Aurora
Amazon Aurora is a fully managed relational database engine developed by AWS. It offers high performance, availability, and scalability, while being compatible with MySQL and PostgreSQL. Aurora's architecture is designed for cloud-native capabilities and provides features like automatic backups, replication, and seamless scaling to meet the demands of modern applications.
Aurora cluster
An Amazon Aurora DB cluster consists of one or more DB instances and a cluster volume that manages the data for those DB instances. An Aurora cluster volume is a virtual database storage volume that spans multiple Availability Zones, with each Availability Zone having a copy of the DB cluster data. Two types of DB instances make up an Aurora DB cluster:
- Primary DB instance - Supports read and write operations, and performs all of the data modifications to the cluster volume. Each Aurora DB cluster has one primary DB instance.
- Aurora Replica - Connects to the same storage volume as the primary DB instance and supports only read operations. Each Aurora DB cluster can have up to 15 Aurora Replicas in addition to the primary DB instance. Maintain high availability by locating Aurora Replicas in separate Availability Zones. Aurora automatically fails over to an Aurora Replica in case the primary DB instance becomes unavailable. You can specify the failover priority for Aurora Replicas. Aurora Replicas can also offload read workloads from the primary DB instance.
The following diagram illustrates the relationship between the cluster volume, the primary DB instance, and Aurora Replicas in an Aurora DB cluster.
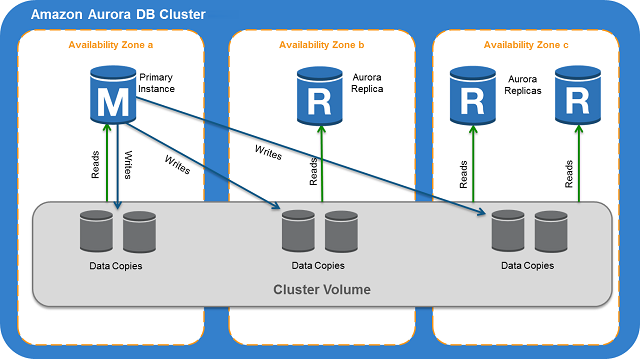
Source: Amazon Aurora DB clusters
Direct only outside the VPC
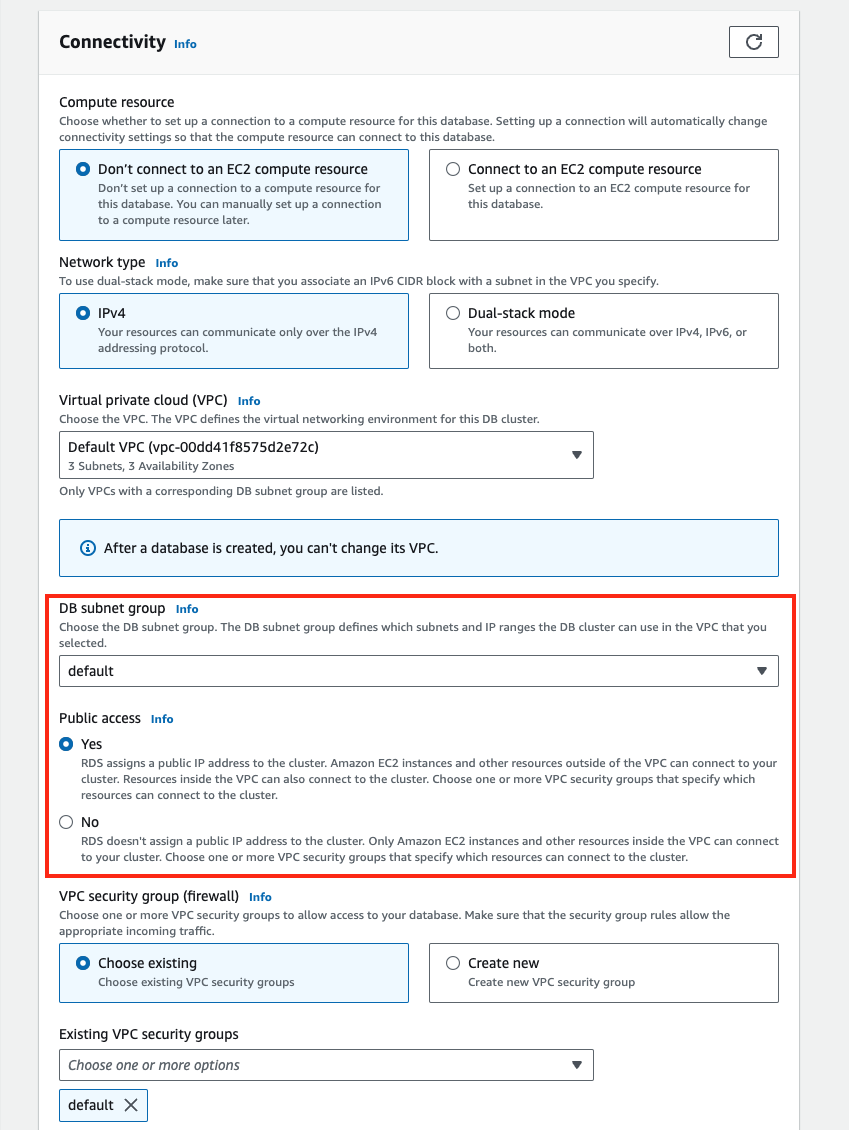
To connect to an Amazon Aurora DB cluster directly from outside the VPC, the instances in the cluster must meet the following requirements:
- The Aurora DB instance must have a public IP address
- Configure a public subnets for the Aurora DB subnet group
- For Amazon Aurora DB instances, you can't choose a specific subnet. Instead, choose a DB subnet group when you create the instance. A DB subnet group is a collection of subnets that belong to a VPC.
