Lambda
AWS Lambda is a serverless compute service offered by AWS. It allows you to run code in response to various events without the need to provision or manage servers. You can upload your code, define event triggers, and Lambda automatically scales and manages the infrastructure. It supports a variety of programming languages and is ideal for building microservices, data processing tasks, and automation. With Lambda, you only pay for the compute time consumed during code execution, making it cost-effective and scalable for a wide range of applications.
Features
Deploy Lambda functions as container images
- You can deploy Lambda function as a container image, with a maximum size of 15 GB
- You must create the Lambda function from the same account as the container registry in Amazon ECR
- To deploy a container image to Lambda, the container image must implement the Lambda Runtime API
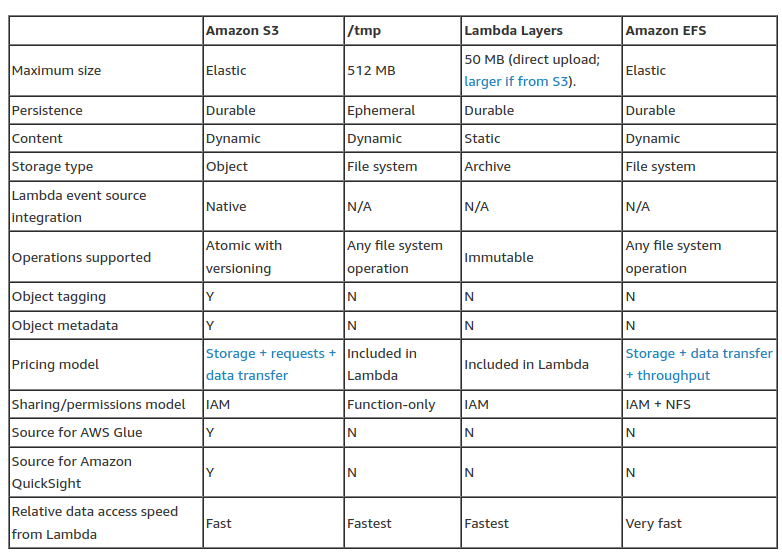
Lambda data storage
Comparing the different data storage options
This table compares the characteristics of these four different data storage options for Lambda:
Cross account sharing
To have your Lambda function assume an IAM role in another AWS account, do the following:
- Configure your Lambda function's execution role to allow the function to assume an IAM role in another AWS account.
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::222222222222:role/role-on-source-account"
}
}
- Modify your cross-account IAM role's trust policy to allow your Lambda function to assume the role.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::111111111111:role/my-lambda-execution-role"
},
"Action": "sts:AssumeRole"
}
]
}
- Add the AWS Security Token Service (AWS STS) AssumeRole API call to your Lambda function's code.
import boto3
def lambda_handler(event, context):
sts_connection = boto3.client('sts')
acct_b = sts_connection.assume_role(
RoleArn="arn:aws:iam::222222222222:role/role-on-source-account",
RoleSessionName="cross_acct_lambda"
)
ACCESS_KEY = acct_b['Credentials']['AccessKeyId']
SECRET_KEY = acct_b['Credentials']['SecretAccessKey']
SESSION_TOKEN = acct_b['Credentials']['SessionToken']
# create service client using the assumed role credentials, e.g. S3
client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY,
aws_session_token=SESSION_TOKEN,
)
return "Hello from Lambda"
Note: A Lambda function can assume an IAM role in another AWS account to do either of the following:
- Access resources: For example, accessing an Amazon Simple Storage Service (Amazon S3) bucket.
- Do tasks: For example, starting and stopping instances.
- Execution role—The primary role in account A that gives the Lambda function permission to do its work.
- Assumed role—A role in account B that the Lambda function in account A assumes to gain access to cross-account resources.
Reference: How do I configure a Lambda function to assume an IAM role in another AWS account?
Working in VPC
Behaviour
By default, when your Lambda function is not configured to connect to your own VPCs, the function can access anything available on the public internet such as other AWS services, HTTPS endpoints for APIs, or services and endpoints outside AWS. The function then has no way to connect to your private resources inside of your VPC.
When you configure your Lambda function to connect to your own VPC, it creates an elastic network interface in your VPC and then does a cross-account attachment. These network interfaces allow network access from your Lambda functions to your private resources. These Lambda functions continue to run inside of the Lambda service’s VPC and can now only access resources over the network through your VPC.
