AWS Auto Scaling
AWS Auto Scaling is a service that helps you optimize the performance of your applications while lowering infrastructure costs by easily and safely scaling multiple AWS resources.
Using AWS Auto Scaling, you can configure automatic scaling for all of the scalable resources powering your application from a single unified interface, including:
- Amazon EC2: Launch or terminate Amazon EC2 instances in an Amazon EC2 Auto Scaling group.
- Amazon EC2 Spot Fleets: Launch or terminate instances from an Amazon EC2 Spot Fleet or automatically replace instances that get interrupted for price or capacity reasons.
- Amazon ECS: Adjust ECS service desired count up or down to respond to load variations.
- Amazon DynamoDB: Enable a DynamoDB table or a global secondary index to increase its provisioned throughput (read and write) capacity to handle sudden increases in traffic without request throttling.
- Amazon Aurora: Dynamically adjust the number of Aurora Read Replicas provisioned for an Aurora DB cluster to handle sudden increases in active connections or workload.
In Amazon Web Services (AWS), there are two types of Auto Scaling that can be used with Auto Scaling Groups (ASGs):
- Dynamic scaling = Scaling on Demand.
- It allows AWS to automatically adjust the capacity of the Auto Scaling group based on predefined scaling policies.
- Manual Scaling
- In manual scaling, you control the scaling process by manually adjusting the desired capacity of the Auto Scaling group. This means you need to explicitly set the number of instances you want to maintain in the group, and AWS will not automatically adjust the capacity based on resource utilization or other metrics.
Behaviour
Some points to remember:
- ASG cannot scale out to other AWS regions.
- ASG has two primary process types:
LaunchandTerminate. The Launch process adds new instances to the Auto Scaling group, increasing capacity, while the Terminate process removes instances from the group, decreasing capacity. - Suspension
- You have an ASG in which the
Terminateprocess is suspended and it goes into a Availability Zone rebalancing process(AZRebalance). ASG'll start and the EC2 instances will launch, the ASG will grow up to 10% of its size. The instances will not get terminated because this is allowed temporarily during rebalancing activities. If the scaling process cannot terminate instances, your Auto Scaling group could remain above its maximum size until you resume the Terminate process. - If you suspend the
Launchprocess,AZRebalanceneither launches new instances nor terminates existing instances. This is because AZRebalance terminates instances only after launching the replacement instances.
- You have an ASG in which the
- Monitoring
- By default, basic monitoring is enabled when you use the AWS management console to create a launch configuration.
- Detailed monitoring is enabled by default when you create a launch configuration using the AWS CLI
ASG terminates unhealthy EC2 instance
The default behaviour of after ternminating instances, ASG addes new instances. If you want to terminate an instance from the specified Auto Scaling group without updating the size of the group.
You can use terminate-instance-in-auto-scaling-group CLI command terminates the specified instance and optionally adjusts the desired group size. This call simply makes a termination request so the instance is not terminated immediately.
The example below terminates the specified instance from the specified Auto Scaling group without updating the size of the group:
aws autoscaling terminate-instance-in-auto-scaling-group --instance-id i-93633f9b --no-should-decrement-desired-capacity
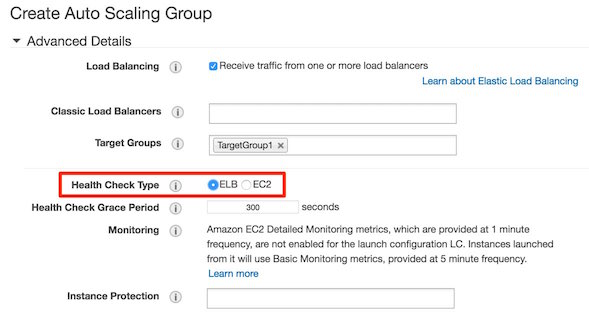
By default, the health check configuration of your Auto Scaling group is set as an EC2 type that performs a status check of EC2 instances. (You can change the health check type of an Auto Scaling group from an EC2 type to ELB type. - reference: Add Elastic Load Balancing health checks)
To maintain the same number of instances, Amazon EC2 Auto Scaling performs a periodic health check on running instances within an Auto Scaling group. When it finds that an instance is unhealthy, it terminates that instance and launches a new one.
Amazon EC2 Auto Scaling creates a new scaling activity for terminating the unhealthy instance and then terminates it. Later, another scaling activity launches a new instance to replace the terminated instance.
