Help LLM to reasoning
Chain of Thought Prompting for Improved Reasoning in LLMs
This section discusses the challenges LLMs face with complex reasoning tasks, such as multi-step math problems, and introduces a technique called chain of thought prompting to improve their performance.
Challenges with Complex Reasoning
- Reasoning Limitations: LLMs, even those that excel at many tasks, often struggle with problems that require multi-step reasoning or mathematical calculations.
- Example: When asked to solve a simple math problem about counting apples after some are used and more are bought, an LLM incorrectly concludes that 27 apples remain, when the correct answer is 9.
Introduction to Chain of Thought Prompting
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Human-like Reasoning: To help LLMs think more like humans, you can prompt them to break problems down into intermediate steps, mimicking the way humans approach problem-solving.
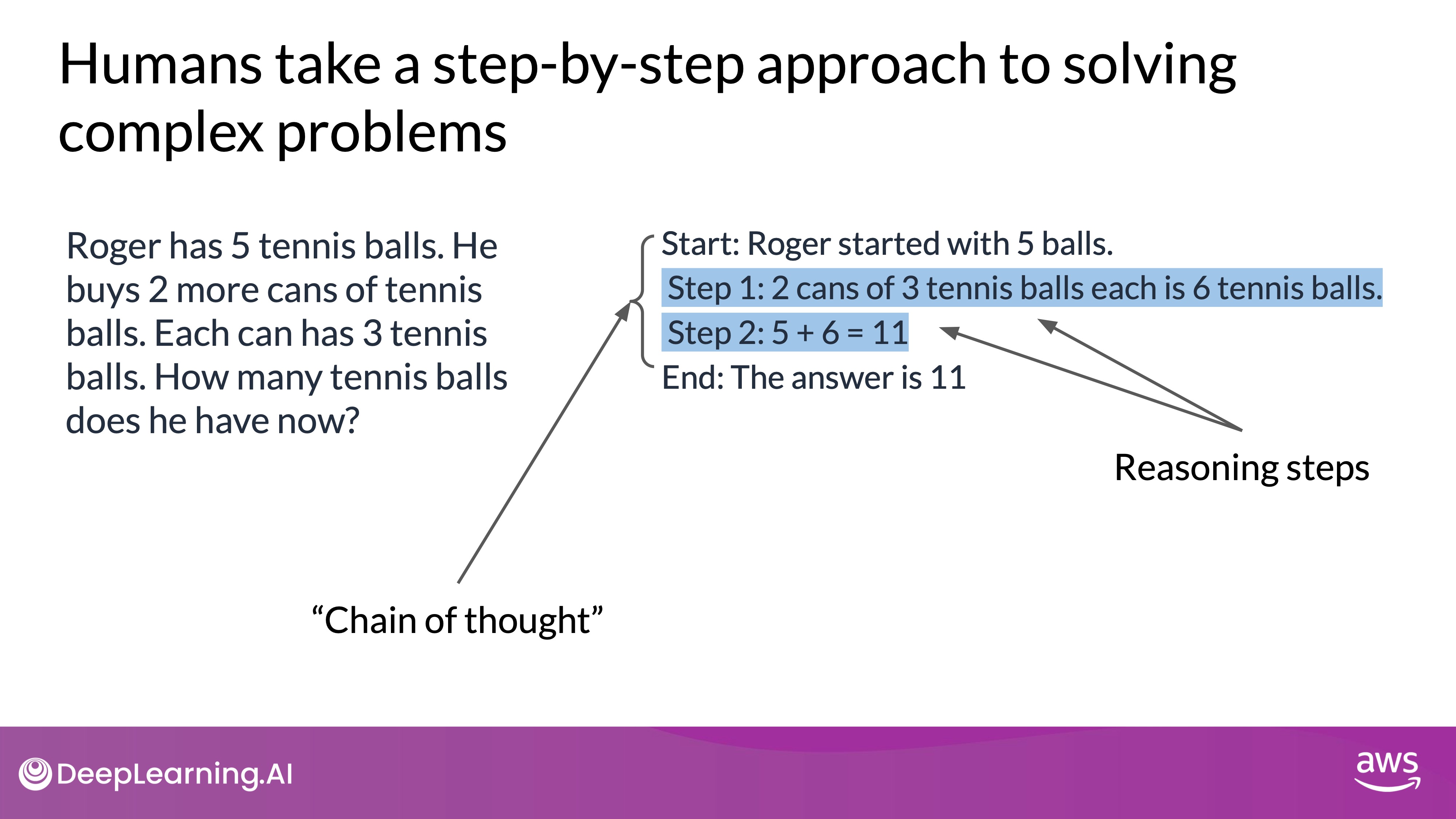
- Example of Chain of Thought: Consider a problem about calculating how many tennis balls Roger has after buying some. A human might:
- Determine the starting number of balls.
- Calculate the total number of new balls bought.
- Add the new balls to the original total.
- Arrive at the final answer.