Why can't an AWS lambda function inside a public subnet in a VPC connect to the internet?
Lambda functions connected to a VPC public subnet cannot typically access the internet.
To access the internet from a public subnet you need a public IP or you need to route via a NAT that itself has a public IP. You also need an Internet Gateway (IGW). However:
- Lambda functions do not, and cannot, have public IP addresses, and
- the default route target in a VPC public subnet is the IGW, not a NAT
So, because the Lambda function only has a private IP and its traffic is routed to the IGW rather than to a NAT, all packets to the internet from the Lambda function will be dropped at the IGW.
Further reading: Stack overflow: Why can't an AWS lambda function inside a public subnet in a VPC connect to the internet?
When configuring Lambda functions for VPC access, it is an HA best practice to configure multiple (private) subnets across different Availability Zones (AZs).
When do you need a VPC Access?
If your Lambda function does not need to reach private resources inside your VPC (e.g. an RDS database or Elasticsearch cluster) then do not configure the Lambda function to connect to the VPC.
If your Lambda function does need to reach private resources inside your VPC, then configure the Lambda function to connect to private subnets (and only private subnets). When you configure your Lambda function to connect to your own VPC, it creates an elastic network interface in your VPC and then does a cross-account attachment. These network interfaces allow network access from your Lambda functions to your private resources. Check the below image
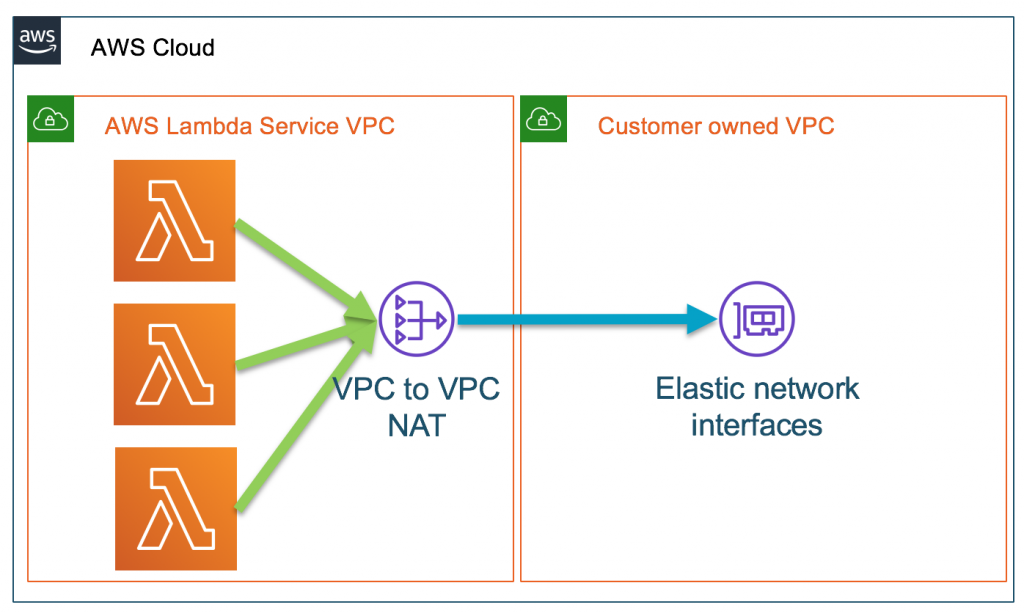
When do you need to connect to NAT?
If the Lambda function only needs access to resources in the VPC (e.g. an RDS database in a private subnet) then you don't need to route through NAT.
If the Lambda function only needs access to resources in the VPC and access to AWS services that are all available via private VPC Endpoint then you don't need to route through NAT. Use VPC Endpoints.
If your Lambda function needs to reach endpoints on the internet then ensure a default route from the Lambda function's private subnets to a NAT instance or NAT Gateway in a public subnet. And configure an IGW, if needed, without which internet access is not possible.
Be aware that NAT gateway charges per hour and per GB processed so it's worth understanding how to reduce data transfer costs for NAT gateway.
Intermittent Connectivity
Be sure that *all the subnets you configure for your Lambda function are private subnets *. It is a common mistake to configure.
