PEFT (Parameter efficient fine-tuning)
Intro
Source: Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
PEFT can reduce the amount of compute required to finetune a model. There are 2 two methods you can use for this LoRA and Prompt Tuning.
Prompt tuning and LoRA are effective PEFT methods. Prompt tuning adds trainable tokens to the input prompt, optimizing task performance with minimal compute resources, while LoRA updates model parameters using low-rank matrices. Both methods enable efficient fine-tuning, making large models adaptable to various tasks with reduced computational demands.
Training large language models (LLMs) is highly computationally intensive, requiring substantial memory for storing model weights and additional parameters during the training process. Full fine-tuning, where every model weight is updated, demands significant memory resources, often exceeding the capabilities of consumer hardware. In contrast, Parameter Efficient Fine-tuning (PEFT) offers a more manageable approach by updating only a small subset of parameters, significantly reducing memory requirements.

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Benefits of PEFT
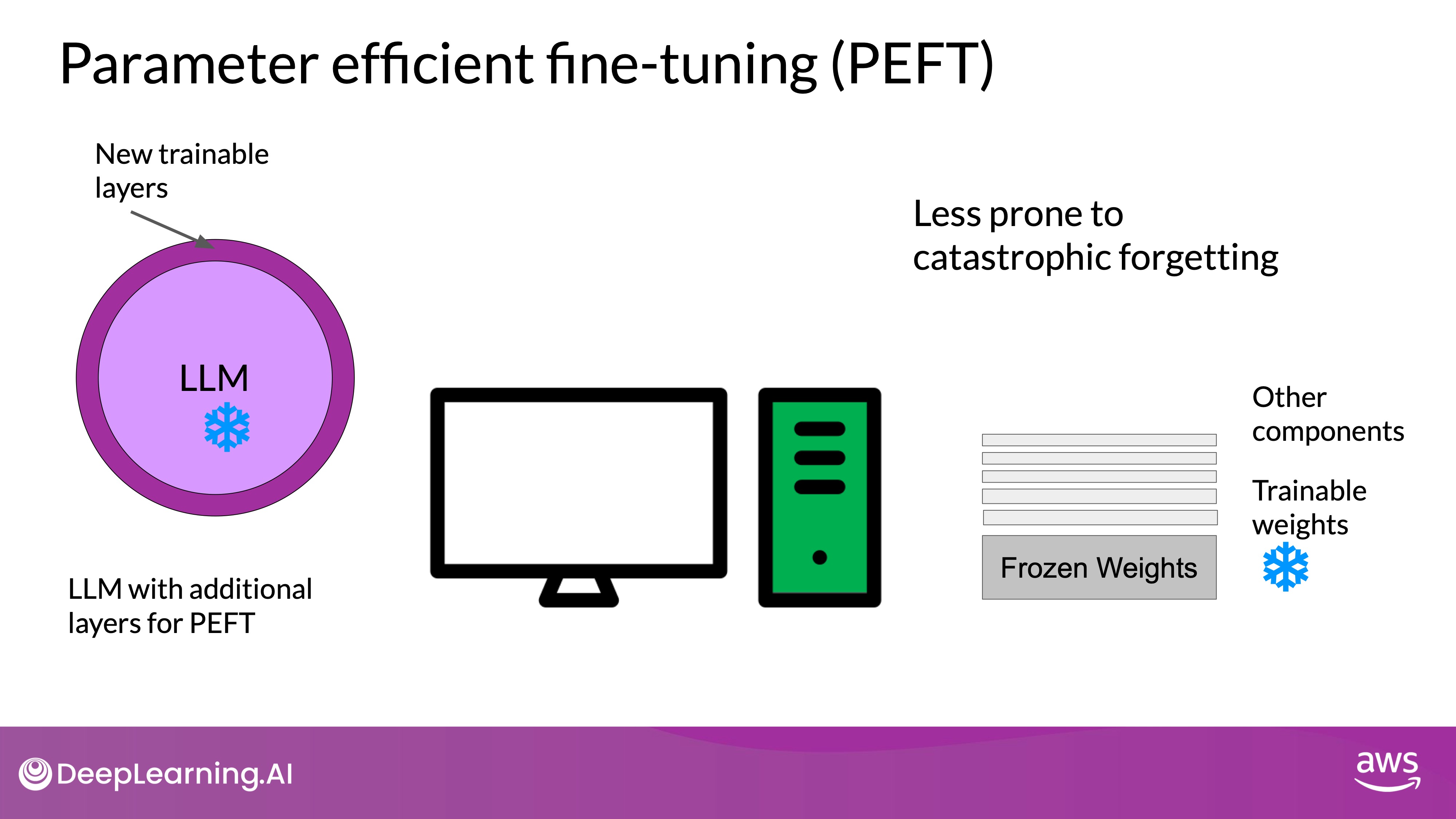
In contrast to full fine-tuning, which updates all model weights, parameter efficient fine-tuning (PEFT) methods update only a small subset of parameters. Some PEFT techniques freeze most of the model weights and fine-tune specific layers or components, while others add a small number of new parameters or layers and fine-tune only the new components. This approach keeps most LLM weights frozen, reducing the number of trained parameters to just 15-20% of the original, making training more memory-efficient and often feasible on a single GPU. Additionally, PEFT is less prone to catastrophic forgetting compared to full fine-tuning.
- Freeze model weights
- Add a small number of new parameters or layers

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Catastrophic forgetting is a common problem in machine learning where a model forgets previously learned information upon learning new tasks. PEFT helps mitigate this issue by preserving the majority of the original model's weights. Since the core of the model remains unchanged, the knowledge retained in those frozen weights is preserved, reducing the risk of forgetting previously learned information. This is particularly advantageous when a model needs to perform well on multiple tasks simultaneously.