Instance warm-up
With step scaling policy, you can optionally specify the number of seconds that it takes for a newly launched instance to warm up. Before its specified warm-up time expires, an instance isn't counted toward the aggregated EC2 instance metrics of the Auto Scaling group.
If the group scales out again, the instances that are still warming up are** counted as part of the desired capacity for the next scale-out activity**. Therefore, multiple alarm breaches that fall in the range of the same step adjustment result in a single scaling activity. The intention is to continuously (but not excessively) scale out.
Reference: Instance warm-up
Rebalancing activities
After launching new instances, it then terminates old instances. AWS - Official document
Rebalancing activities fall into two categories: Availability Zone rebalancing and capacity rebalancing
Availability Zone rebalancing
The following actions can lead to unbalanced between Availability Zones - reference:
- You change the Availability Zones for your group.
- You explicitly terminate or detach instances and the group becomes unbalanced.
- An Availability Zone that previously had insufficient capacity recovers and has additional capacity available.
- An Availability Zone that previously had a Spot price above your maximum price now has a Spot price below your maximum price.
It would remain wildly unbalanced until other scaling events caused it to move back toward balance, without this.
Capacity Rebalancing
You can enable Capacity Rebalancing for your Auto Scaling groups when using Spot Instances. When you turn on Capacity Rebalancing, Amazon EC2 Auto Scaling attempts to launch a Spot Instance whenever Amazon EC2 notifies that a Spot Instance is at an elevated risk of interruption.
Launch configuration
A launch configuration in AWS Auto Scaling group is a template that defines the configuration for launching instances. It includes details such as the Amazon Machine Image (AMI), instance type, security groups, and user data. When scaling actions are triggered, the launch configuration is referenced to provision new instances. It provides a consistent setup for instances within the Auto Scaling group and enables easy replication of configurations across multiple instances.
You can't modify a launch configuration after you've created it.
VPC Tenancy and ASG Tenancy
Source: Configure instance tenancy with a launch configuration
A launch configuration is an instance configuration template that an Auto Scaling group uses to launch EC2 instances. When you create a launch configuration, you specify information for the instances. Include the ID of the Amazon Machine Image (AMI), the instance type, a key pair, one or more security groups, and a block device mapping. If you've launched an EC2 instance before, you specified the same information to launch the instance.
When you create a launch configuration, the default value for the instance placement tenancy is null and the instance tenancy is controlled by the tenancy attribute of the VPC.
- If you set the Launch Configuration Tenancy to default and the VPC Tenancy is set to dedicated, then the instances have dedicated tenancy.
- If you set the Launch Configuration Tenancy to dedicated and the VPC Tenancy is set to default, then again the instances have dedicated tenancy.
Launch Configuration Tenancy vs VPC Tenancy
| Launch configuration tenancy | VPC tenancy = default | VPC tenancy = dedicated |
|---|---|---|
| not specified | shared-tenancy instances | Dedicated Instances |
default | shared-tenancy instances | Dedicated Instances |
dedicated | Dedicated Instances | Dedicated Instances |
Source: New – T3 Instances on Dedicated Single-Tenant Hardware
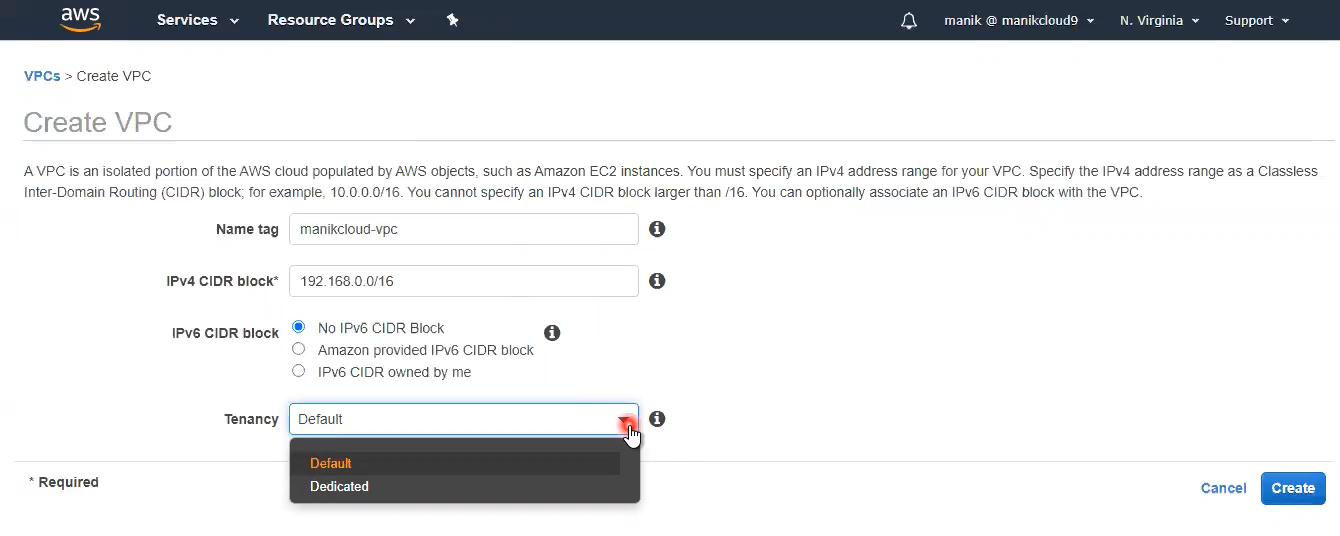
Source: How to Create AWS VPC in 10 steps, less than 10 min
Scaling
Full document: Scale the size of your Auto Scaling group
EC2 Auto Scaling Policies provide several ways for scaling the Auto Scaling group.
