RAG vs Retrain vs Finetune
TL;DR - Retraining a model is a broad, widely-used term in machine learning for updating any pre-trained model with new data. In contrast, Retrieval-Augmented Generation (RAG) is a specialized approach within NLP, designed to add context to language models by incorporating external information during text generation.
Intro
Artificial Intelligence (AI) has made remarkable progress in natural language processing (NLP), offering powerful tools for everything from text generation to question answering. Among the many techniques available, Retrieval-Augmented Generation (RAG) and retraining a model stand out as two prominent approaches, each serving distinct purposes and offering unique advantages. This blog post explores the differences, applications, and benefits of these methods, providing a comprehensive guide for AI practitioners and enthusiasts.
In NLP, generating meaningful and accurate responses is crucial. RAG and retraining models are key techniques that significantly enhance the capabilities of AI systems. However, these methods are often confused, even by seasoned professionals. Simply put, RAG dynamically retrieves external information to enhance a model's responses, while retraining involves updating the model's parameters with new data. The confusion arises because both methods aim to improve AI performance, but they operate in fundamentally different ways.
This post aims to clarify these methods, highlighting their differences, benefits, and practical applications.
RAG, Retrain, Fine-tuning
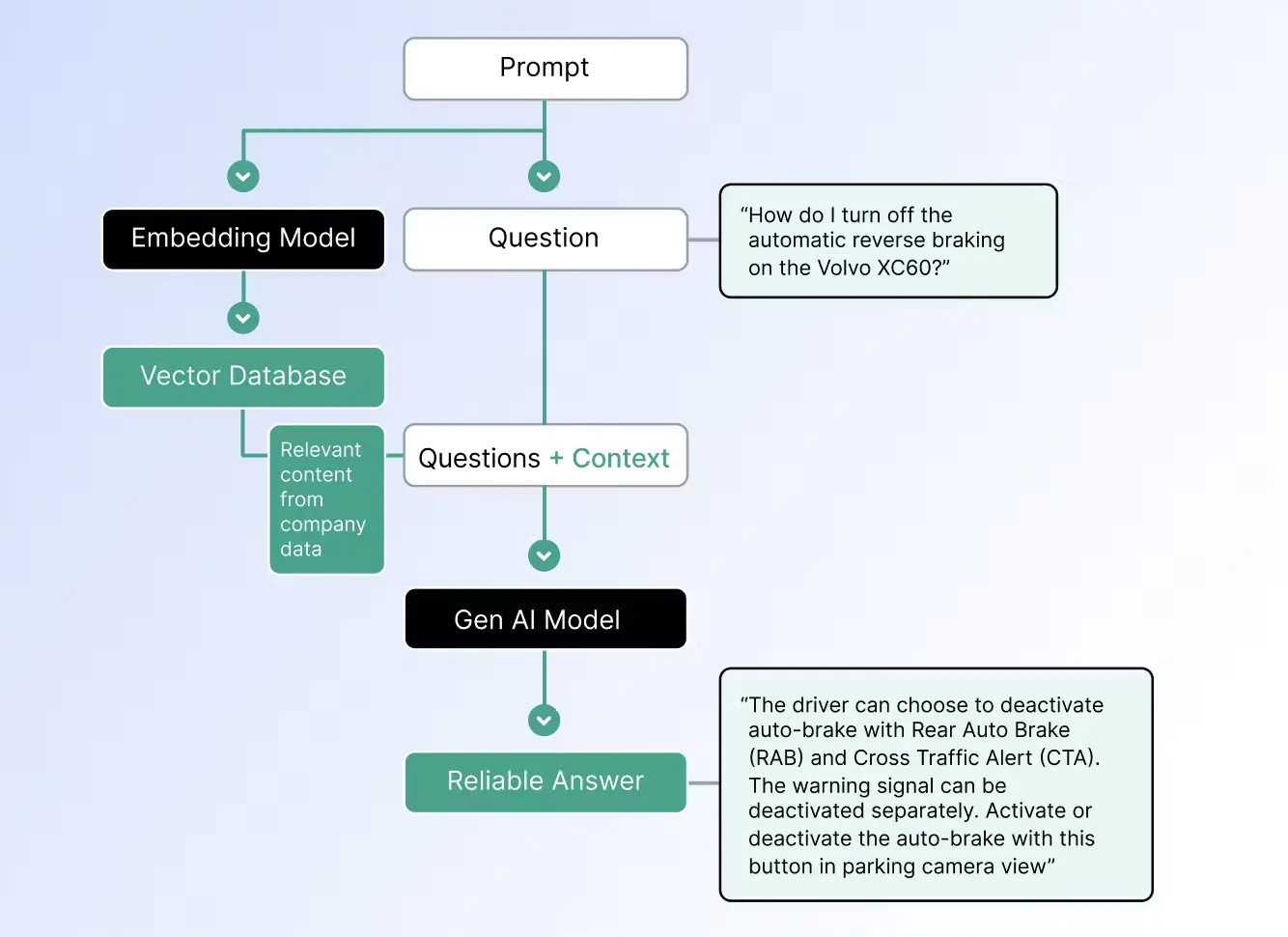
Source: What’s the Difference Between Fine-tuning, Retraining, and RAG?
