Redshift
Amazon Redshift
Redshift is a full-fledged data warehouse that is very efficient in storing raw data and collecting data from various different sources. It is based on PostgreSQL version 8.0.2. This means that you can use regular SQL queries with Redshift.
The main benefit of using AWS Redshift is the cost-benefit to your business. The cost is one-fifth (about one-twentieth) of competitors such as Teradata and Oracle.
Amazon Redshift Spectrum
TL;DR - Using Amazon Redshift Spectrum, you can efficiently query and retrieve structured and semistructured data from files in Amazon S3 without having to load the data into Amazon Redshift tables.
Amazon Redshift Spectrum is a feature within Amazon Web Services' Redshift data warehousing service that lets a data analyst conduct fast, complex analysis on objects stored on the AWS cloud.
With Redshift Spectrum, an analyst can perform SQL queries on data stored in Amazon S3 buckets. This can save time and money because it eliminates the need to move data from a storage service to a database, and instead directly queries data inside an S3 bucket. Redshift Spectrum also expands the scope of a given query because it extends beyond a user's existing Redshift data warehouse nodes and into large volumes of unstructured S3 data lakes.
How Redshift Spectrum works
While Amazon Redshift handles “analytical workloads,” Spectrum is the “bridge” layer that provides Redshift an interface to S3 data. Redshift Spectrum must have a Redshift cluster and a connected SQL client. Multiple clusters can access the same S3 data set at the same time, but queries can only be conducted on data stored in the same AWS region.
Redshift Spectrum can be used in conjunction with any other AWS compute service with direct S3 access, including Amazon Athena, as well as Amazon Elastic Map Reduce for Apache Spark, Apache Hive and Presto.
The following image depicts the relationship between these services.
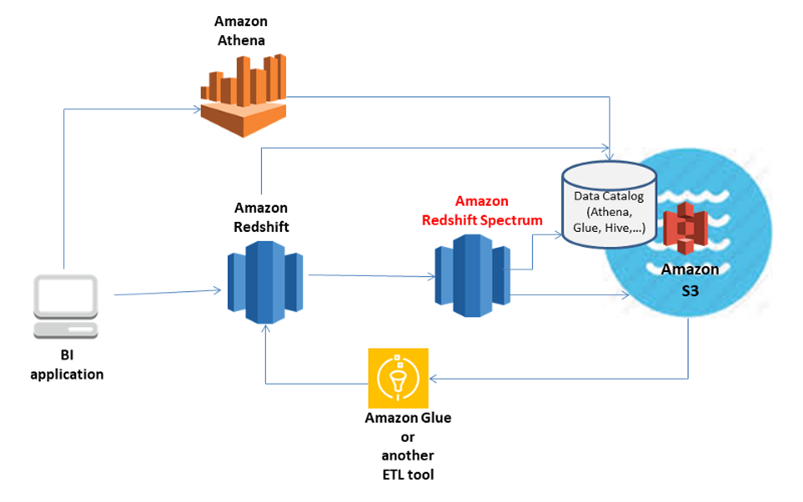
Source: Optimizing Data Query Processing and Storage — Redshift vs. Redshift Spectrum
Data catalog holds the data schema definition of the organization data stored in S3 Data lakes and it is the central repositories of metadata of the data assets. AWS glue, Athena data catalog, Hive metastore (Amazon EMR) are the various options available in the catalog.
Amazon Redshift and Redshift Spectrum Architecture
Amazon Redshift
Redshift architecture consists of two or more Computing Nodes that are connected to a Leader Node. All the communication between client applications and Cluster only happens through the Leader Node.
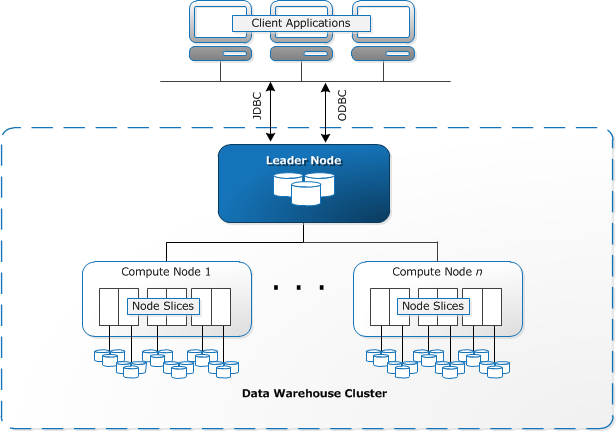
Source: Amazon Redshift Spectrum Extends Data Warehousing Out to Exabytes—No Loading Required
Amazon Redshift Spectrum
Redshift spectrum works on top of redshift architecture. It is added after the storage Phase. This is clearly depicted in the diagram below.
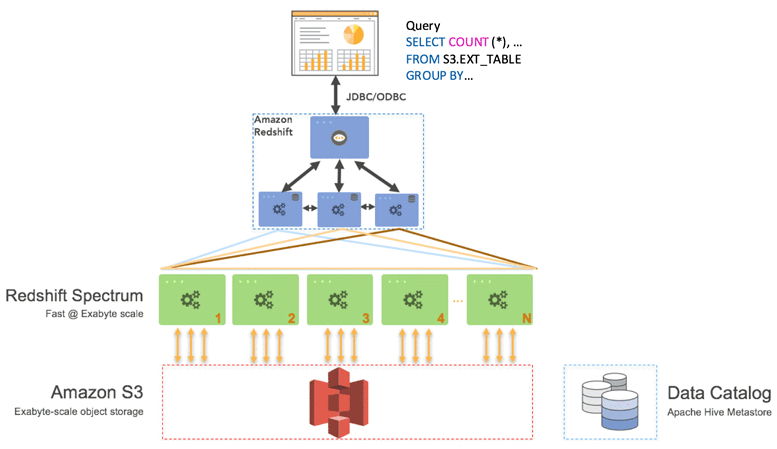
Source: Amazon Redshift Spectrum Extends Data Warehousing Out to Exabytes—No Loading Required
Redshift Spectrum vs. Athena
Amazon Athena is similar to Redshift Spectrum, though the two services typically address different needs. An analyst that already works with Redshift will benefit most from Redshift Spectrum because it can quickly access data in the cluster and extend out to infrequently accessed, external tables in S3. It's also better suited for fast, complex queries on multiple data sets.
Alternatively, Athena is a simpler way to run interactive, ad hoc queries on data stored in S3. It doesn't require any cluster management, and an analyst only needs to define a table to make a standard SQL query.
Other cloud vendors also offer similar services, such as Google BigQuery and Microsoft Azure SQL Data Warehouse.