- Manual Scaling
- Scheduled Scaling
- Dynamic Scaling Policy Types
- Target tracking scaling
- Step scaling: Increase or decrease the current capacity of the group based on a set of scaling adjustments based on the size of the alarm breach.
- Simple scaling: Increase or decrease the current capacity of the group based on a single scaling adjustment.
- Predictive Scaling
Target Tracking Scaling
TL;DR - You should only use target tracking policy if you want to maintain a specific load. Auto-scaling will spawn and remove instances based on the load you specify, regardless of what your application demands.
To create a target tracking scaling policy, you specify an Amazon CloudWatch metric and a target value that represents the ideal average utilization or throughput level for your application.
- ASGAverageNetworkOut - This represents the Average number of bytes sent out on all network interfaces by the Auto Scaling group.
- ALBRequestCountPerTarget
- ASGAverageCPUUtilization
Besides target tracking scaling policy, You can also scalling based on the number of messages in a SQS queue - document
Scheduled scaling
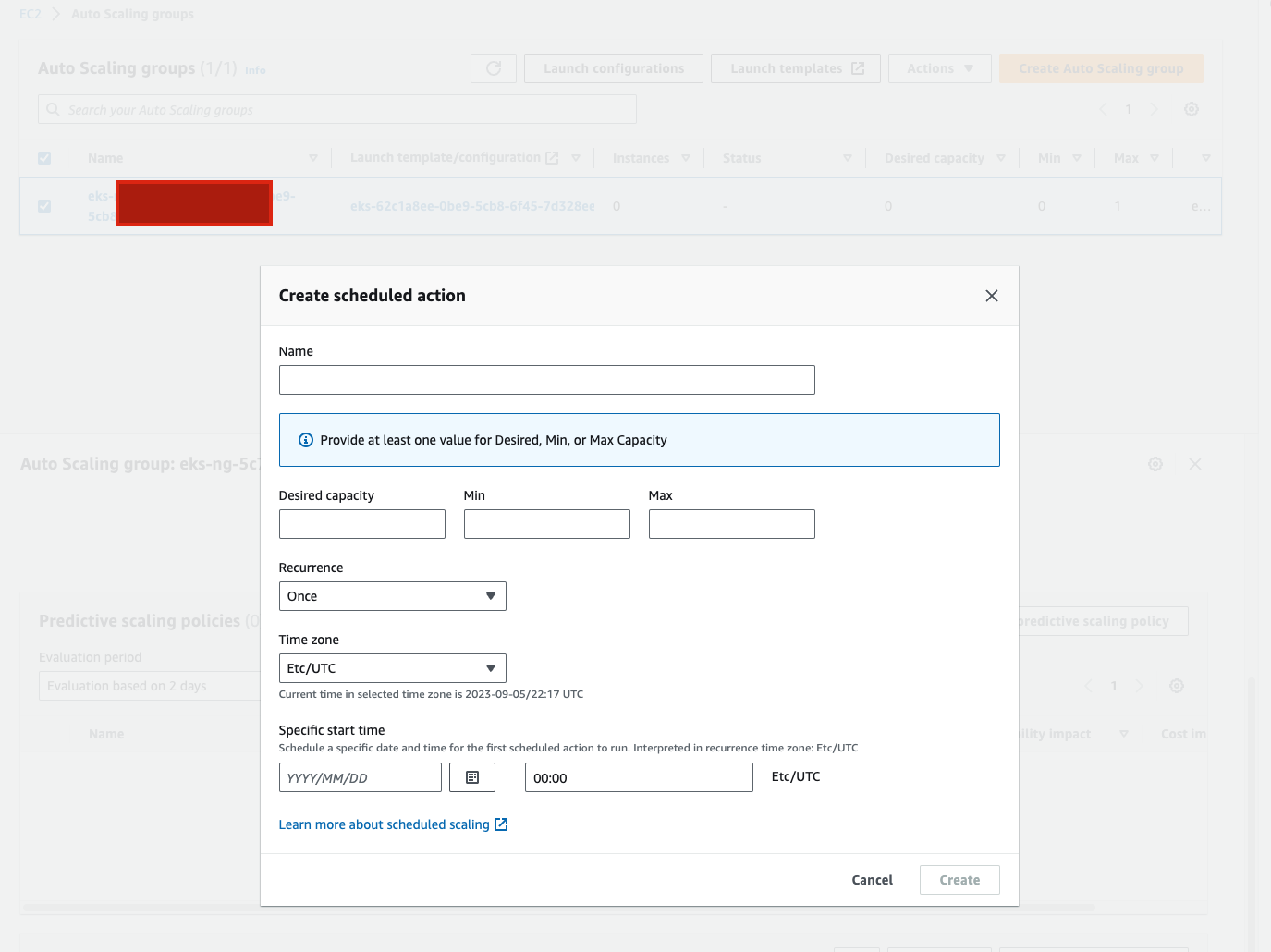
Scheduled scaling helps you to set up your own scaling schedule according to predictable load changes. For example, let’s say that every week the traffic to your web application starts to increase on Wednesday, remains high on Thursday, and starts to decrease on Friday. You can configure a schedule for Amazon EC2 Auto Scaling to increase capacity on Wednesday and decrease capacity on Friday.
Configuration
EC2 Auto Scaling works with both ALB and NLB
Amazon EC2 Auto Scaling works with Application Load Balancers and Network Load Balancers including their health check feature.
Instance scale-in protection
To control whether an Auto Scaling group can terminate a particular instance when scaling in, use instance scale-in protection. You can enable the instance scale-in protection setting on an Auto Scaling group or an individual Auto Scaling instance.
