Amplify Console
Some common requirements to these approaches are:
- Components should be technology-agnostic, each component should be able to choose the technology stack independently.
- Each component can be maintained by a dedicated autonomous team without depending on other teams.
- All components are served from the same domain name. For example, this could have implications on search engine optimization.
- Components should be unaware of the context where it is used.
The traditional approach would be to run a reverse proxy tier with rewrite rules to different origins. In this post we look into managed alternatives in AWS that take away the heavy lifting of running and scaling the proxy infrastructure.
Note: AWS Application Load Balancer can be used as a reverse proxy, but it only supports static targets (fixed IP address), no dynamic targets (domain name). Thus, we do not consider it here.
Conclusion
In the above link, you should know with AWS Amplify Console, Amazon API Gateway, and Amazon CloudFront with Lambda@Edge, there are three approaches to implement a reverse proxy pattern using managed services from AWS. The easiest approach to start with is AWS Amplify Console. If you run into more complex scenarios consider API Gateway. For most flexibility and when data traffic cost becomes a factor look into Amazon CloudFront with Lambda@Edge.