Methods of PEFT
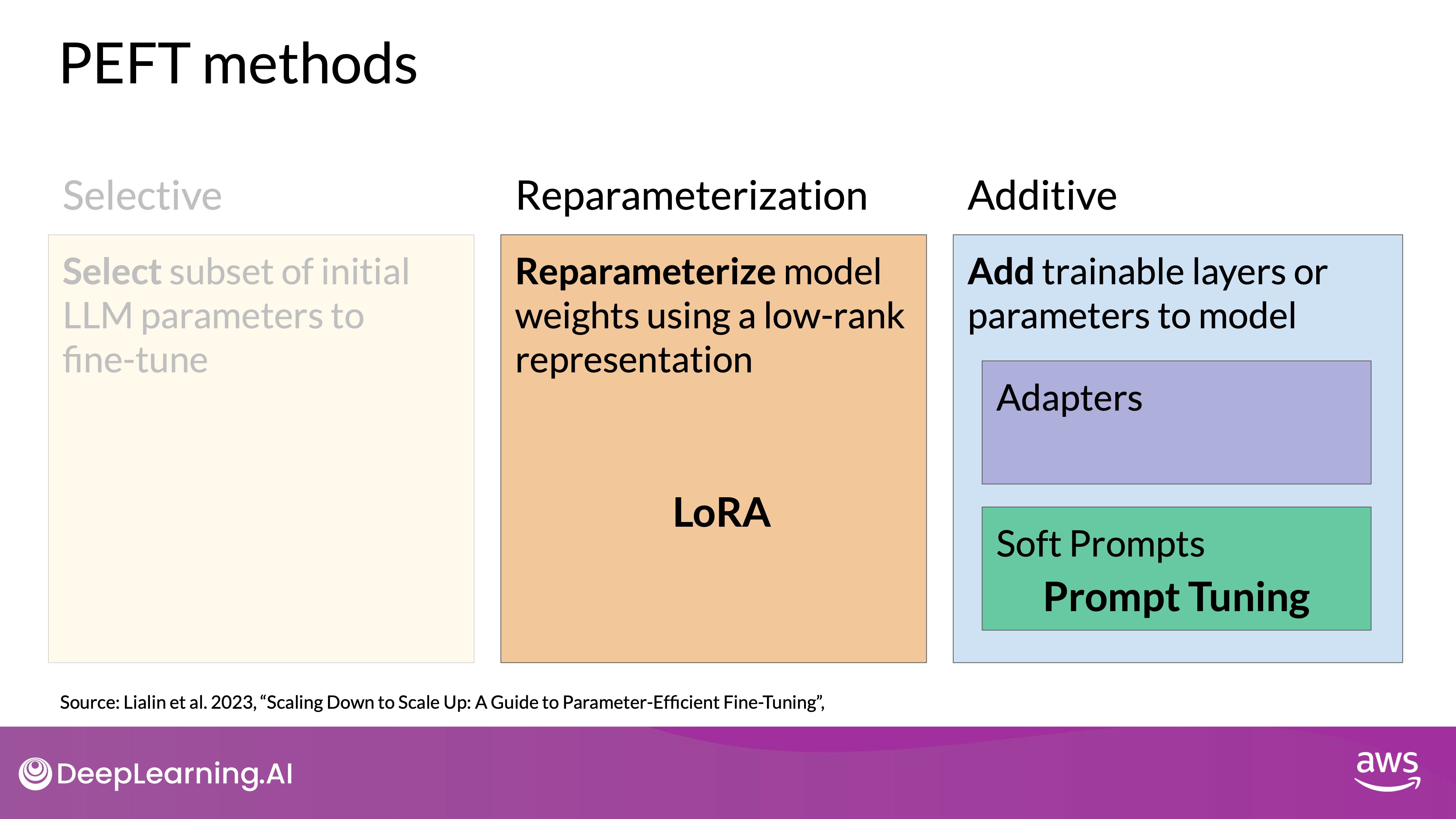
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
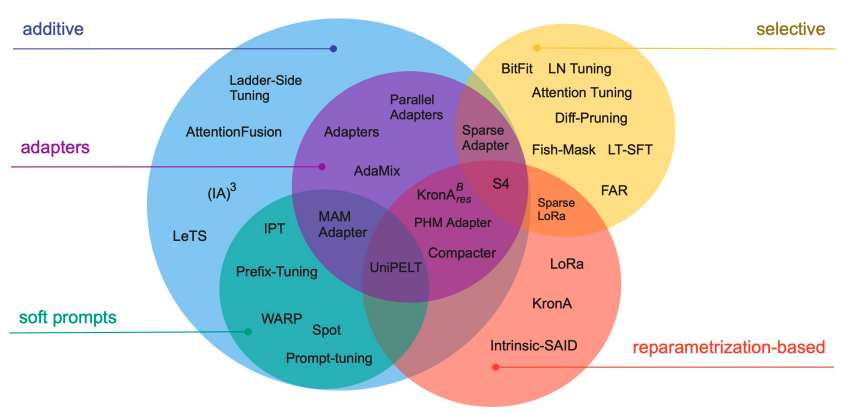
- Selective Methods: These methods fine-tune only certain components or layers of the original LLM. While they offer parameter efficiency, the performance can vary, and there are trade-offs with compute efficiency.
- Reparameterization Methods: These methods, like LoRA (Low-Rank Adaptation), create new low-rank transformations of the original network weights, reducing the number of parameters needed for training. LoRA will be explored in detail in subsequent lessons.
- Additive Methods: These methods keep all original LLM weights frozen and introduce new trainable components. Two main approaches are:
- Adapter Methods: Add new trainable layers to the model architecture, typically inside encoder or decoder components after the attention or feed-forward layers.
- Soft Prompt Methods: Manipulate the input to achieve better performance by adding trainable parameters to the prompt embeddings or retraining the embedding weights.