Retrieval-Augmented Generation (RAG) is designed to enhance model responses by dynamically retrieving external information and integrating it with the model's generation capabilities. This makes RAG ideal for applications that require real-time, up-to-date information such as question-answering systems and chatbots that need to pull in current data from external sources. For instance, a legal advice bot might use RAG to pull in the latest legal precedents, or a financial assistant could fetch real-time stock prices to provide accurate financial advice.
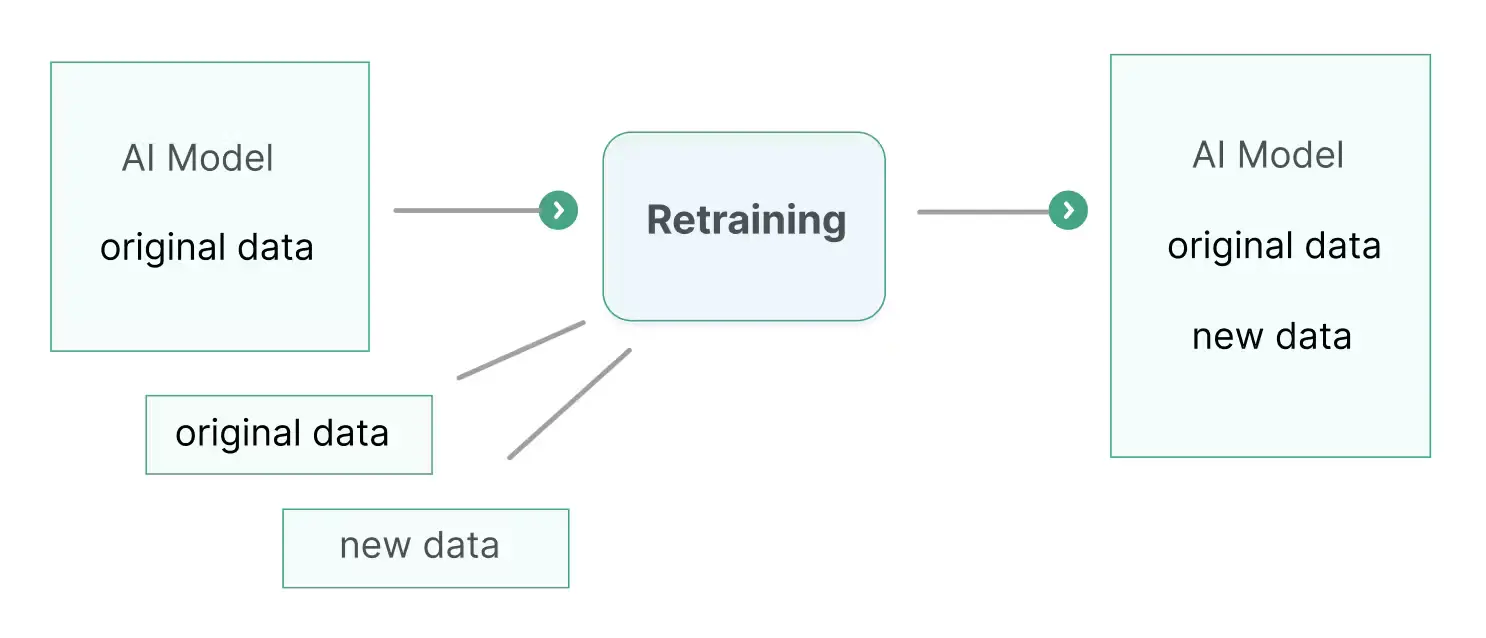
Source: What’s the Difference Between Fine-tuning, Retraining, and RAG?
Retraining involves updating a pre-trained model with new data to improve its performance and adapt to changes in the data distribution. This process helps the model remain relevant and effective over time. Retraining is particularly useful in scenarios where the underlying data patterns evolve, such as in predictive analytics for customer behavior or fraud detection systems that need to stay current with emerging fraud tactics. Another example is updating a recommendation engine with new user behavior data to improve the accuracy of recommendations.