Imagine there is a server infrastructure on a fleet of Amazon EC2 instances running behind an Auto Scaling Group (ASG). The SysOps Administrator has configured the instances to be protected from termination during scale-in. When a scale-in event has occurred. What is the outcome of the event?
If all instances in an Auto Scaling group are protected from termination during scale in, and a scale-in event occurs, its desired capacity is decremented. However, the ASG can't terminate the required number of instances until their instance scale-in protection settings are disabled.
Instance scale-in protection does not protect Auto Scaling instances from the following:
- Manual termination through the Amazon EC2 console, the
terminate-instancescommand, or the TerminateInstances action. To protect Auto Scaling instances from manual termination, enable Amazon EC2 termination protection. - Health check replacement if the instance fails health checks. To prevent Amazon EC2 Auto Scaling from terminating unhealthy instances, suspend the ReplaceUnhealthy process.
- Spot Instance interruptions. A Spot Instance is terminated when capacity is no longer available or the Spot price exceeds your maximum price.
You can protect instances from termination by simply selecting them in the Auto Scaling Console and then choosing Instance Protection from the Actions menu:
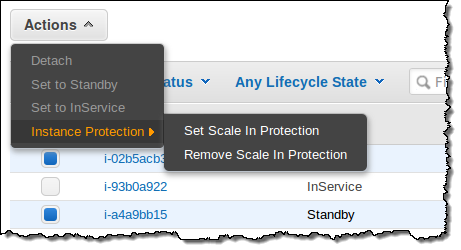
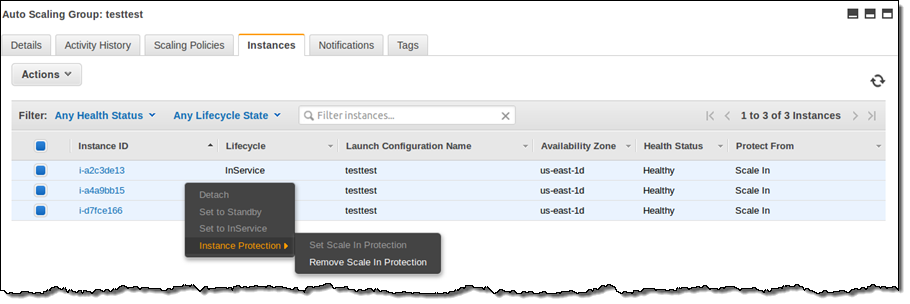
Source: Instance Protection for Auto Scaling
Troubleshooting
Client.InternalError: Client error on launch
Client.InternalError: Client error on launch error is caused when an Auto Scaling group attempts to launch an instance that has an encrypted EBS volume, but the service-linked role does not have access to the customer-managed CMK used to encrypt it. Additional setup is required to allow the Auto Scaling group to launch instances.