- Prompt Tuning is a method where the model's input prompt is modified by adding trainable embeddings. These embeddings are adjusted during training to improve the model's performance on specific tasks. The original model architecture remains unchanged, and the prompt embeddings are trained to guide the model more effectively.
- Prefix Tuning involves adding a sequence of trainable embeddings to the beginning of each layer's input sequence. Unlike prompt tuning, which modifies only the input layer, prefix tuning adjusts the input at multiple layers within the model.
Practical Application of PEFT
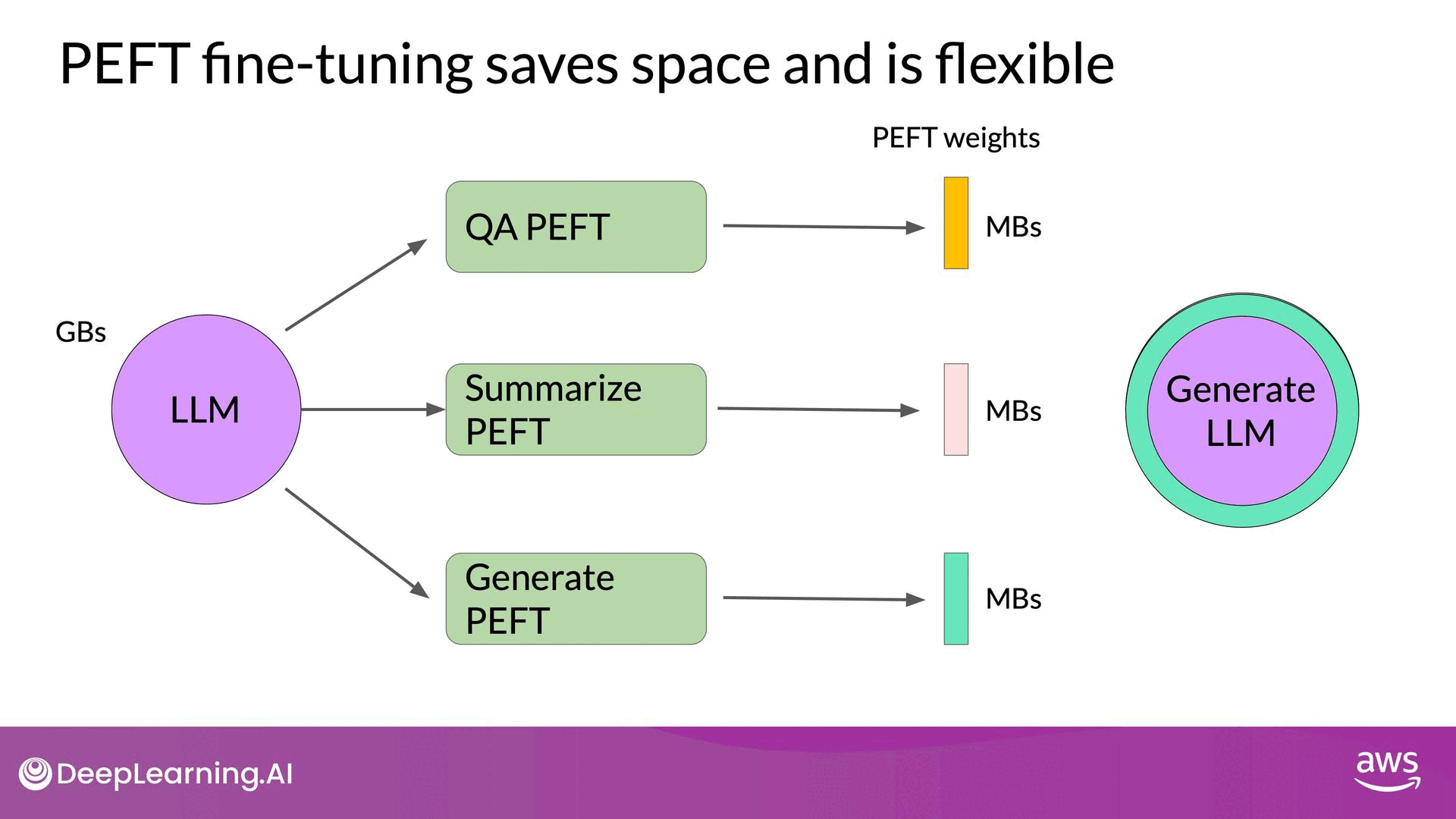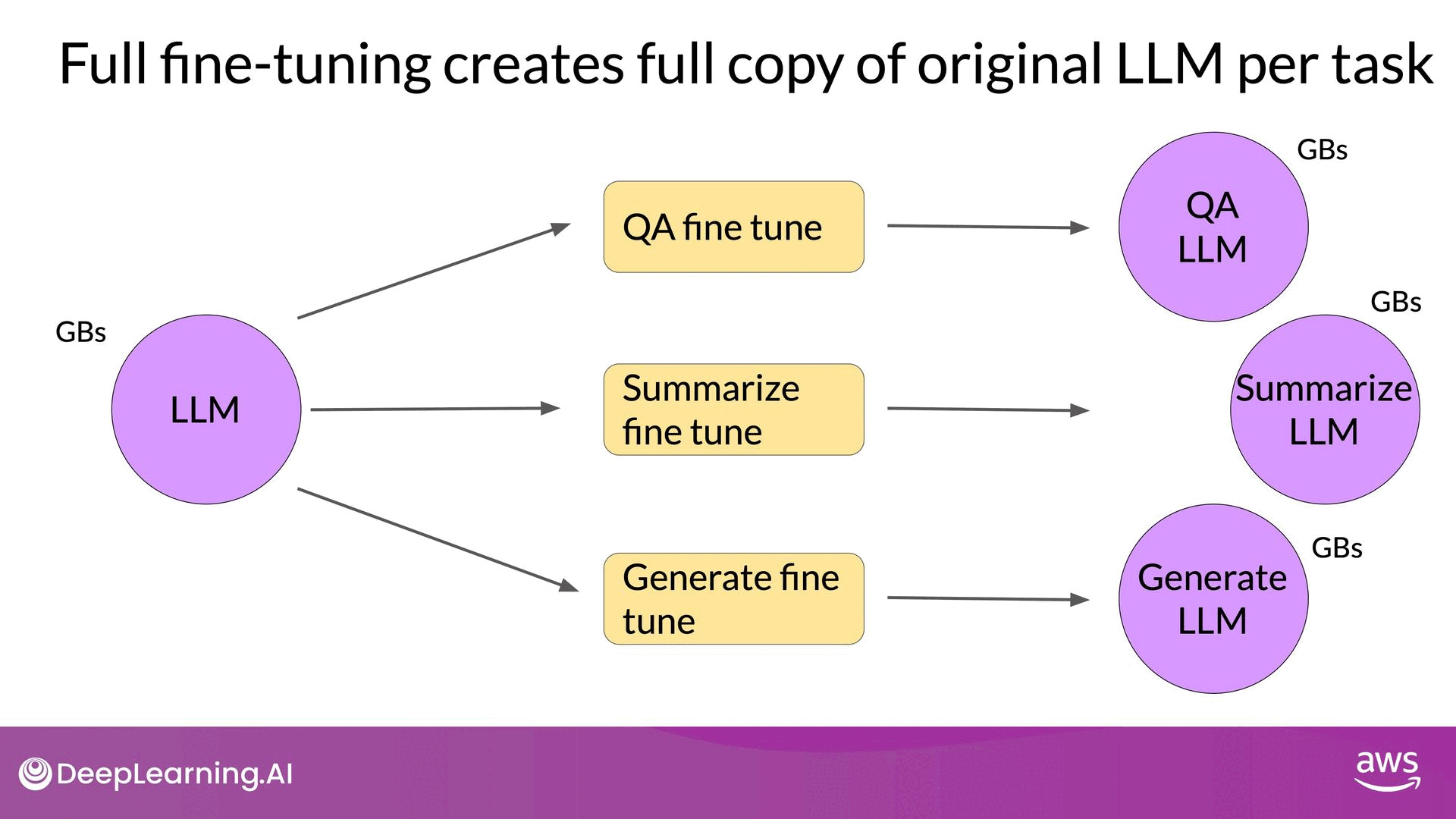
PEFT allows efficient adaptation of LLMs to multiple tasks by training only a small number of weights, resulting in a smaller overall footprint. The new parameters can be combined with the original LLM weights for inference and easily swapped for different tasks. This flexibility makes PEFT a practical solution for fine-tuning LLMs across various applications while managing memory and computational resources effectively.
In the next video, the course will delve into the LoRA method, showcasing how it reduces the memory required for training. This method exemplifies the principles of PEFT, providing a practical approach to handling the computational demands of fine-tuning large language models.