For example, 1 private subnet and 1 public subnet. This will result in your Lambda function working OK sometimes and failing at other times without any obvious cause. The Lambda function may succeed 5 times in a row, and then fail with a timeout (being unable to access some internet resource or AWS service).
This happens because the first launch was in a private subnet, launches 2-5 reused the same Lambda function execution environment in the same private subnet (the so-called "warm start"), and then launch 6 was a "cold start" where the AWS Lambda service deployed the Lambda a function in a public subnet where the Lambda function has no route to the internet.
How to use AWS services from a Lambda in a VPC
Belows are the different ways to use AWS Services in our Lambda function that is in a VPC.
| Method | Works for | Cost |
|---|---|---|
| NAT Gateway | Any AWS service / third-party service | 33.50 monthly) PLUS $0.045/GB processing |
| VPC gateway endpoint | S3, DynamoDB | None |
| VPC interface endpoint | 66 different AWS services , including Amazon CloudWatch, Kinesis Firehose, SNS, SQS, and SSM. | 7.45 monthly) or $0.01/GB processing |
| Amazon CloudWatch Embedded Metric Format | Amazon CloudWatch only | None |
| Lambda Destinations | SNS, SQS, EventBridge But: only for asynchronous Lambda invocation results | None |
Further reading: Three ways to use AWS services from a Lambda in a VPC
Scaling
Concurrency in Lambda
A Lambda function scales by creating enough execution environments to be able to process the amount of concurrent requests it receives at any given time. The scaling works as follows:
-
Let's say I have set the total number of concurrent executions in my AWS account to 5000.
-
Then, a popular news website mentions my product and my function suddenly receives a burst of traffic, and the number of concurrent requests grows rapidly, up to more than 5000 requests.
-
Lambda will start from 500 to 3000 (this number depends on a region) instances of my function really fast. This is called burst concurrency limit. Let's say, my function is in the US East region and the burst limit is 3000. So, I'd get 3000 instances quickly to handle that burst of traffic.
-
Once the burst concurrency limit is reached, my function will scale by only 500 instances per minute until my account's concurrency execution limit is reached (until 5000 instances) and no more instances are being created to accommodate new concurrent requests.
-
If this concurrency limit won't be enough to serve additional requests, those requests are gonna be throttled.
-
Also, before the account's concurrency limit is reached, the requests for which Lambda won't be able to set up an execution environment on time are gonna be throttled as well.
Further reading: Concurrency in Lambda
Provisioned Concurrency
A major problem with Lambda concurrency is the possibility of Lambda cold starts. A cold start is the first request handled by new Lambda workers and may take up to five seconds to execute. This can significantly impact both latency and user experience (read more in our guide to Lambda performance).
A cold start occurs because Lambda must initialize the worker (a container that runs your functions on the server) and the function module before passing the request to the handler function. When invoking a function, Lambda needs a container to be ready. After invoking a function, a container stays warm for a limited amount of time (usually 30-45 minutes) before it is shut down.
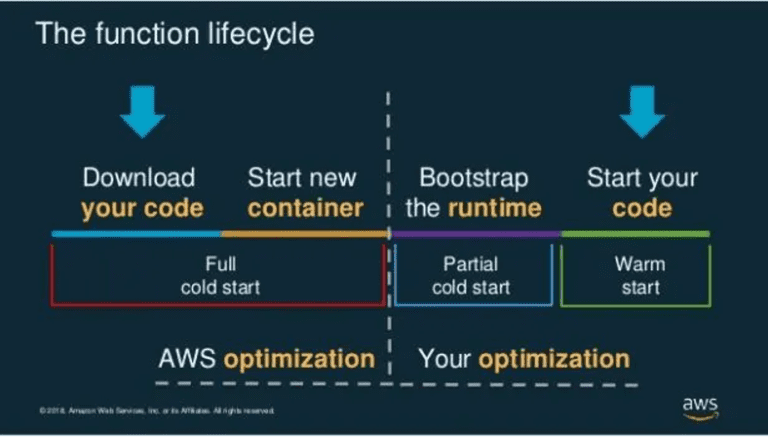
Application Auto Scaling
Application Auto Scaling takes this a step further by providing autoscaling for provisioned concurrency. With Application Auto Scaling, you can create a target tracking scaling policy that adjusts provisioned concurrency levels automatically, based on the utilization metric (sai: CloudWatch metric) that Lambda emits. Use the Application Auto Scaling API to register an alias as a scalable target and create a scaling policy.