This technique is not limited to math problems. For instance, in a physics problem asking whether a gold ring would sink in water, the LLM can reason through the problem by comparing densities, leading to the correct conclusion that the ring would sink.
Despite improvements, LLMs still struggle with precise calculations, which can be problematic in tasks requiring accurate math, such as like totaling sales on an e-commerce site, calculating tax, or applying a discount.
PAL is a technique to explore involves enabling LLMs to interact with external programs that are more adept at mathematical operations, helping to overcome these limitations.
Program-Aided Language Models (PAL) for Accurate Calculations
TL;DR - Program-aided Language (PAL) models are designed to assist programmers in writing code using natural language interfaces. They aim to facilitate the coding process by providing support and guidance through human-like interactions. It offloads these tasks to a runtime symbolic interpreter such as a python function, which reduces the workload for the LLM and improves accuracy as symbolic interpreters tend to be more precise with computational tasks.
This section discusses the limitations of large language models (LLMs) in handling arithmetic and other mathematical operations, and introduces the Program-Aided Language Models (PAL) framework as a solution to improve accuracy by leveraging external code interpreters.
LLMs often struggle with performing accurate mathematical operations, especially when dealing with large numbers or complex calculations. This is because LLMs are designed to predict the most probable tokens based on training data rather than performing actual arithmetic. Even when using chain of thought prompting, where the model reasons through the steps of a problem, it can still arrive at incorrect results due to its inherent limitations in handling math.
Introducing PAL (Program-Aided Language Models)
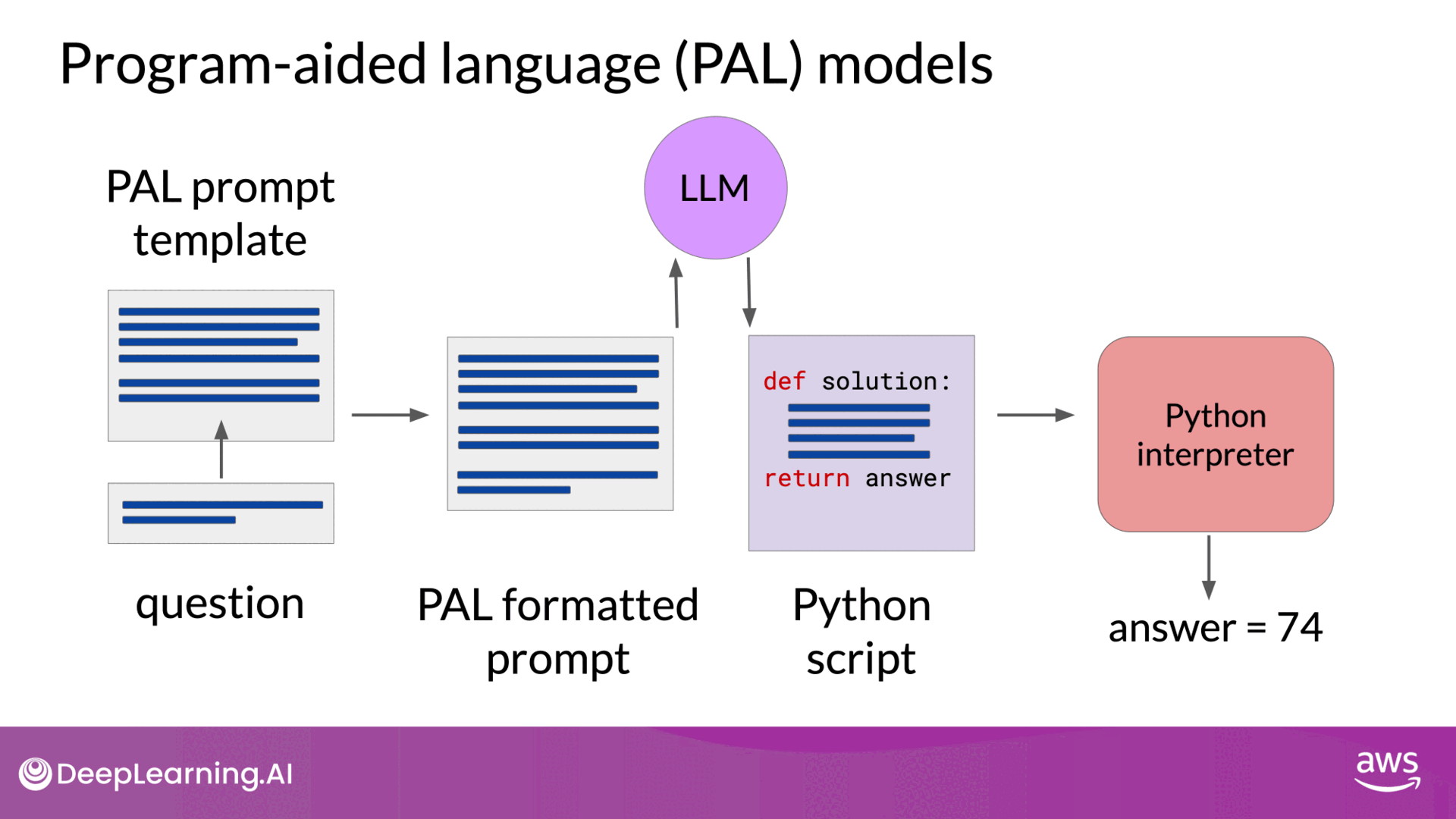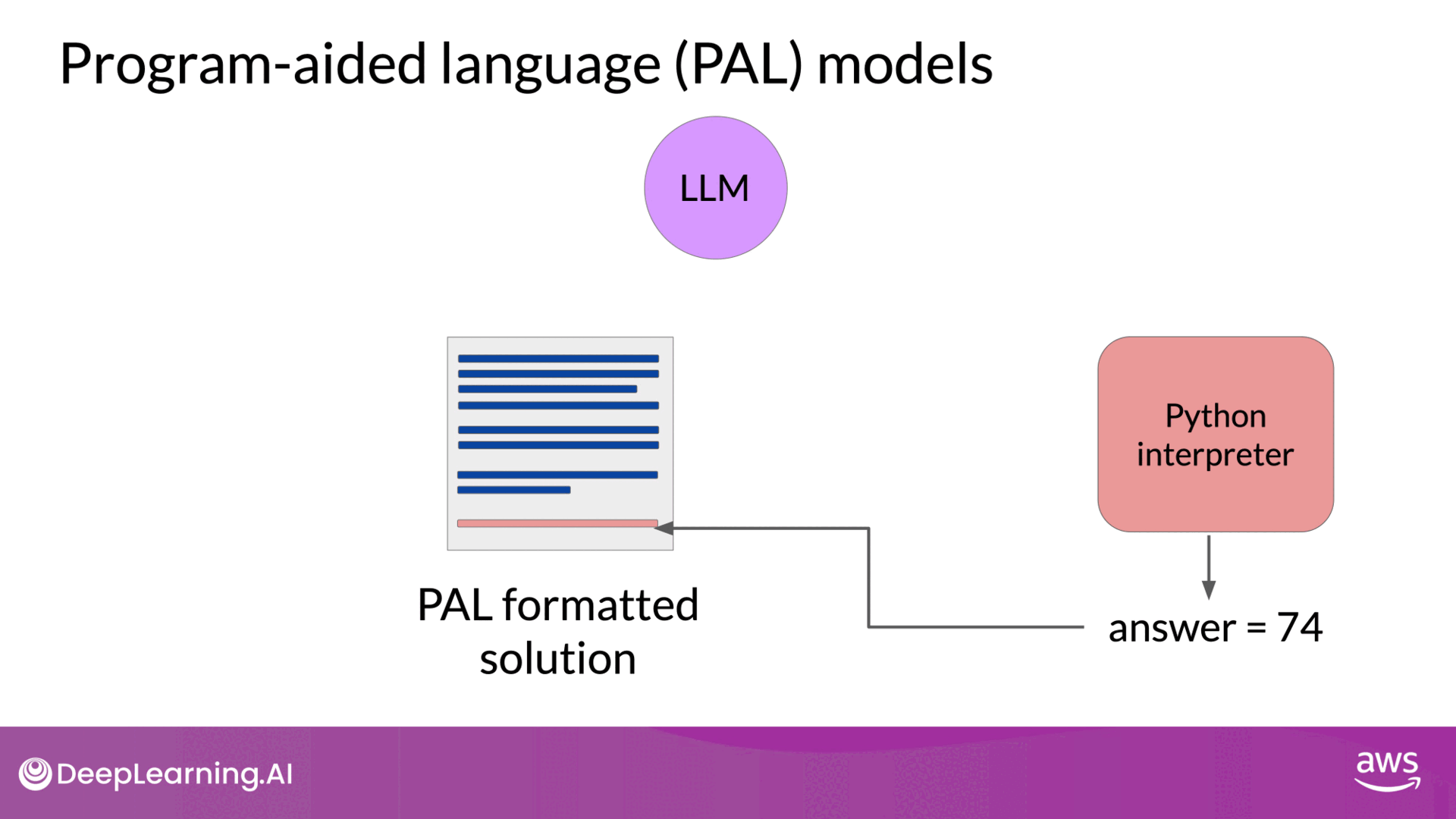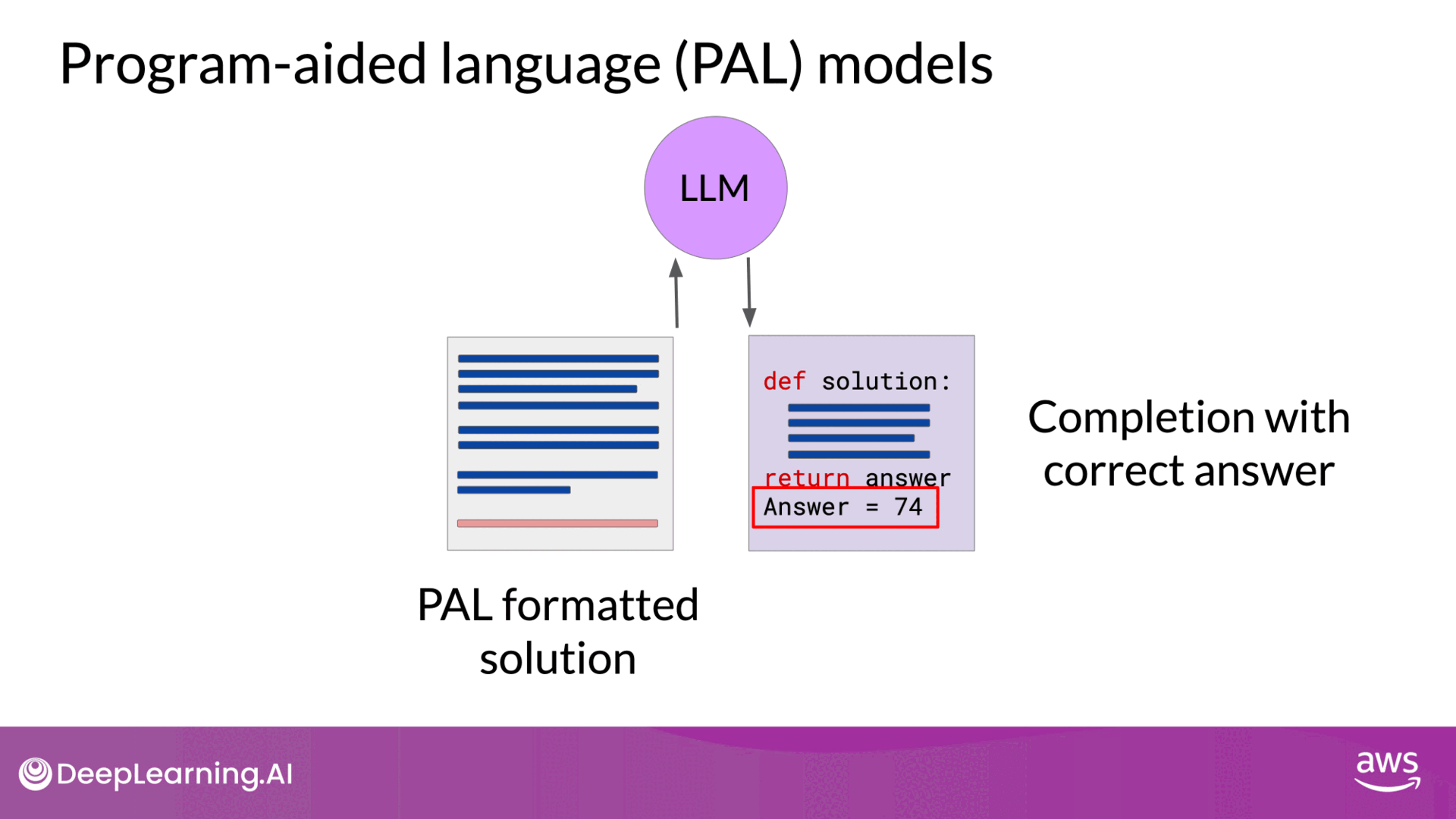
PAL is a technique where an LLM is paired with an external code interpreter (like a Python interpreter) to handle calculations accurately. This method was developed to overcome the mathematical limitations of LLMs by generating executable code that performs the required operations. How PAL Works:
- Chain of Thought Prompting: The LLM is prompted using chain of thought examples that include not only reasoning steps but also lines of executable Python code.
- Code Generation: The LLM generates a completion that includes both the reasoning and the corresponding Python code for each calculation.
- Code Execution: The generated code is passed to a Python interpreter, which executes the code to produce the correct answer.

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Prompt Structure: Consider a problem where a bakery needs to calculate how many loaves of bread remain after a day of sales and returns. The prompt includes an example where Roger buys tennis balls, and the reasoning is broken down into steps with corresponding Python code.
- Code Execution: The LLM generates a Python script that calculates the correct number of remaining loaves by tracking variables such as the number of loaves baked, sold, and returned. The code is then executed by the interpreter to ensure the correct result.