Reparameterization: LoRA
TL;DR - With LoRA, the goal was to find an efficient way to update the weights of the model without having to train every single parameter again.
Low-Rank Adaptation (LoRA) is a powerful fine-tuning method that maintains performance while significantly reducing computational and memory requirements. It is useful not only for training LLMs but also for models in other domains.
How LoRA Works
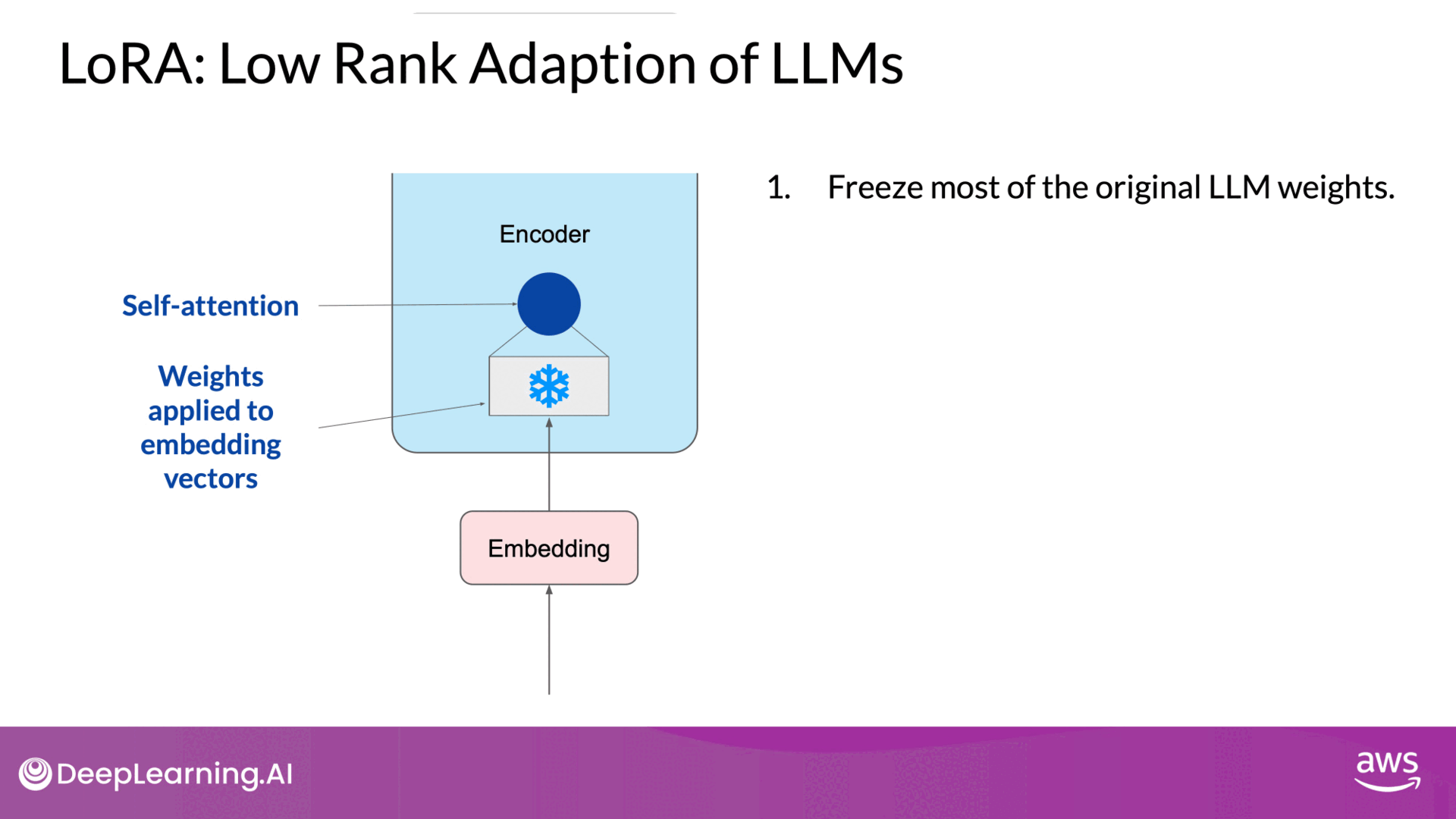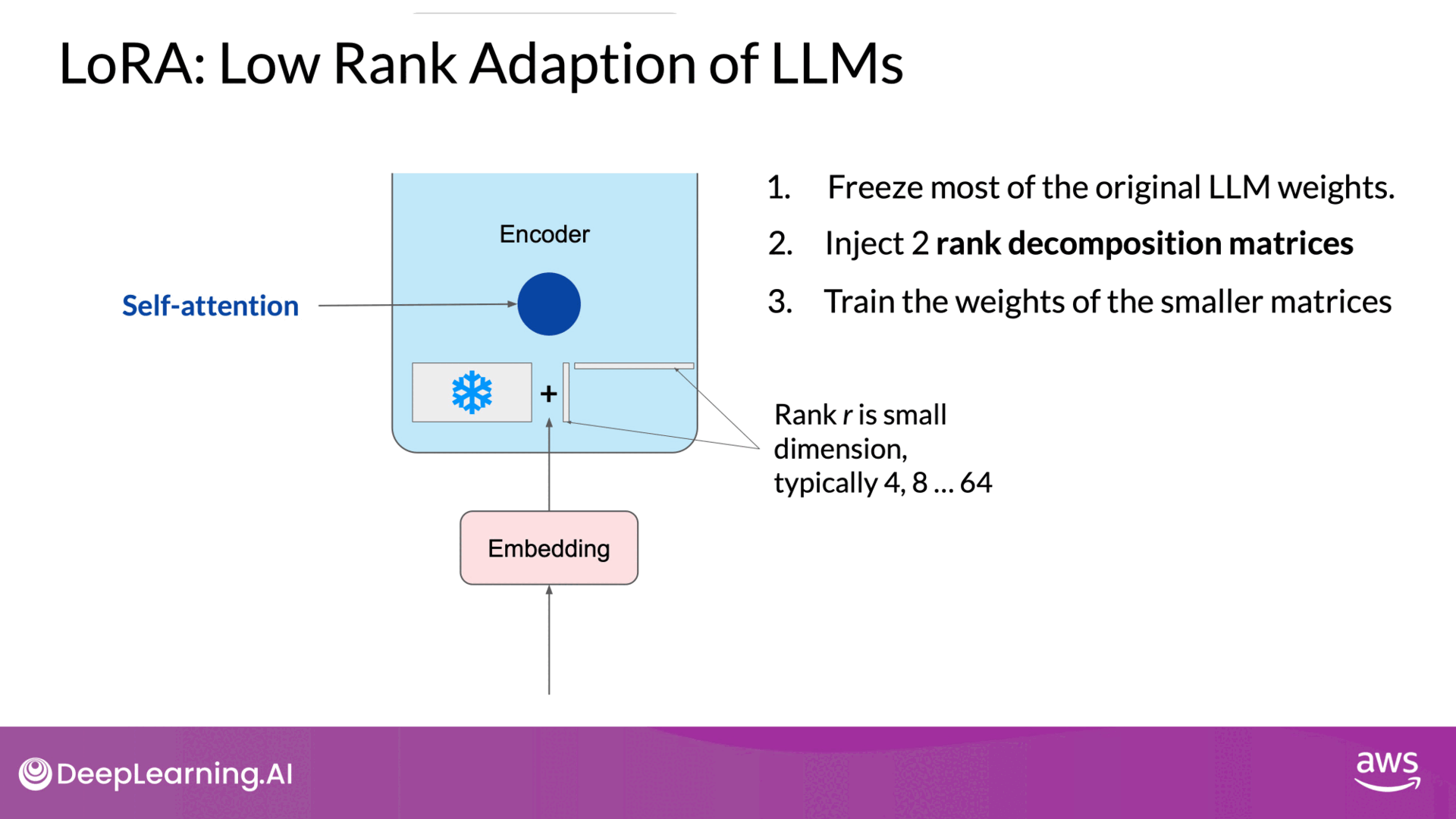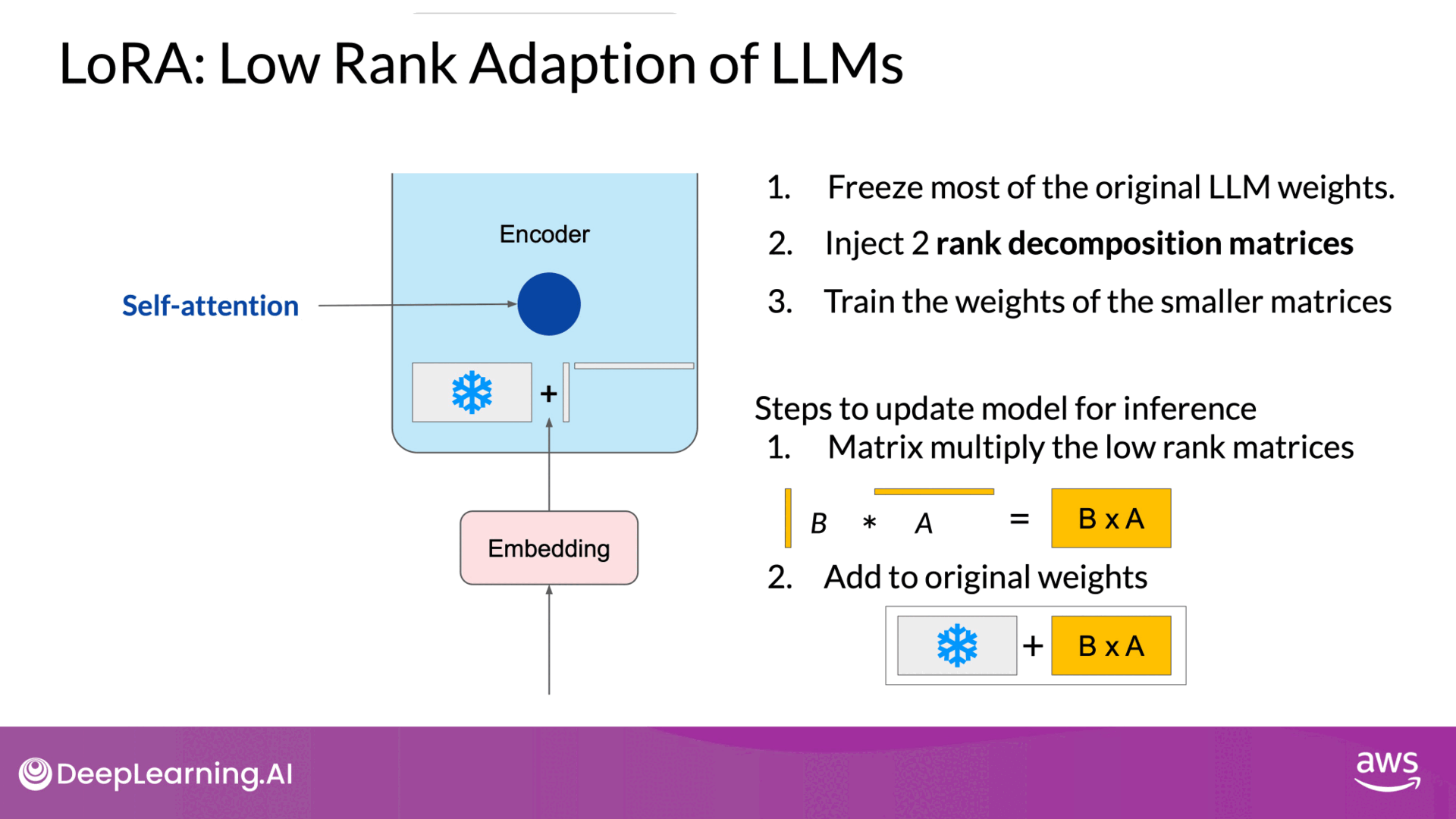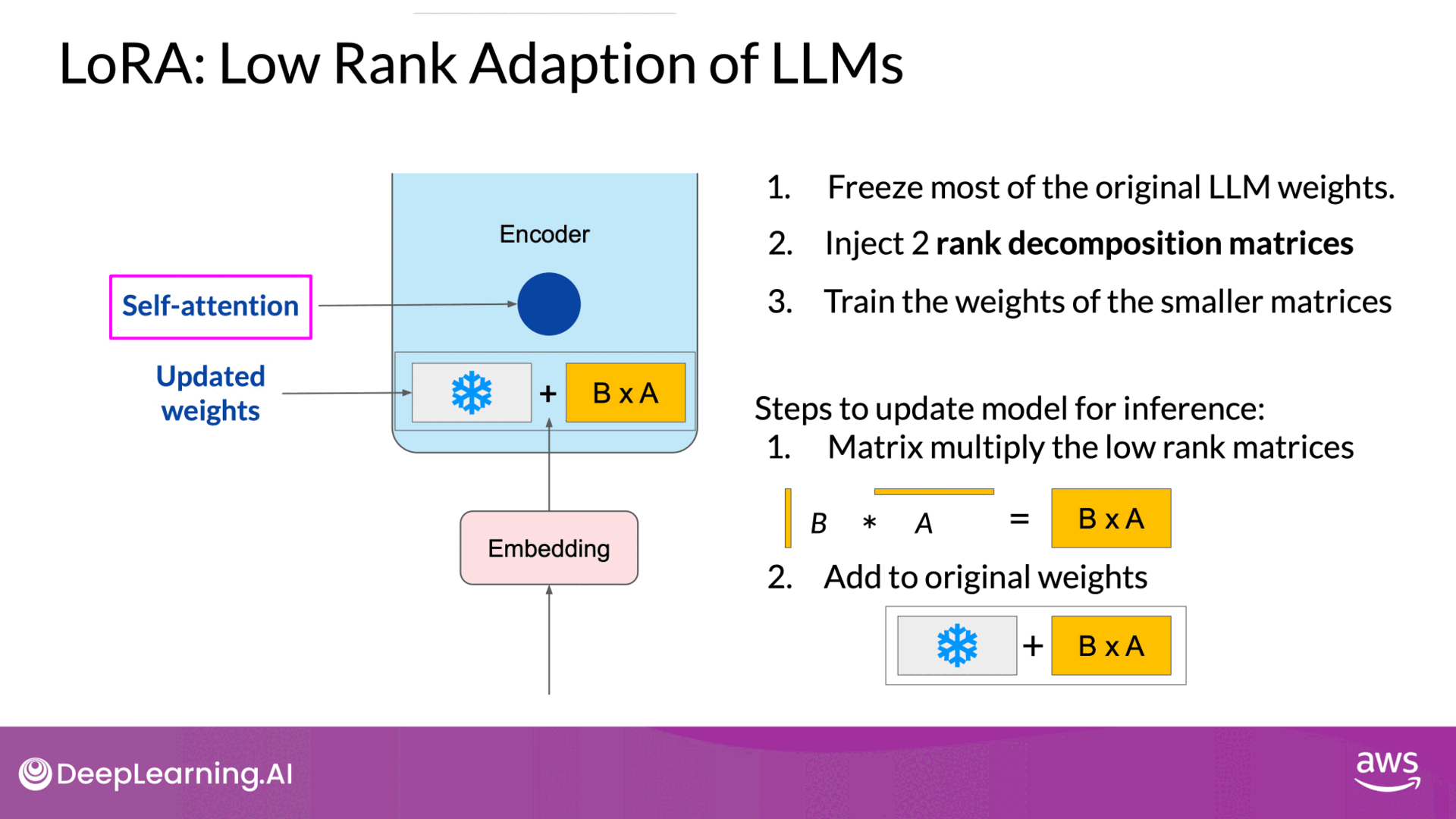
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Transformer Architecture: In transformers, input prompts are tokenized and converted to embedding vectors, which are then processed through self-attention and feedforward networks.
- Freezing Original Weights:
- LoRA freezes all original model parameters
- introduces 2 rank decomposition matrices alongside the original weights.The dimensions of the smaller matrices are set so that their product is a matrix with the same dimensions as the weights they're modifying.
- Low-Rank Matrices:
- These decomposition matrices are smaller, and their product matches the dimensions of the original weights.
- You then keep the original weights of the LLM frozen and train the smaller matrices using the same supervised learning process
- Inference:
- For inference, the two low-rank matrices are multiplied together to create a matrix with the same dimensions as the frozen weights.
- Add the matrix to the original weights and replace them in the model with these updated values.
Researchers have discovered that applying LoRA (Low-Rank Adaptation) to the self-attention layers of a model is often sufficient to fine-tune it for specific tasks and achieve significant performance improvements. Although LoRA can theoretically be applied to other components, such as the feed-forward layers, it is most beneficial when used on the attention layers. This is because the majority of a model's parameters are located in the attention layers, and focusing on these layers provides the greatest reduction in the number of trainable parameters.
How much space LoRA can save?
- Transformer Weights: If the transformer weights have dimensions() of 512 by 64, resulting in 32,768 parameters.
- LoRA Matrices: Using a
rankof 8, you create two smaller matrices:- Matrix A ():
- Matrix B ():
- Reduction: This reduces the trainable parameters from 32,768 to 4,608(), an 86% reduction.