In the following example, a function scales between a minimum and maximum amount of provisioned concurrency based on utilization. When the number of open requests increases, Application Auto Scaling increases provisioned concurrency in large steps until it reaches the configured maximum. The function continues to scale on standard concurrency until utilization starts to drop. When utilization is consistently low, Application Auto Scaling decreases provisioned concurrency in smaller periodic steps.
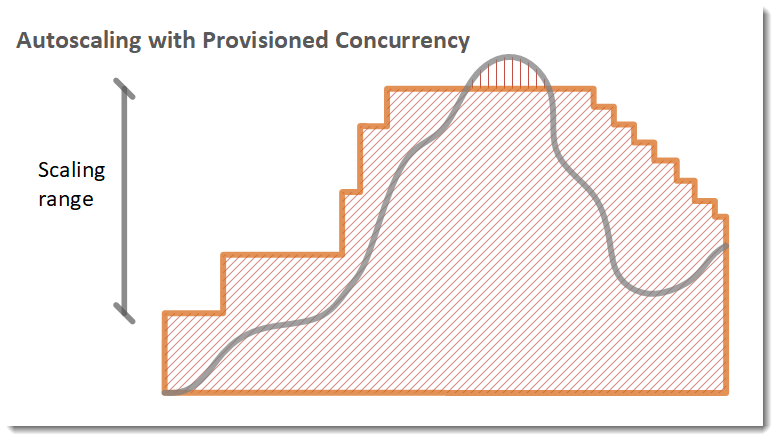
Source: Lambda function scaling
Futher reading: Comamnd example Scheduling AWS Lambda Provisioned Concurrency for recurring peak usage
Concurrency Limits and Scalability
Lambda concurrency limits will depend on the Region where the function is deployed. It will vary from 500 to 3,000.
New functions are limited to this default concurrency threshold set by Lambda. After an initial burst of traffic, Lambda can scale up every minute by an additional 500 microVMs1 (or instances of a function).
This scaling process continues until the concurrency limit is met. Developers can request a concurrency increase in the AWS Support Center2.
When Lambda is not able to cope with the amount of concurrent requests an application is experiencing, requesters will receive a throttling error (429 HTTP status code)3.
How is the Burst Capacity related to the Baseline (execution limit)?
Lambda functions run in execution environments. The burst limit is the number of new execution environments that need to be created to handle the requests. We use a bucket algorithm with a predefined token capacity (500 / 1,000 / 3,000, depending on the region) and a fixed refill rate of 500 tokens / min. When we need to create a new execution environment, we first take a token from the bucket, if one exists. If the bucket is empty, the request is throttled.
This means that in the larger regions for example, if you are running at a steady 1,000 concurrency for some period of time, which allows the bucket to get full (6 minutes), you will be able to invoke additional 3,000 concurrent functions and get to 4,000 concurrency immediately.
Note that the burst limit is shared across all functions in the account and that you can't scale beyond the account's concurrency limit, which is 1,000 by default.
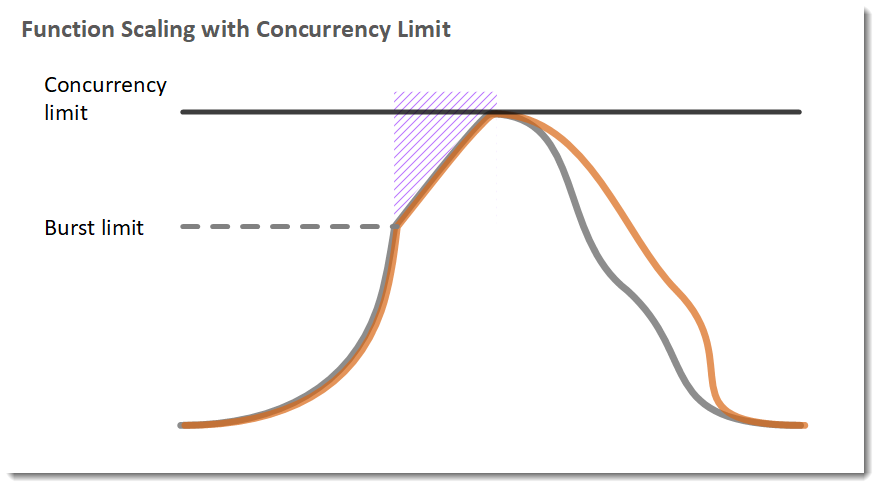
After the capacity reaches the burst limit, the system will add 500 capcity per minute linearly, until it reaches concurrency limit
Further reading: How is the Burst Capacity related to the Baseline (execution limit)?
