Introduction to LLMs
Large Language Models (LLMs) primarily fall under the categories of deep learning and machine learning, leveraging advanced neural network architectures like transformers. Initially, machine learning models represented words using numerical tables or one-hot encoding, which couldn't capture semantic relationships. This limitation was addressed with word embeddings, where words are represented as multi-dimensional vectors in a vector space, allowing words with similar meanings to be close to each other.
Transformers, a key architecture in LLMs, use an encoder to convert text into numerical representations and understand the context of words and phrases. The encoder-decoder mechanism enables LLMs to process and generate text by understanding relationships between words, such as parts of speech and contextual meanings. This sophisticated understanding allows LLMs to generate coherent and contextually relevant outputs.
Thus, LLMs are a product of deep learning due to their use of deep neural networks and extensive training on large datasets. They also fall under machine learning, as they learn patterns from data to perform tasks. While they exhibit advanced AI capabilities in natural language understanding, they are not yet examples of general AI, which requires broader reasoning and learning abilities across diverse tasks.
Large Language Models (LLMs) largely represents a class of deep learning architectures called transformer networks. A transformer model is a neural network that learns context and meaning by tracking relationships in sequential data, like the words in this sentence.
LLMs are a subset of language models, distinguished by their size, which is attributed to their extensive training data and a vast number of learnable parameters. Larger LLMs tend to produce more accurate and sophisticated responses.
However, the quality of data used for training LLMs is crucial. Models trained on peer-reviewed content, such as research papers and novels, typically outperform those trained on unreviewed data like social media posts. LLMs require diverse data to perform various natural language processing (NLP) tasks. Fine-tuning allows a foundation language model to specialize in specific domains.
Foundation language models, like MT-NLG and GPT-3, are versatile and perform a wide range of NLP tasks. They excel in general performance but may not be ideal for specific tasks. Fine-tuned language models, derived from foundation LLMs, are customized for specialized purposes and offer improved task-specific performance. Fine-tuning is commonly achieved through parameter-efficient techniques like p-tuning and adapters, making it a cost-effective and practical approach.
Generative AI and LLMs specifically are a general purpose technology. That means that similar to other general purpose technologies like deep learning and electricity, is useful not just for a single application, but for a lot of different applications that span many corners of the economy.
Evolution of Large Language Models
The evolution of large language models (LLMs) has brought about a paradigm shift in natural language processing (NLP). Historically, AI systems focused on data analysis rather than generation, but the advent of LLMs shifted this balance. This change can be observed by comparing three NLP regimes:
- Pre-transformers NLP: This era relied on rule-based models and simple neural networks like RNNs and LSTMs. While suitable for basic tasks, they struggled with complex and novel data.
- Transformers NLP: Transformers, introduced in 2017, improved NLP by better generalization, enhanced context understanding, and more efficient data processing. However, limitations in data and resources hindered their capabilities.
- LLM NLP: OpenAI's GPT-3 in 2020 marked the LLM era. These models, trained on extensive data, produced highly accurate NLP responses, democratizing NLP for non-technical users.
The transition was driven by technological advancements like neural networks, attention mechanisms, and transformers, along with unsupervised and self-supervised learning. These concepts are fundamental in comprehending the workings of LLMs and building new ones.
Neural Networks
Source: What Deep Learning Is And Isn’t
Large language models (LLMs) initially used simpler neural network (NN) architectures, particularly recurrent neural networks (RNNs) and long short-term memory networks (LSTMs). RNNs and LSTMs excelled at considering context, position, and word relationships in data, making them effective for sentiment analysis and text classification. These neural networks possessed the remarkable ability to learn autonomously, generating their rules from data rather than relying on predefined rules, a concept known as representation learning.
The biggest advantage that neural networks like RNNs and LSTMs had over traditional, rule-based systems was that they were capable of learning on their own with little to no human involvement. They analyze data to create their own rules, rather than learn the rules first and apply them to data later. This is also known as representation learning and is inspired by human learning processes.