- Enable the VPC attributes
DNS hostnamesandDNS resolution
Global Database
With Global Database, a single Aurora database can span multiple AWS regions to enable fast local reads and quick disaster recovery between regions.
The difference between Aurora Global DB and Cross-region Read Replicas is that Global DB is physical replication(hardware) where Read replicas are logical replication.
With an Aurora global database, you can choose from two different approaches to failover:
- Managed planned failover
- Unplanned failover
Behaviours
Logging for MySQL-compatible DB cluster
By design, Aurora Serverless connects to a proxy fleet of DB instances that scales automatically. Because there isn't a direct DB instance to access and host the log files, you can't view the logs directly from the Amazon Relational Database Service (Amazon RDS) console. However, you can view and download logs that are sent to the CloudWatch console.
Further reading: How can I enable logs on an Aurora Serverless cluster so I can view and download the logs?
Failover in multiple AZs
In the event of an outage that affects an entire AZ where the primary instance of an Aurora cluster, the way to bring a new primary instance online depends on whether your cluster uses a multi-AZ configuration..
- Automatic failover
- If the cluster includes reader instances in other AZs, Aurora's failover mechanism is utilized, promoting one of the reader instances to become the new primary instance.
- Manual failover
- However, if the cluster only contains a single DB instance or all reader instances are in the outage affecting AZ, manual creation of new DB instances in another AZ is necessary to restore the database's availability.
Features
Replica for Read
Aurora Replicas are independent endpoints in an Aurora DB cluster, best used for scaling read operations and increasing availability. Up to 15 Aurora Replicas can be distributed across the Availability Zones that a DB cluster spans within an AWS Region. The DB cluster volume is made up of multiple copies of the data for the DB cluster. However, the data in the cluster volume is represented as a single, logical volume to the primary instance and to Aurora Replicas in the DB cluster.
Multi-Master For Write
You can use Amazon Aurora Multi-Master which is a feature of the Aurora MySQL-compatible edition that adds the ability to scale out write performance across multiple Availability Zones, allowing applications to direct read/write workloads to multiple instances in a database cluster and operate with higher availability.
Aurora Reader Endpoint
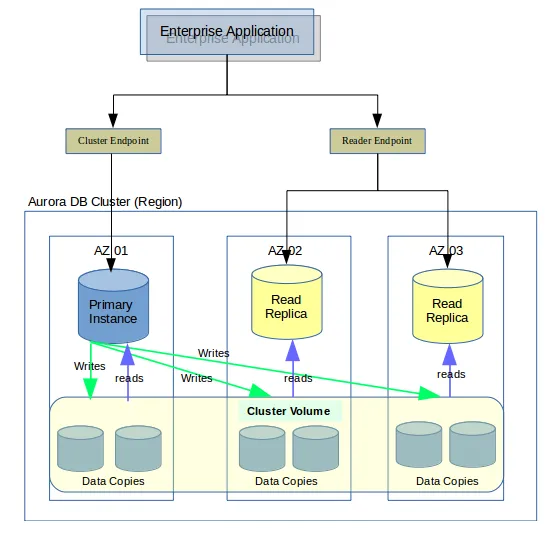
Source: AWS Aurora — Why is it better?
The reader endpoint in Aurora DB clusters enables load-balancing for read-only connections, distributing read operations among Aurora Replicas. This reduces the primary instance's workload and allows the cluster to handle simultaneous SELECT queries, scaling capacity based on the number of Aurora Replicas.
Each Aurora DB cluster has one reader endpoint, which load-balances connections among the Aurora Replicas for read-only statements like SELECT queries.
Backtrack
![]()
Aurora Backtrack has a maximum backtrack window of 72 hours, which means you can only roll back your database to any point in time within the last 72 hours. This is because Aurora Backtrack uses the transaction log to roll back changes, and transaction logs are only kept for 72 hours.
Aurora Backtrack allows you to easily undo unintended or incorrect changes to your database by rolling back the database to a specific point in time without needing to restore from a backup. This allows fast rollbacks without the need to create a new database instance.
Backtracking is not a replacement for backing up your DB cluster so that you can restore it to a point in time. However, backtracking provides the following advantages over traditional backup and restore:
- You can easily undo mistakes. If you mistakenly perform a destructive action, such as a DELETE without a WHERE clause, you can backtrack the DB cluster to a time before the destructive action with minimal interruption of service.
- You can backtrack a DB cluster quickly. Restoring a DB cluster to a point in time launches a new DB cluster and restores it from backup data or a DB cluster snapshot, which can take hours. Backtracking a DB cluster doesn't require a new DB cluster and rewinds the DB cluster in minutes.