Use LoRA for training different tasks
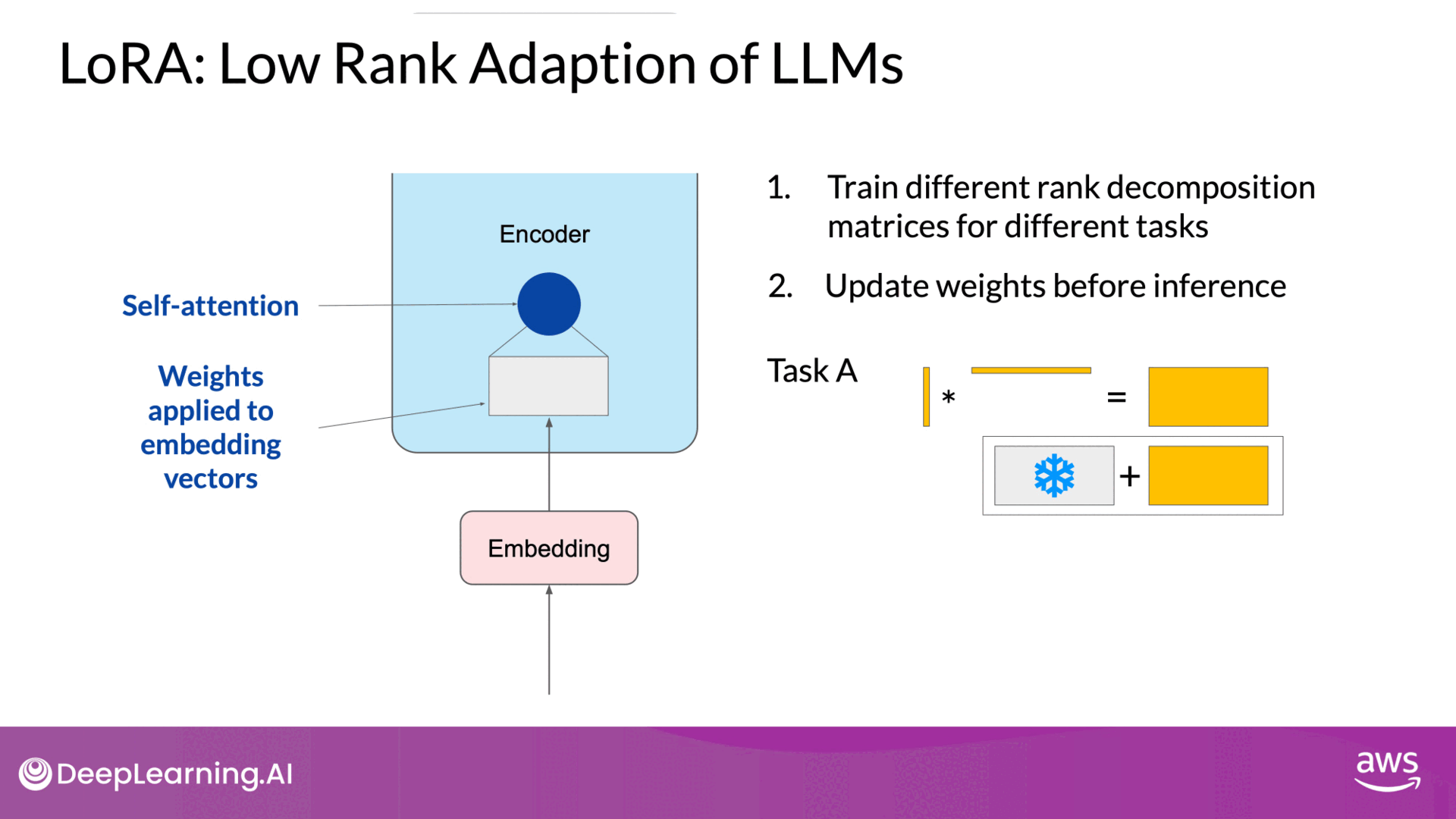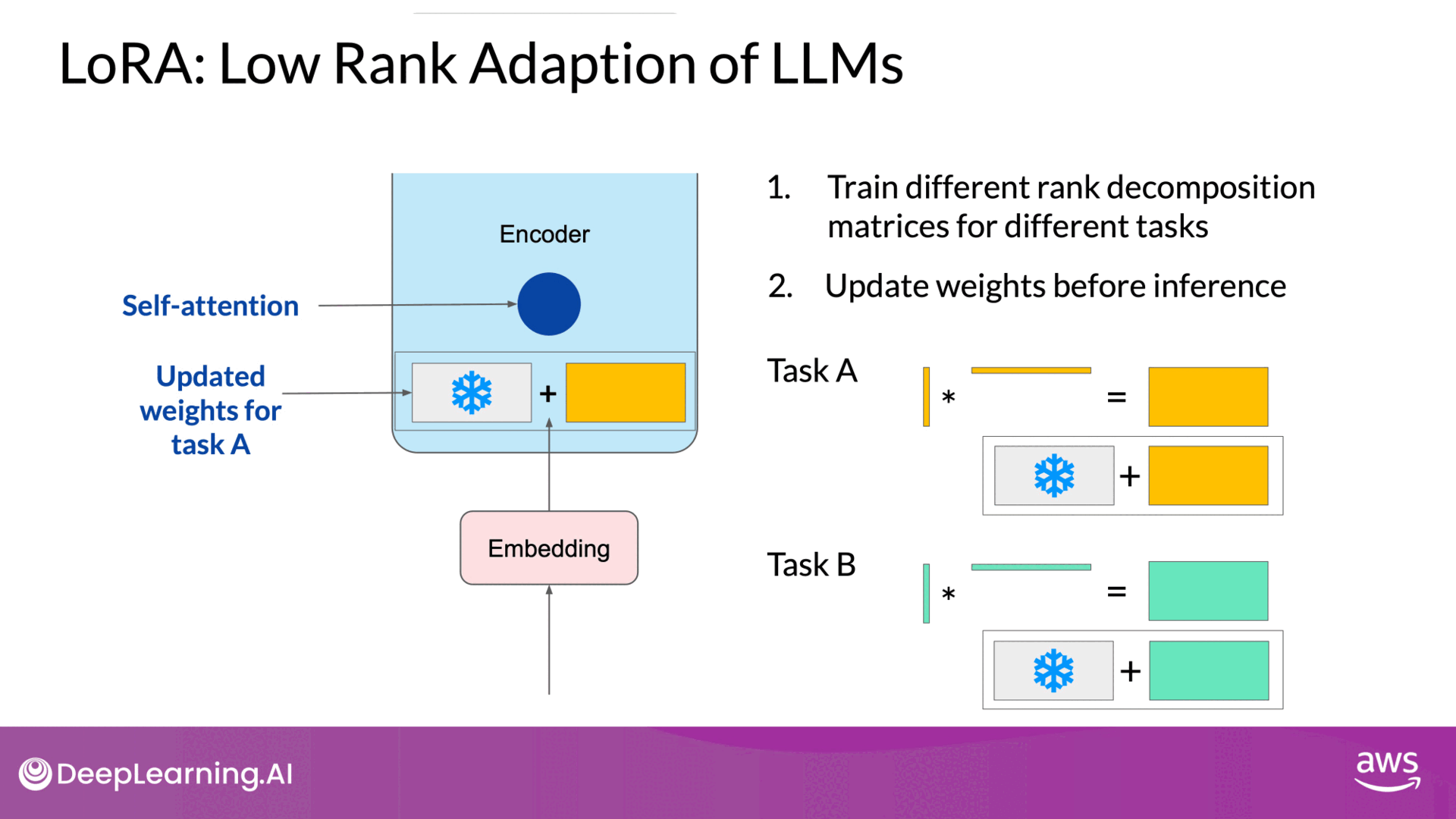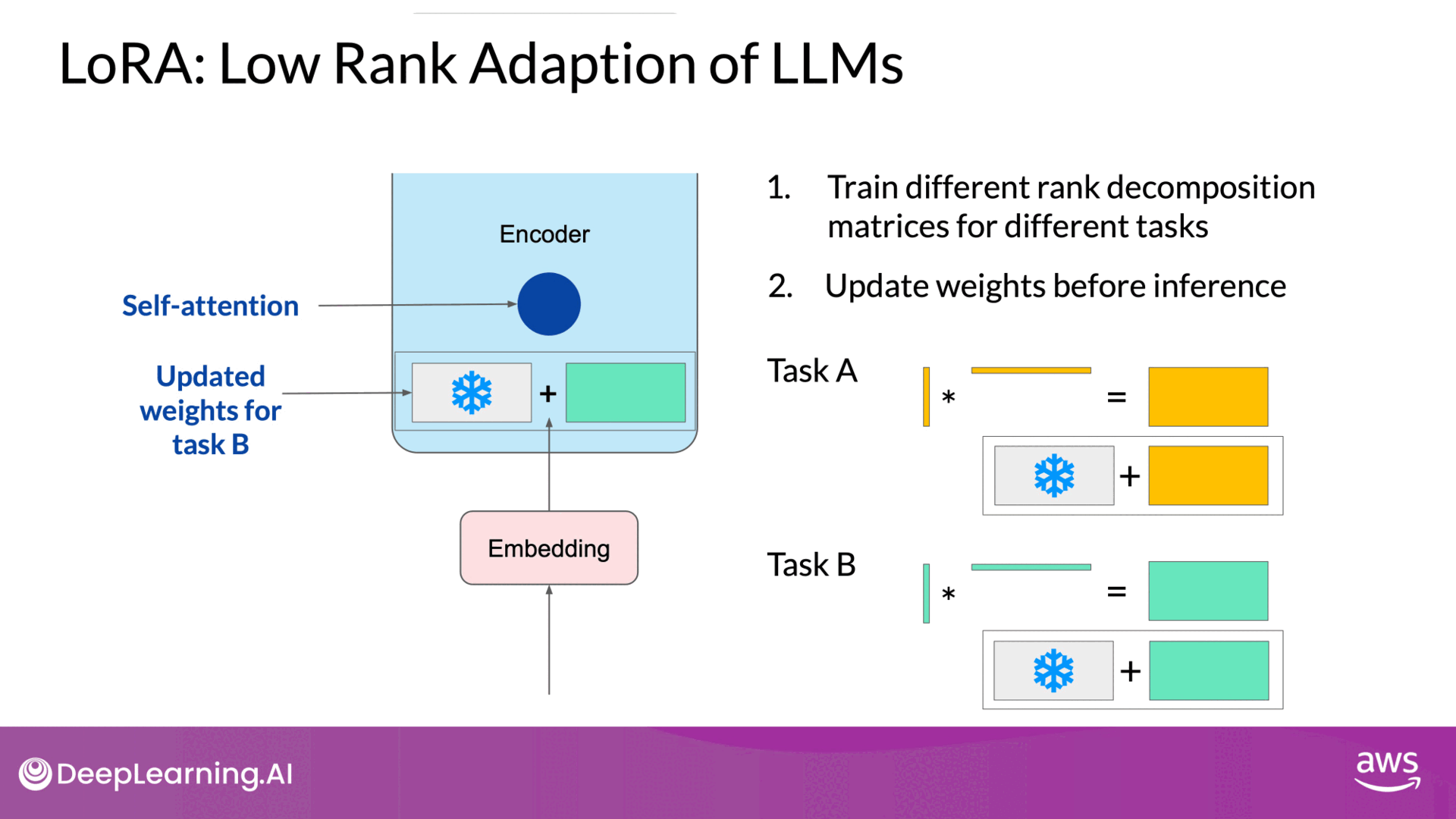
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Memory Efficiency: Reduces memory requirements, making it feasible to perform fine-tuning on a single GPU.
