DynamoDB
Amazon DynamoDB is a fully managed NoSQL database service which is designed for high-performance, low-latency, and scalable applications. DynamoDB can handle massive amounts of data and traffic, making it ideal for web, gaming, IoT, and mobile applications. It offers seamless scalability, automatic data replication, and built-in security. Users can choose on-demand or provisioned capacity modes. With its flexible data model, consistent performance, and ease of use, DynamoDB is a popular choice for applications requiring fast and reliable database services in the cloud.
Behaviour
Partitions and data distribution
Amazon DynamoDB stores data in partitions. A partition is an allocation of storage for a table, backed by solid state drives (SSDs) and automatically replicated across multiple Availability Zones within an AWS Region. Partition management is handled entirely by DynamoDB - you never have to manage partitions yourself.
When you create a table, the initial status of the table is CREATING. During this phase, DynamoDB allocates sufficient partitions to the table so that it can handle your provisioned throughput requirements. You can begin writing and reading table data after the table status changes to ACTIVE.
Partition types
DynamoDB supports two types of primary keys:
- Partition key: A simple primary key, composed of one attribute known as the partition key. Attributes in DynamoDB are similar in many ways to fields or columns in other database systems.
- Partition key and sort key: Referred to as a composite primary key, this type of key is composed of two attributes. The first attribute is the partition key, and the second attribute is the* sort key*. All data under a partition key is sorted by the sort key value. The following is an example.
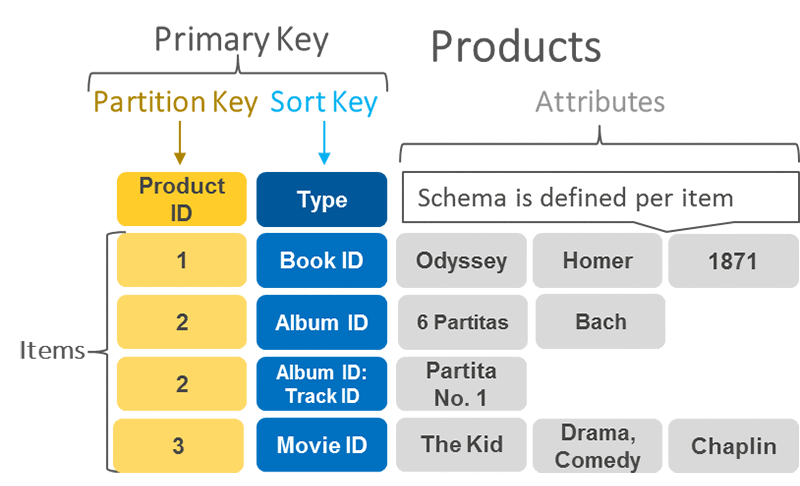
Source: Choosing the Right DynamoDB Partition Key
Feature
DynamoDB Stream for a hybrid solution
DynamoDB can take advantage of DynamoDB Streams and AWS Lambda to integrate seamlessly with one or more existing relational database systems. To check what 3 steps to be implemented, check this blog Best practices for implementing a hybrid database system
Conditional writes
DynamoDB optionally supports conditional writes for write operations (PutItem, UpdateItem, DeleteItem). A conditional write succeeds only if the item attributes meet one or more expected conditions. Otherwise, it returns an error.
For example, you might want a PutItem operation to succeed only if there is not already an item with the same primary key. Or you could prevent an UpdateItem operation from modifying an item if one of its attributes has a certain value. Conditional writes are helpful in cases where multiple users attempt to modify the same item.
Atomic Counters
Atomic Counters is a numeric attribute that is incremented, unconditionally, without interfering with other write requests. You might use an atomic counter to track the number of visitors to a website.
Backup methods
There are 4 different way to backup DynamoDB.
- DynamoDB has two built-in backup methods (On-demand, Point-in-time recovery) that write to Amazon S3, but you will not have access to the S3 buckets that are used for these backups.