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
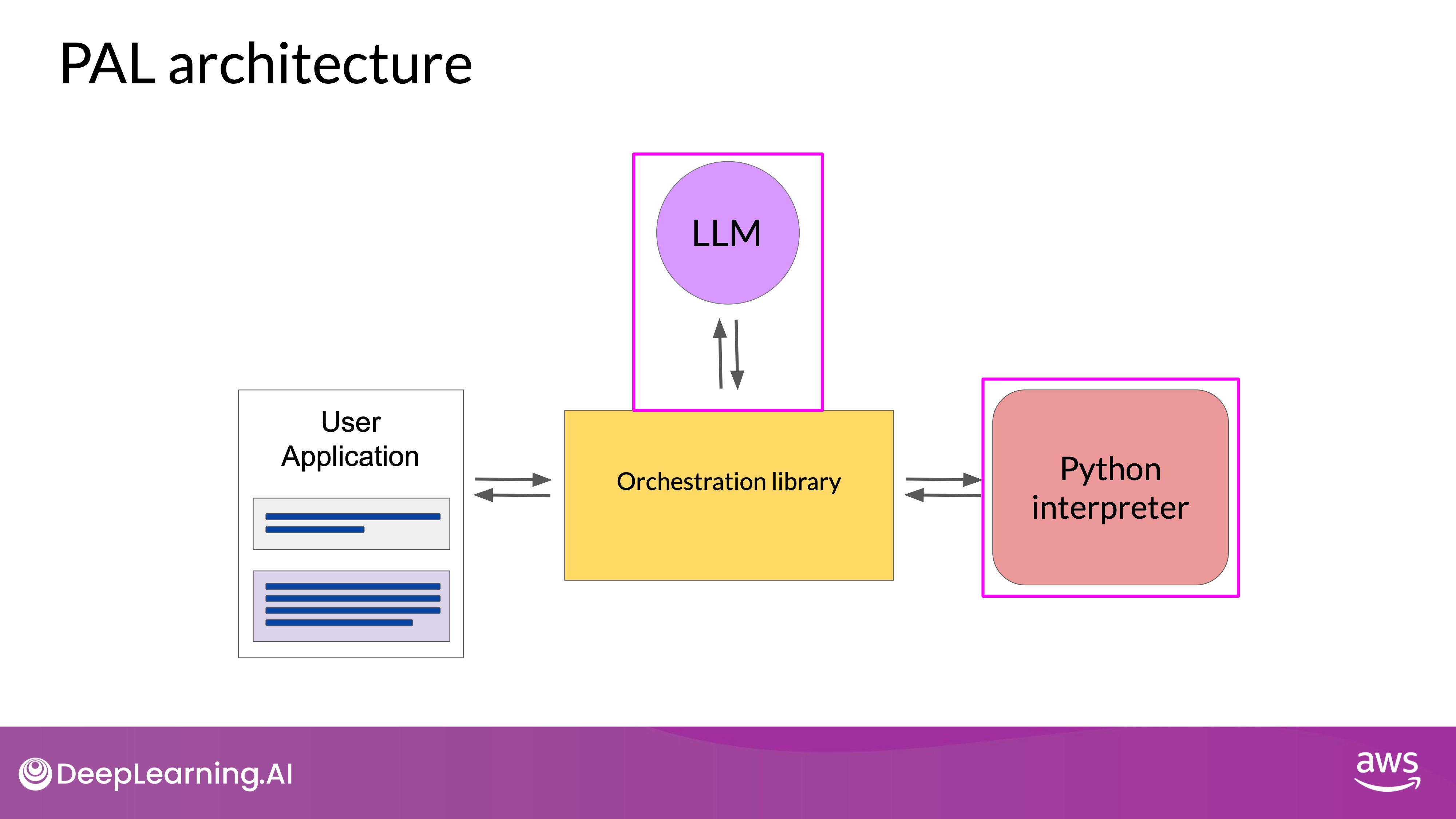
Automating the Process with an Orchestrator
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
In simpler math problems, the model might get the answer right using chain of thought prompting. However, for more complex math, like large number arithmetic, trigonometry, or calculus, PAL ensures accurate and reliable calculations. To automate this process and avoid manual data transfer between the LLM and interpreter, the orchestrator you saw earlier becomes essential.
- Orchestrator Role: The orchestrator is a technical component that automates the flow of information between the LLM and external applications like a Python interpreter. It manages calls to the interpreter, processes the outputs, and ensures that the correct actions are taken based on the LLM’s plan.
- Simplifying Complex Applications: While PAL focuses on executing Python code, real-world applications may involve multiple decision points, interactions with various data sources, and more complex logic. The orchestrator handles these complexities, enabling the LLM to power more sophisticated applications.
ReAct Framework
The ReAct framework is a method designed to enhance the capabilities of large language models (LLMs) by integrating reasoning and action planning, addressing a critical gap in traditional LLM functionalities. Developed by researchers at Princeton and Google in 2022, ReAct was tested using problems from benchmarks like Hot Pot QA and FEVER.
Unlike simple tasks that LLMs can handle in one step, many real-world applications involve multiple steps and interactions with external data sources or applications. The ReAct framework helps LLMs navigate these complexities by breaking down the problem-solving process into structured, manageable parts. This is achieved through a cycle of reasoning (thought), executing actions (action), and integrating new information (observation), which the model repeats until it arrives at a solution.