There are two scenarios possible:
- CMK and Auto Scaling group are in the same AWS account
- Copy and re-encrypt the snapshot with another CMK that belongs to the same account as the Auto Scaling group. Allow the service-linked role to use the new CMK.
- CMK and Auto Scaling group are in different AWS accounts.
- Determine which service-linked role to use for this Auto Scaling group.
- Allow the Auto Scaling group account access to the CMK. Define an IAM user or role in the Auto Scaling group account that can create a grant.
- Create a grant to the CMK with the service-linked role as the grantee principal.
- Update the Auto Scaling group to use the service-linked role.
To check the detailed actions, check Troubleshoot Amazon EC2 Auto Scaling: EC2 instance launch failure
2 policies being trickered at the same time
Imagine there is a scenario which - A retail company has a fleet of EC2 instances running behind an Auto Scaling group (ASG). The development team has configured two metrics that control the scale-in and scale-out policies of ASG.
- Target tracking policy that uses a custom metric to add and remove two new instances, based on the number of SQS messages in the queue.
- Step scaling policy that uses the CloudWatch CPUUtilization metric to launch one new instance when the existing instance exceeds 90 percent utilization for a specified length of time.
While testing, the scale-out policy criteria for both policies was met at the same time. How many new instances will be launched because of these multiple scaling policies?
Amazon EC2 Auto Scaling chooses the policy that provides the largest capacity, so policy with the custom metric is triggered, and two new instances will be launched by the ASG
EC2 Auto Scaling cannot add a volume
Amazon EC2 Auto Scaling cannot add a volume (Volumne = EBS volume) to an existing instance if the existing volume is approaching capacity
A volume is attached to a new instance when it is added. Amazon EC2 Auto Scaling doesn't automatically add a volume when the existing one is approaching capacity. You can use the EC2 API to add a volume to an existing instance.
ALB removed an instance but ASG fail to provision
Let's say you're using an ALB that routes the requests to the underlying EC2 instances and you noticed a peculiar pattern. The ALB removes an instance whenever it is detected as unhealthy but the ASG fails to kick-in and provision the replacement instance. What is the reason?
If the ASG is using EC2 as the health check type and the ALB is using its in-built health check, there may be a situation where the ALB health check fails because the health check pings fail to receive a response from the instance. (Network issue) At the same time, ASG health check can come back as successful because it is based on EC2 based health check.
Therefore, in this scenario, the ALB will remove the instance from its inventory, however, the ASG will fail to provide the replacement instance. This can lead to the scaling issues mentioned in the problem statement.
Examples
Automatically recover
Imagine you are deploying a critical monolith application that must be deployed on a single web server, as it hasn't been created to work in distributed mode. Still, you want to make sure your setup can automatically recover from the failure of an AZ.
- Create an auto-scaling group that spans across 2 AZ, which min=1, max=1, desired=1
- Create an Elastic IP and use the EC2 user-data script to attach it
- With an Elastic IP address, you can mask the failure of an instance or software by rapidly remapping the address to another instance in your account.
- Assign an EC2 Instance Role to perform the necessary API calls
- For that Elastic IP to be attached to our EC2 instance, we must use an EC2 user data script, and our EC2 instance must have the correct IAM permissions to perform the API call, so we need an EC2 instance role.
If we use an ALB, things will still work, but we will have to pay for the provisioned ALB which sends traffic to only one EC2 instance.
Usage of lifecycle hook
As your Auto Scaling group scale-out or scale-in your EC2 instances, you may want to perform custom actions before they start accepting traffic or before they get terminated. Auto Scaling Lifecycle Hooks allow you to perform custom actions during these stages.
For example, you can add a lifecycle policy to move instances in the Terminating state to Terminating:Wait state. In this state, you can access instances before they're terminated, and then troubleshoot why they were marked as unhealthy.