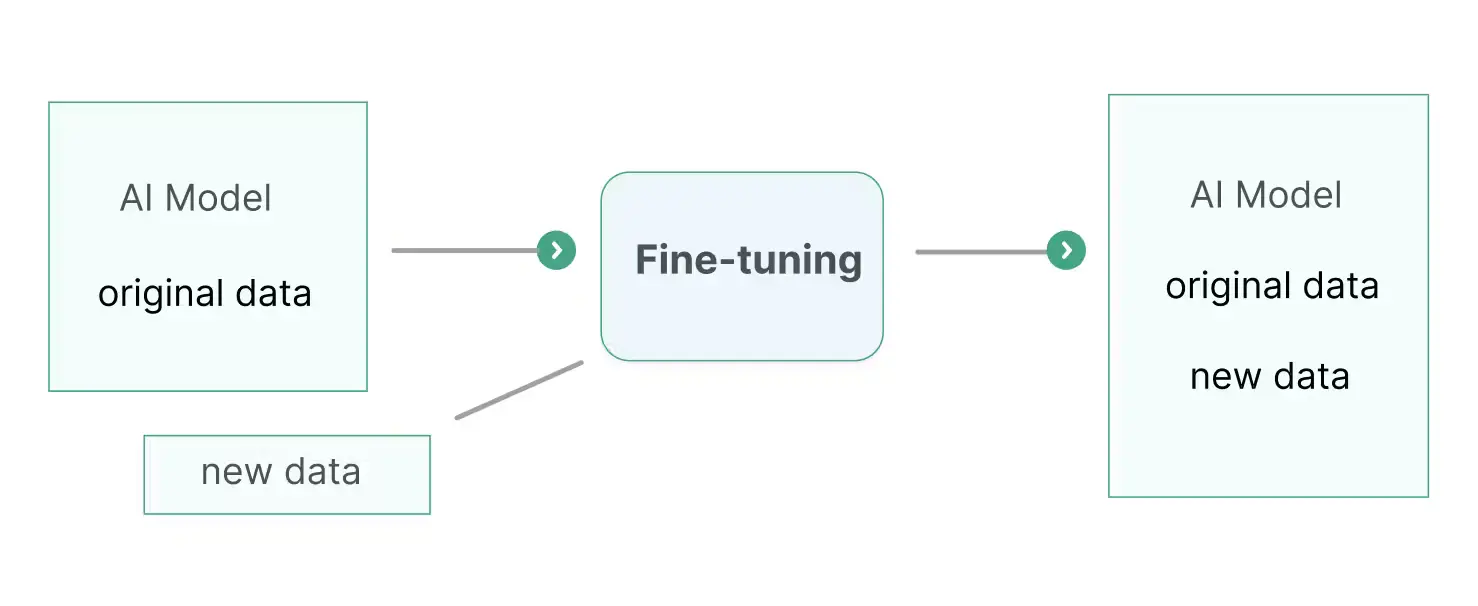
Source: What’s the Difference Between Fine-tuning, Retraining, and RAG?
Fine-tuning, a specific type of retraining, adapts a pre-trained model to a particular task using a smaller, task-specific dataset. This approach leverages the general knowledge captured by the pre-trained model and refines it for specialized applications. Fine-tuning is efficient and requires fewer resources compared to training a model from scratch, making it suitable for tasks like sentiment analysis in social media monitoring or named entity recognition (NER) for extracting specific information from medical records. Another example of fine-tuning is customizing a language model for customer support to handle domain-specific queries more effectively.
Fine-tuning is a type of retraining an AI model. Different retraining approaches have their own advantages on their areas. For example, fine-tuning offers several benefits compared to other retraining methods:
- Efficiency: Fine-tuning requires less computational power and data, making it faster and more cost-effective than full retraining or incremental learning.
- Task-Specific Adaptation: It adapts a pre-trained model to perform exceptionally well on a specific task using a smaller, task-specific dataset, unlike general retraining or domain adaptation.
- Rapid Deployment: Fine-tuning allows for quick adjustments and deployment for various tasks, whereas other methods like incremental learning and domain adaptation can be more complex and time-consuming.
To name a few, there are other types of retraining in AI models include Incremental Learning, which continuously updates the model with new data without retraining from scratch, and Domain Adaptation, which adapts a pre-trained model to work effectively in a new domain with different data distributions. Active Learning is another approach, where the model iteratively selects the most informative samples to label and retrain on, optimizing performance with minimal labeled data.
Key Differences between RAG and Retraining
Retrieval-Augmented Generation (RAG) and retraining are both methods used to enhance the capabilities of AI models, but they serve different purposes and operate in fundamentally different ways. In essence, RAG enhances model responses by dynamically integrating external information, making it suitable for tasks requiring real-time, contextually relevant data. Retraining, on the other hand, involves updating the model’s parameters with new data, making it ideal for improving performance and adapting to changes in data distribution over time. Understanding these differences helps in selecting the appropriate method based on specific needs and applications in AI.
Here are the key differences between the two:
Purpose
- RAG:
- Dynamic Information Retrieval: RAG combines the capabilities of retrieval systems and generation models to produce responses by dynamically incorporating external information. It is designed to enhance context and relevance by fetching real-time data.