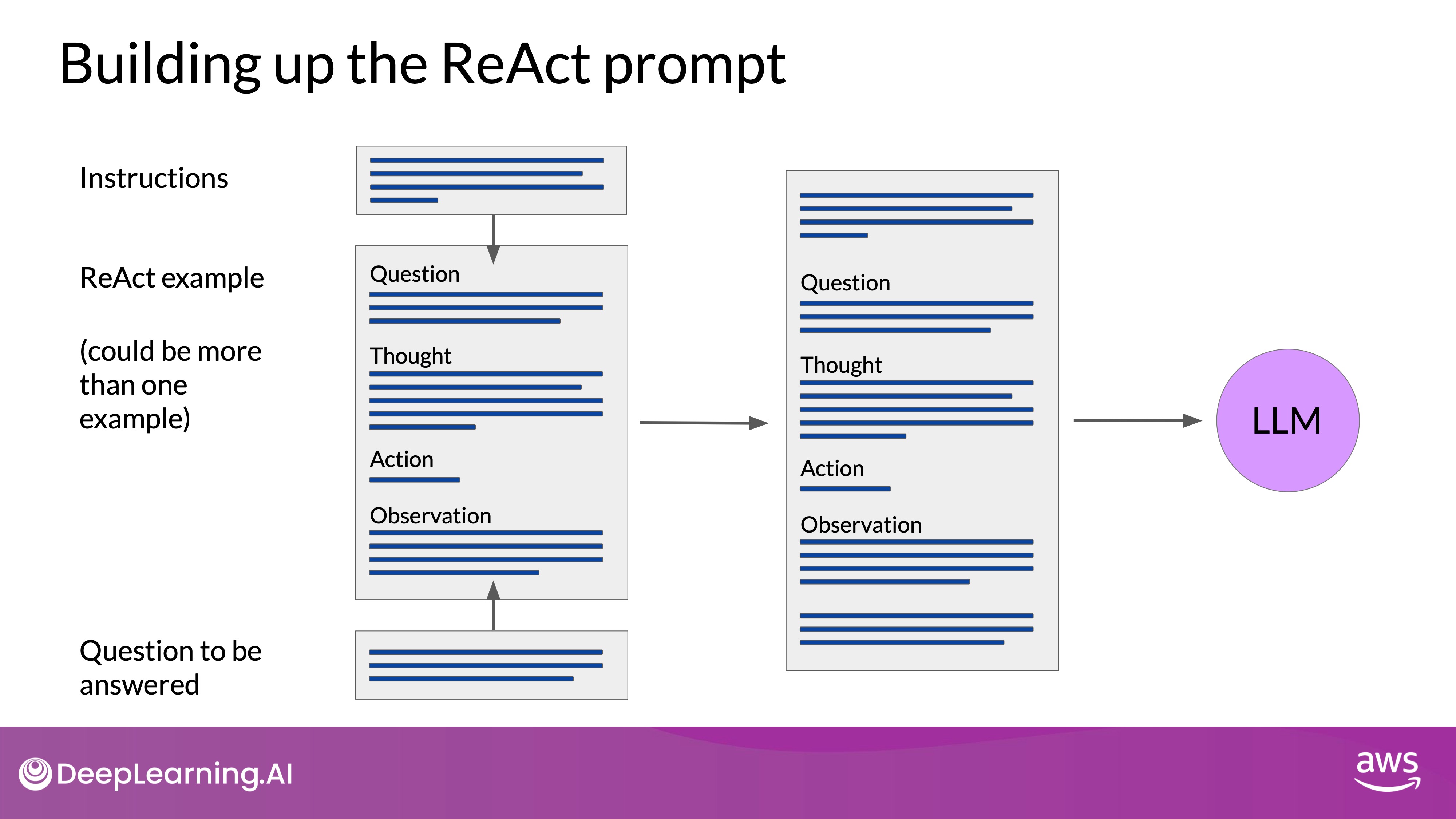
Structured Prompts and Pre-pended Instructions
- Task Definition: The ReAct framework relies on clear instructions pre-pended to the prompt, which define the task and outline the model's expected actions. This helps the LLM understand the scope of the task and what it needs to accomplish.
- Allowed Actions: To keep the model's actions within the bounds of what the application can execute, a predefined set of allowed actions is provided. For instance, the model might be restricted to actions like "search," "lookup," and "finish," each corresponding to specific operations the application can perform.
- Maintaining Focus: These pre-pended instructions also help maintain the model's focus, ensuring that it stays on task and doesn't generate irrelevant or unfeasible actions. By limiting the LLM's creativity to predefined, actionable steps, the framework ensures that the model's outputs are both relevant and executable.

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Search: The model can search an external database or resource, such as Wikipedia, to find relevant information.
- Lookup: The model can retrieve specific details from within a document or dataset, such as finding a particular date or fact within a text.
- Finish: The model can conclude the process and return the final answer to the user, signaling that it has gathered enough information to make a decision.
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- You start with the ReAct example prompt. Note that depending on the LLM you're working with, you may find that you need to include more than one example and carry out future inference.
- You'll pre-pend the instructions at the beginning of the example and then insert the question you want to answer at the end.
- The full prompt now includes all of these individual pieces, and it can be passed to the LLM for inference.