- Parameter Reduction: Trains a significantly smaller number of parameters, often just 15-20% of the original model's parameters.
- Flexibility: Allows fine-tuning for multiple tasks by switching out the low-rank matrices, avoiding the need for multiple full-size model versions.
- Performance: Achieves performance close to full fine-tuning but with significantly less computational overhead.
Performance Comparison
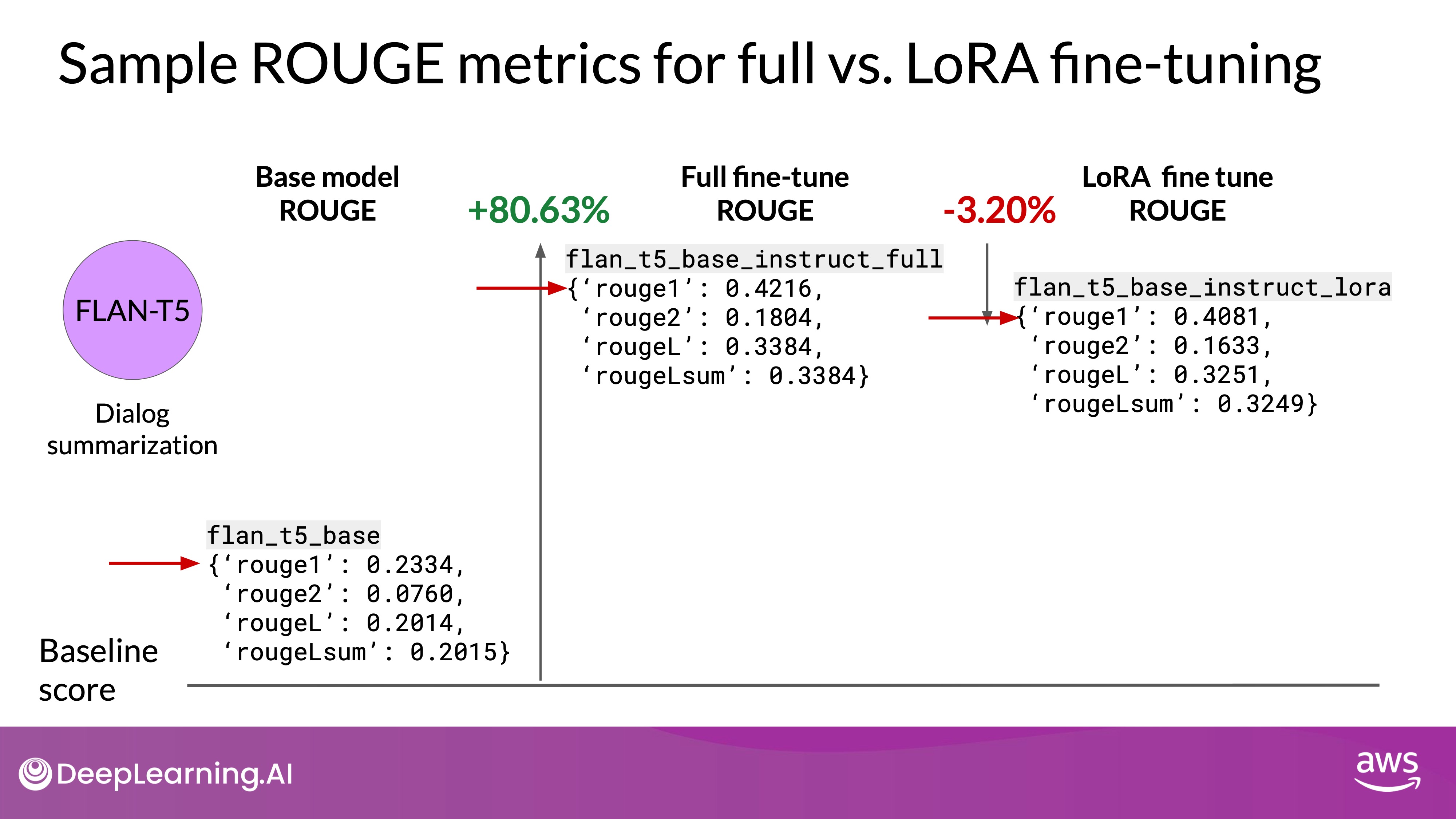
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Baseline Model: FLAN-T5 base model on a dialogue summarization task.
- Full Fine-Tuning: Results in a significant performance boost, increasing ROUGE-1 score by 0.19.
- LoRA Fine-Tuning: Also improves performance, increasing the ROUGE-1 score by 0.17, with much less computational effort.
Choosing the Rank of LoRA Matrices
![]()
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Rank Selection: The optimal
rankis a balance between computational savings and model performance. - Research Findings:
Ranksbetween 4 and 32 provide a good trade-off, with largerranksnot necessarily improving performance. - Ongoing Research: Optimizing the
rankis an active research area, with best practices evolving over time.
Additive: Soft prompts
Besides LoRA, there are also additive methods within PEFT that aim to improve model performance without changing the weights at all, called prompt tuning, enhances model performance without changing weights at all. Unlike prompt engineering, where you manually craft prompts to improve model outputs, prompt tuning involves adding trainable tokens to the prompt and optimizing them through supervised learning.
Prompt Tuning Process:
- Soft Prompts:
- Trainable tokens called soft prompts are prepended to the input's embedding vectors.
- Natural language tokens are "hard" because they correspond to fixed locations in the embedding vector space. In contrast, soft prompts are "virtual" tokens that can take any value within the continuous multidimensional embedding space. Through supervised learning, the model optimizes these virtual tokens to enhance task performance.
- Training: During supervised learning, these soft prompts are updated to maximize task performance, while the model’s weights remain unchanged.
- Parameter Efficiency: Only the soft prompts are trained, which is much more efficient than training millions of parameters in full fine-tuning.
- Task Adaptability: Different sets of soft prompts can be trained for various tasks and swapped during inference, making the approach highly flexible and efficient in storage. You'll notice the same LLM is used for all tasks, all you have to do is switch out the soft prompts at inference time.