Lambda Throttling

Source: What is Lambda Throttling? (and how to fix it!)
-
Request unreserved concurrency limit increase: The first and probably the easiest thing that you can do is that you can request an unreserved concurrency limit increase, and this is at no cost to you. So the default limit per account per region is 1000 concurrent invocations
-
Specify reserve concurrency per function: The second mitigation technique is to specify a reserved concurrency per function and you can set this in the configuration section of your Lambda function. (Reserved concurrency is the maximum number of concurrent instances for the function. When a function has reserved concurrency, no other function can use that concurrency.)
- So what reserved concurrency does? It reserves several concurrent execution requests for a particular Lambda function. So in the example that we were discussing before, we had three Lambda functions and they were all kind of competing for that 1000 concurrency limit. Now, using this approach, you can slot a 200 concurrent limit for a particular function. So at any point in time, regardless of what your other functions are doing, this function will always be able to handle 200 concurrent requests, and the other two functions going back to the previous example will have to compete for this pool. So, in this case, it is 800. This is a mitigation technique.
-
Configure a DLQ to capture failure: The most important is to configure a dead letter Q to capture failure as I've kind of described before. This is very important if you are receiving Throttling and you need to redirect those messages at a later point in time.
-
Alarm on throttling exceptions: Possibly the most important is to alarm on Throttling and the presence of messages in your DLQ if you are using one. So obviously setting up a bunch of these mechanisms will help mitigate the issue But in the case that it does happen, you do need to become aware of it so that you can deal with it appropriately.
Limitation
Some numbers for reference:
- The total size of all environment variables doesn't exceed 4 KB.
3 Ways to Overcome AWS Lambda Deployment Size Limit
AWS Lambda imposes certain quotas and limits on the size of the deployment package, i.e. 50MB for zipped + direct upload, and 250MB (actual figure around 262MB) for uncompressed package.
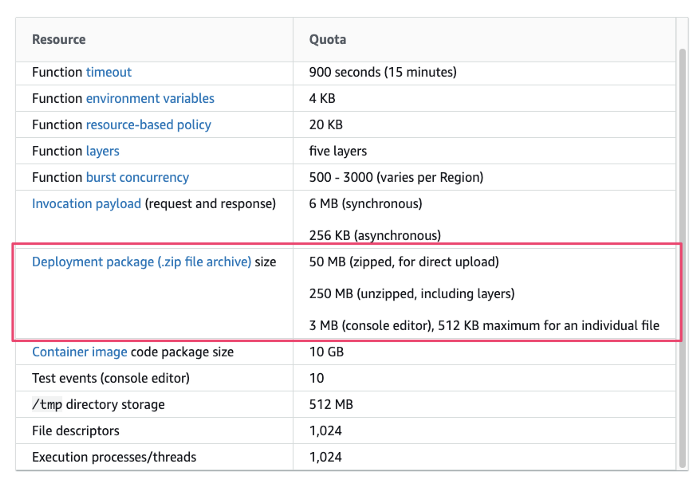
The belows are the workaround to overcome the limit.
- Using S3 to store certain files/data
- Using Amazon Elastic File System --- EFS
- (This is pretty new!) Using Container Image, covered in Part 2
How long can an AWS Lambda function execute?
AWS Lambda functions can be configured to run up to 15 minutes per execution. You can set the timeout to any value between 1 second and 15 minutes.
Troubleshooting
Decode Authorization Message CLI�
If a user is not authorized to perform an action that was requested, the request returns a Client.UnauthorizedOperation response (an HTTP 403 response). The message is encoded because the details of the authorization status can constitute privileged information that the user who requested the operation should not see.
To decode an authorization status message, a user must be granted permissions via an IAM policy to request the DecodeAuthorizationMessage (sts:DecodeAuthorizationMessage) action.