ReAct Example
In this example, the task is to determine which of two magazines—Arthur's Magazine or First for Women—was published first. This problem serves as a practical demonstration of how large language models (LLMs) can be guided through complex reasoning tasks using the ReAct framework. By combining structured prompts with action planning, the LLM is able to systematically search for and analyze relevant information, ultimately arriving at the correct conclusion.

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Problem Setup: Imagine a task where the goal is to determine which of two magazines—Arthur's Magazine or First for Women—was started first. This type of question involves retrieving and comparing specific information from external sources, such as publication dates.
- Thought-Action-Observation Loop:
- Thought: The model begins by reasoning through the problem, identifying the necessary steps to solve it. For instance, it might decide that the first step is to search for the publication dates of both magazines.
- Action: Next, the model selects an appropriate action from a predefined set, such as searching a database or an external resource (like Wikipedia) for the relevant information. The action is executed according to the instructions provided in the structured prompt.
- Observation: Once the action is completed, the model integrates the new information (e.g., the publication dates retrieved) into its reasoning process. If further steps are required, the model repeats the thought-action-observation cycle until it can confidently answer the question.
- Outcome: Through this iterative process, the model accurately determines that Arthur's Magazine was created first. The ReAct framework's structured approach ensures that the model systematically gathers and evaluates information until the task is complete.
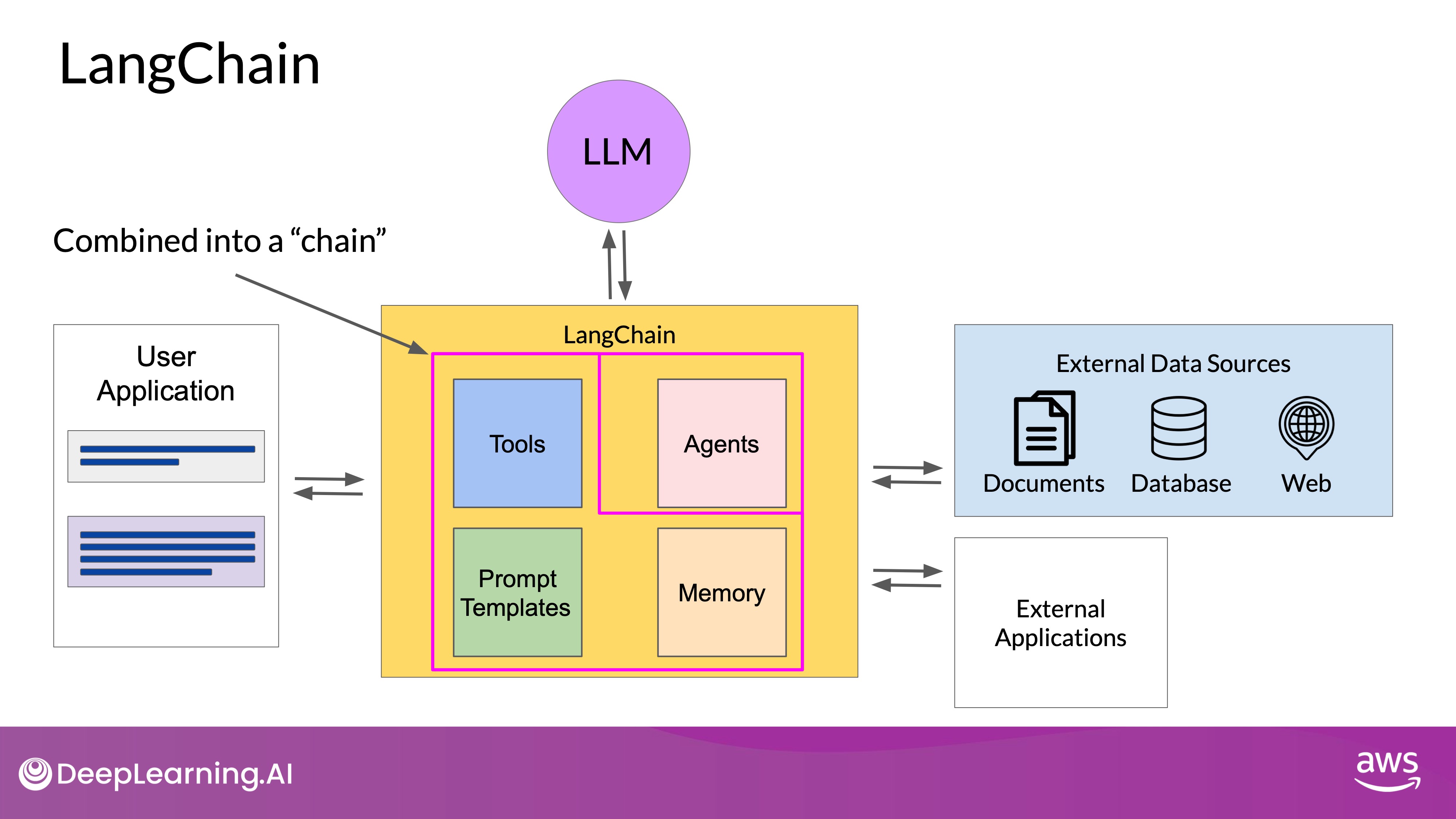
LangChain: A Framework for LLM-Powered Applications
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Introduction to LangChain:
- Purpose: LangChain is a modular framework designed to help developers build applications that leverage LLMs. It provides tools and templates for various use cases.