- Use Case: Ideal for applications requiring up-to-date information that cannot be encoded within the model’s parameters, such as real-time question answering, chatbots, and content generation.
- Retraining:
- Model Update: Retraining involves updating an AI model with new data to improve its performance or adapt it to changes in the data distribution. This process can include fine-tuning, incremental learning, or domain adaptation.
- Use Case: Suitable for scenarios where the underlying data patterns evolve or where there is a need to enhance the model’s performance over time, such as predictive analytics, recommendation systems, and classification tasks.
Mechanism
- RAG:
- Retrieval: Retrieves relevant documents or data from an external corpus based on a query.
- Integration: Integrates the retrieved information with the model to generate a response.
- Output: Produces contextually rich and accurate responses by leveraging external data.
- Retraining:
- Data Collection: Involves gathering new data relevant to the task or domain.
- Model Training: Uses this data to retrain the model, adjusting its parameters.
- Evaluation: Includes assessing the model’s performance on a validation set to ensure improvements and prevent overfitting.
- Output: Results in an updated model that has learned from new data patterns.
Advantages
- RAG:
- Access to Vast Knowledge: Can dynamically access and use a vast amount of external information.
- Up-to-Date Responses: Ensures responses are based on the most current information available.
- Scalability: Easily updated by modifying the knowledge base without changing the model’s parameters.
- Retraining:
- Improved Accuracy: Helps the model learn from new data patterns, enhancing its accuracy.
- Adaptation to New Data: Ensures the model remains relevant and effective by adapting to new information.
- Task-Specific Performance: Fine-tuning can make the model perform exceptionally well on specific tasks.
When to Retrain a LLM vs RAG
Retrain a LLM when you need to significantly improve the model's performance, adapt it to specific tasks or domains, handle substantial changes in data, or localize it for different languages or regions. This approach is resource-intensive but provides deep customization and accuracy improvements.
Use RAG when you need to dynamically access up-to-date information, enhance the model's responses with a broad knowledge base, reduce costs, quickly adapt to new data, mitigate overfitting, or handle specialized and complex queries. RAG is less resource-intensive and allows for flexible integration of external knowledge, making it ideal for applications requiring dynamic and contextually rich responses.
Large Language Model
- Domain-Specific Needs:
- Highly Specialized Tasks: Retraining is necessary when your application requires a deep understanding of specific industry jargon, terminology, or concepts not well-represented in the original training data.
- Example: A medical diagnosis tool needing to understand complex medical literature and terminologies.
- Significant Changes in Data:
- Updated Data: If the underlying data distribution has changed significantly or there is a substantial amount of new data, retraining ensures that the model remains relevant and accurate.
- Example: A news summarization model that needs to stay updated with current events and recent language usage trends.
- Performance Improvement and Customization:
- Accuracy and Precision: Retraining is ideal when the current model's performance is not meeting required benchmarks or when you need to finely tune the model for a particular task.
- Example: A sentiment analysis tool for a specific brand that requires an understanding of brand-specific context and nuances.
Retrieval-Augmented Generation
- Access to Up-to-Date Information:
- Dynamic Knowledge: Use RAG when the model needs to access the latest information that may not be available in the static training data.
- Example: A question-answering system that needs to provide answers based on the most recent scientific research or news articles.
- Cost Efficiency and Quick Adaptation:
- Resource Constraints: When retraining is too expensive or resource-intensive, RAG can achieve the desired performance improvements without high costs and allows for quick updates.
- Example: A startup leveraging AI for customer queries where budget constraints make retraining infeasible.
- Handling Rare or Complex Queries:
- Specialized Information Retrieval: RAG is ideal for handling rare or complex queries that require specialized knowledge not frequently encountered in training data.
- Example: A technical support chatbot that needs to provide detailed answers based on specific technical manuals or documentation.
Challenges and Considerations
When using Retrieval-Augmented Generation (RAG) and retraining, several challenges and considerations must be addressed to ensure optimal performance.
For RAG, data quality is paramount, as the effectiveness of the generated responses heavily relies on the relevance and accuracy of the retrieved information. Integration complexity is another challenge, requiring seamless coordination between retrieval and generation components to produce coherent responses. Additionally, the retrieval process must be efficient to avoid latency issues, and managing a constantly updated external corpus can be resource-intensive.
For retraining, computational resources are a significant concern, as the process demands substantial processing power and time, especially with large datasets. There is also the risk of overfitting, where the model becomes too specialized to the new training data and loses generalizability. Ensuring that the model does not degrade in performance on previously learned tasks is crucial. Regular evaluation and validation are necessary to maintain model robustness. Both methods require careful planning and implementation to balance performance improvements with resource constraints and technical complexities.