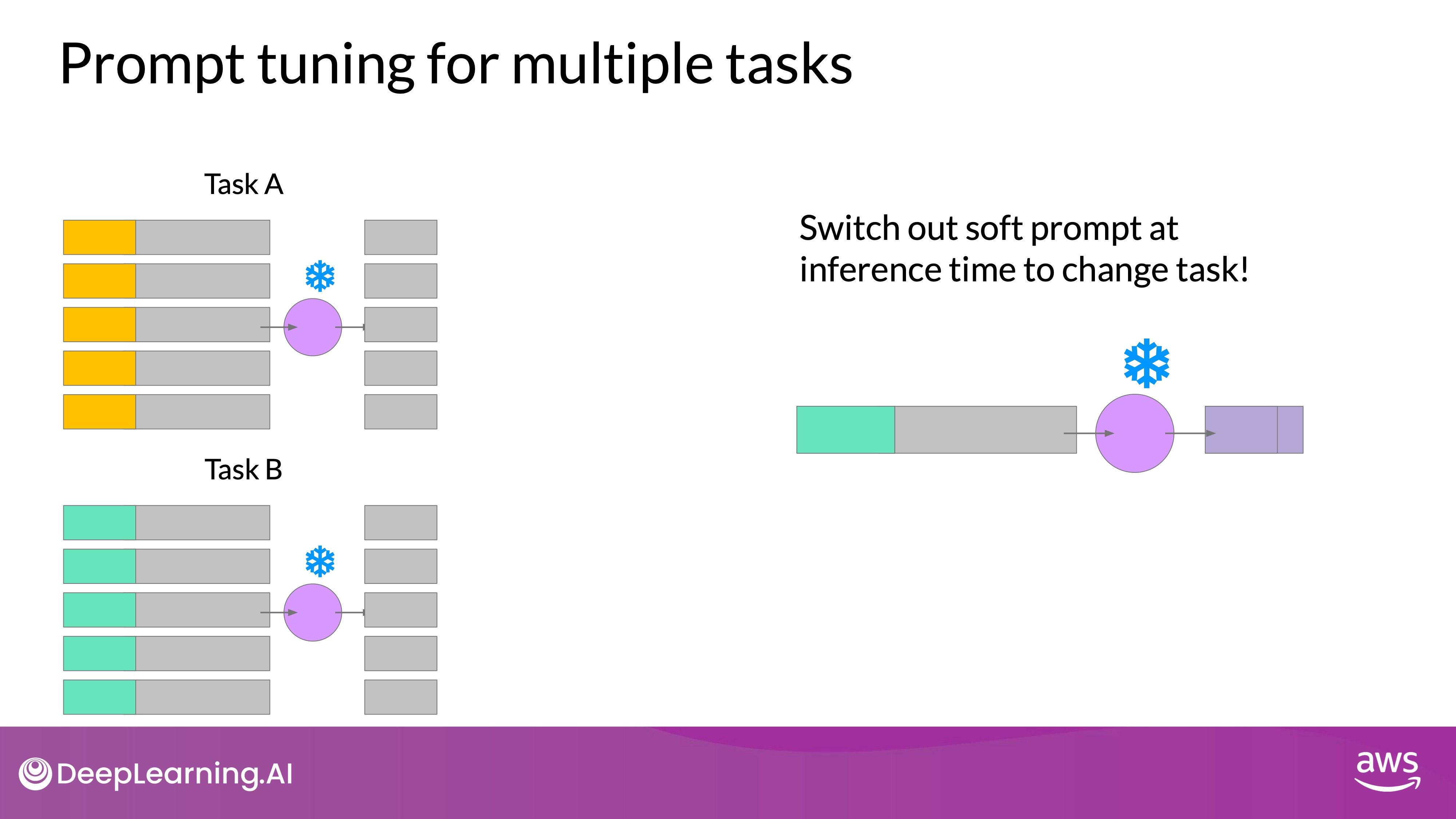
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Performance Comparison
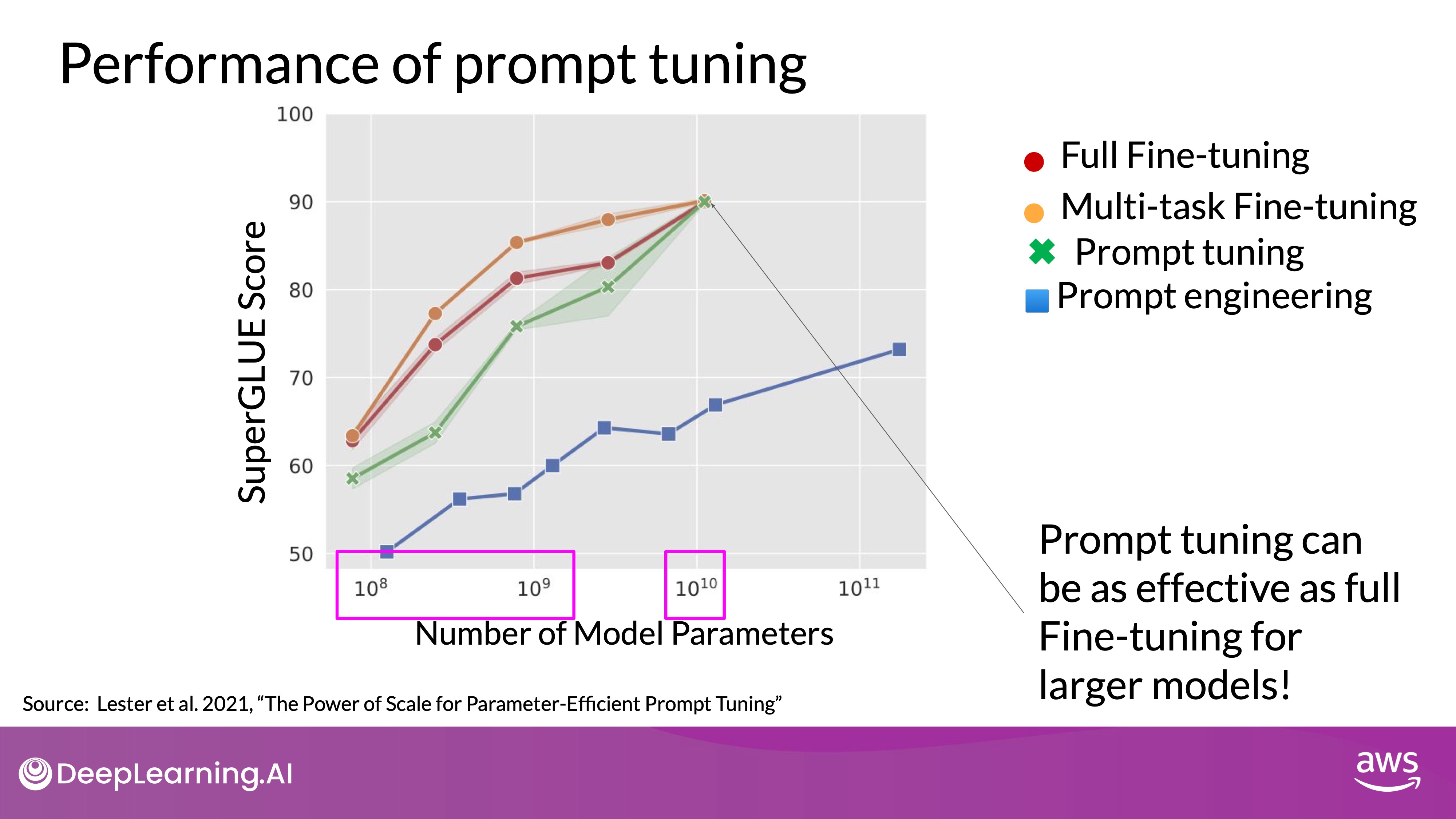
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Diagram: In this figure from the paper, you can see the Model size on the X axis and the SuperGLUE score on the Y axis.
- Benchmark: In the original paper by Brian Lester and collaborators at Google, models were evaluated using the SuperGLUE benchmark.
- Results: Prompt tuning’s performance increases with model size, becoming comparable to full fine-tuning in models with around 10 billion parameters and significantly outperforming prompt engineering.
Soft prompt tokens can take any value within the continuous embedding space, so they don't correspond to specific words in the LLM's vocabulary. However, analyzing the nearest neighbor tokens reveals that they form tight semantic clusters, meaning the words closest to the soft prompts have similar meanings. This suggests that the soft prompts are learning representations related to the task.