- Components: LangChain includes prompt templates, memory modules, and pre-built tools for tasks like API calls and data retrieval.
- Chains and Agents in LangChain:
- Chains: A chain in LangChain connects various components to execute a workflow. Predefined chains are available for common use cases, allowing for quick setup.
- Agents:
- Function: Agents in LangChain interpret user input and decide which tools or actions to use. They provide flexibility for workflows that require dynamic decision-making.
- Support for PAL and ReAct: LangChain includes agents for frameworks like PAL and ReAct, enabling the integration of reasoning and action planning into complex applications.
Considerations for Model Selection
- Model Scale and Complexity:
- Large Models Preferred: Larger LLMs generally perform better with advanced prompting techniques like PAL and ReAct, as they are more capable of handling complex reasoning and planning tasks.
- Fine-Tuning Smaller Models: Smaller models may require additional fine-tuning to understand and execute structured prompts effectively, potentially slowing down development.
- Strategy for Model Use:
- Start with Large Models: Begin development with a large model to leverage its reasoning capabilities, and collect user data during deployment.
- Transition to Smaller Models: Use the data to fine-tune a smaller model for more efficient deployment later on.
Standard, Chain-of-thought (CoT, Reason Only), Act-only, and ReAct (Reason+Act)
The figure presents a detailed visual comparison of different prompting methods across two distinct domains, showcasing the effectiveness of the ReAct (Reason + Act) framework compared to other approaches. This comparison is particularly insightful for understanding how these methods perform in complex reasoning and action scenarios.

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Domain 1: Hotpot QA (Figure 1a)
- Prompting Methods Compared:
- Standard: A straightforward approach where the model provides a direct answer without any intermediate reasoning or actions.
- Chain-of-Thought (CoT, Reason Only): The model is prompted to reason through the problem, but without taking any actions. It generates a reasoning trace that leads to an answer.
- Act-Only: The model takes actions based on predefined rules or instructions, but without any reasoning steps guiding those actions.
- ReAct (Reason + Act): Combines reasoning with action-taking. The model reasons through the problem and decides on specific actions to take based on its reasoning. This method integrates both the thought process and actionable steps, leading to a more informed and accurate solution.
- Task-Solving Trajectories:
- The figure illustrates the sequence of steps (thoughts and actions) that each method uses to solve a question from the Hotpot QA dataset. For example, the ReAct method shows a sequence where the model first reasons about the problem (Thought), then takes an action (Act) such as searching for specific information, and finally makes an observation (Obs) based on the results of that action. This cycle continues until the model reaches a correct and confident conclusion.
- Outcome: The ReAct method outperforms the others by correctly identifying the keyboard function keys as the answer, while other methods like Standard and CoT fail to reach the correct conclusion due to a lack of integrated reasoning and action steps.
Domain 2: AlfWorld (Figure 1b)
- Prompting Methods Compared:
- Act-Only: The model performs actions in a simulated environment (AlfWorld) based on predefined rules, without any reasoning guiding those actions.
- ReAct (Reason + Act): Similar to the Hotpot QA domain, this method combines reasoning with action. The model thinks through the problem (e.g., finding a pepper shaker), decides on the appropriate actions (e.g., where to look for the shaker), and then performs those actions in the environment.
- Task-Solving Trajectories:
- The ReAct method demonstrates a more thoughtful and systematic approach to solving the problem. For instance, the model first reasons about the most likely locations of a pepper shaker, takes actions to search those locations, and then updates its strategy based on what it observes in the environment.
- Outcome: The ReAct method successfully completes the task of finding and placing the pepper shaker in the correct location, while the Act-Only method fails due to the lack of integrated reasoning steps that would guide the model's actions effectively.
Insights and Latest Trends
- Integration of Reasoning and Action: The figure highlights the growing trend in AI research to combine reasoning and action in language models. The ReAct framework exemplifies this trend by showing how integrating these two components can significantly improve performance in tasks that require complex decision-making and problem-solving.
- Advantages of ReAct: The ReAct method not only enhances the model’s ability to perform tasks accurately but also improves the interpretability of the model's decision-making process. By making the reasoning process explicit and combining it with actionable steps, ReAct allows users to trace the model's thought process, making it easier to diagnose errors or understand the model’s behavior.
- Real-World Applications: The success of the ReAct framework in both Hotpot QA and AlfWorld demonstrates its potential for real-world applications where LLMs need to interact with dynamic environments or solve problems that require both thought and action. This approach is likely to be influential in the development of next-generation AI systems that are capable of more human-like reasoning and decision-making.
This expanded explanation clarifies how the ReAct framework stands out from other methods and underscores the importance of integrating reasoning with action in the development of more advanced and reliable AI systems.