- Use AWS Data Pipeline to export your table to an S3 bucket in the account of your choice and download locally
- This is the easiest method. This method is used when you want to make a one-time backup using the lowest amount of AWS resources possible. Data Pipeline uses Amazon EMR to create the backup, and the scripting is done for you. You don't have to learn Apache Hive or Apache Spark to accomplish this task.
- Use Hive with Amazon EMR to export your data to an S3 bucket and download locally
- Use Hive to export data to an S3 bucket. Or, use the open-source emr-dynamodb-connector to manage your own custom backup method in Spark or Hive. These methods are the best practice to use if you're an active Amazon EMR user and are comfortable with Hive or Spark. These methods offer more control than the Data Pipeline method.
- Use AWS Glue to copy your table to Amazon S3 and download locally
- Use AWS Glue to copy your table to Amazon S3. This is the best practice to use if you want automated, continuous backups that you can also use in another service, such as Amazon Athena.
Performance
Belows are the features that can help to reduce the latency
Global tables
DynamoDB global tables provide cross-region active-active capabilities with high performance, but you lose some of the data access flexibility that comes with SQL-based databases. Due to the active-active configuration of DynamoDB global tables, there is no concept of failover because the application writes to the table in its region, and then the data is replicated to keep the other regions' table in sync.
Consider using Global tables if your application is accessed by globally distributed users - If you have globally dispersed users, consider using global tables. With global tables, you can specify the AWS Regions where you want the table to be available. This can significantly reduce latency for your users. So, reducing the distance between the client and the DynamoDB endpoint is an important performance fix to be considered.
The two most commonly used multiregion architecture configurations are active-passive and active-active.
-
An active-passive architecture configuration typically comprises at least two regions. However, not all regions serve traffic simultaneously, and therefore the name "active-passive." When the configuration includes two regions, one region actively serves traffic while the second region is passive, ready to support a failover in case the active region experiences issues.
-
An active-active configuration comprises at least two regions. However, unlike an active-passive configuration where one region is actively serving traffic while the other is passive, in an active-active configuration, all regions are actively running the same kind of service and serving traffic simultaneously.
The main purpose of an active-active configuration is to achieve load balancing between regions, often using latency-based routing that routes service traffic to the region that provides the fastest experience.
Use eventually consistent
Use eventually consistent reads in place of strongly consistent reads whenever possible - If your application doesn't require strongly consistent reads, consider using eventually consistent reads. Eventually consistent reads are cheaper and are less likely to experience high latency.
API
TransactWriteItems & TransactGetItems
You can group multiple actions together and submit them as a single all-or-nothing TransactWriteItems or TransactGetItems operation. You can use AWS IAM to restrict the actions that transactional operations can perform in Amazon DynamoDB.
BatchWriteItem vs TransactWriteItemsIn contract, the difference of the BatchWriteItem operation is - it is possible that only some of the actions in the batch succeed while the others do not.
PutItem vs UpdateItem
The main difference between the two is, PutItem will Replace an entire item while UpdateItem will Update it. If you have an item like below
userId = 1
Name= ABC
Gender= Male
and use PutItem item with
UserId = 1
Country = India
This will replace Name and Gender and now new Item is UserId and Country. While if you want to update an item from Name = ABC to Name = 123 you have to use UpdateItem.
You can use PutItem item to update it but you need to send all the parameters instead of just the Parameter you want to update because it Replaces the item with the new attribute(Internally it Deletes the item and Adds a new item)
Source: Difference between DynamoDb PutItem vs UpdateItem?
Parallel scans
FilterExpression won't improve your performanceKeep in mind that Scan api with FilterExpression won't improve the preformance of retrieving data, because a filter expression is applied after a Scan finishes, but before the results are returned. Therefore, a Scan consumes the same amount of read capacity, regardless of whether a filter expression is present.

Source: Parallel scan
Practices
Export table to S3 bucket from other account
When you export your DynamoDB tables to an S3 bucket in Account B, the objects are still owned by you. The AWS IAM users in Account B can't access the objects by default. The export function doesn't write data with the access control list (ACL) bucket-owner-full-control.
As a workaround to this object ownership issue, include the PutObjectAcl permission on all exported objects after the export is complete. This workaround grants access to all exported objects for the bucket