Representations, or features, are hidden patterns that neural networks can extract from data. To exemplify this, let’s imagine we’re training an NN-based model on a dataset containing the following tokens:
“cat,” “cats,” dog,” “dogs”
After analyzing these tokens, the model may identify a representation that one could formulate as:
Plural nouns have the suffix “-s.”
The model will then extract this representation and apply it to new or edge-case scenarios whose data distribution follows that of training data. For example, the assumption can be made that the model will correctly classify tokens like “chairs” or “table” as plural or singular even if it had not encountered them before. Once it encounters irregular nouns that don’t follow the extracted representation, the model will update its parameters to reflect new representations, such as:
Plural nouns are followed by plural verbs.
This approach enables NN-based models to generalize better than rule-based systems and successfully perform a wider range of tasks.
The capacity to extract representations depends on the neural network's size, with more neurons and layers enabling more complex representations. However, deep neural networks became practical only after hardware improvements, notably the introduction of GPUs in 1999. These GPUs facilitated parallel processing and powered deep learning, leading to transformative NNs like transformers.
The most basic training of language models involves predicting a word in a sequence of words. Most commonly, this is observed as either next-token-prediction and masked-language-modeling.
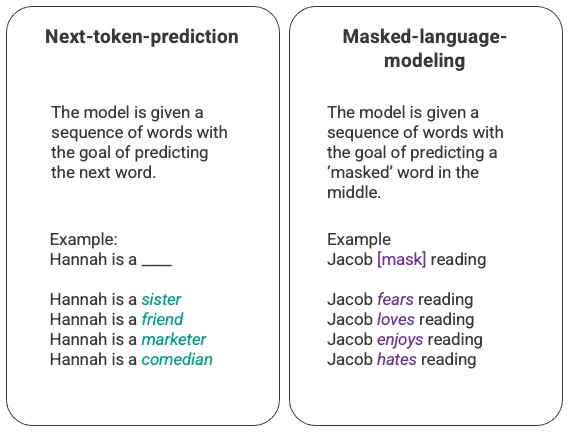
In this basic sequencing technique, often deployed through a Long-Short-Term-Memory (LSTM) model, the model is filling in the blank with the most statistically probable word given the surrounding context. There are two major limitations with this sequential modeling structure.
- The model is unable to value some of the surrounding words more than others. In the above example, while 'reading' may most often associate with 'hates', in the database 'Jacob' may be such an avid reader that the model should give more weight to 'Jacob' than to 'reading' and choose 'love' instead of 'hates'.
- The input data is processed individually and sequentially rather than as a whole corpus. This means that when an LSTM is trained, the window of context is fixed, extending only beyond an individual input for several steps in the sequence. This limits the complexity of the relationships between words and the meanings that can be derived.
In response to this issue, in 2017 a team at Google Brain introduced transformers. Unlike LSTMs, transformers can process all input data simultaneously. Using a self-attention mechanism, the model can give varying weight to different parts of the input data in relation to any position of the language sequence. This feature enabled massive improvements in infusing meaning into LLMs and enables processing of significantly larger datasets.
Transformers
Do you know a sequence-to-sequence task, which was the original objective of the transformer architecture designers?
RNNs and LSTMs are advantageous for natural language processing (NLP) tasks, such as sentiment analysis and text classification, as they consider word context and relationships. However, they are limited when handling longer data sequences and broader context. Their sequential processing results in slower inference, which poses challenges when processing lengthy text. They can always determine word order due to sequential processing, ensuring accurate output.
The introduction of transformers in 2017 revolutionized NLP. A transformer is made up of multiple transformer blocks, also known as layers. For example, a transformer has self-attention layers, feed-forward layers, and normalization layers, all working together to decipher input to predict streams of output at inference. The layers can be stacked to make deeper transformers and powerful language models. Transformers were first introduced by Google in the 2017 paper "Attention Is All You Need."
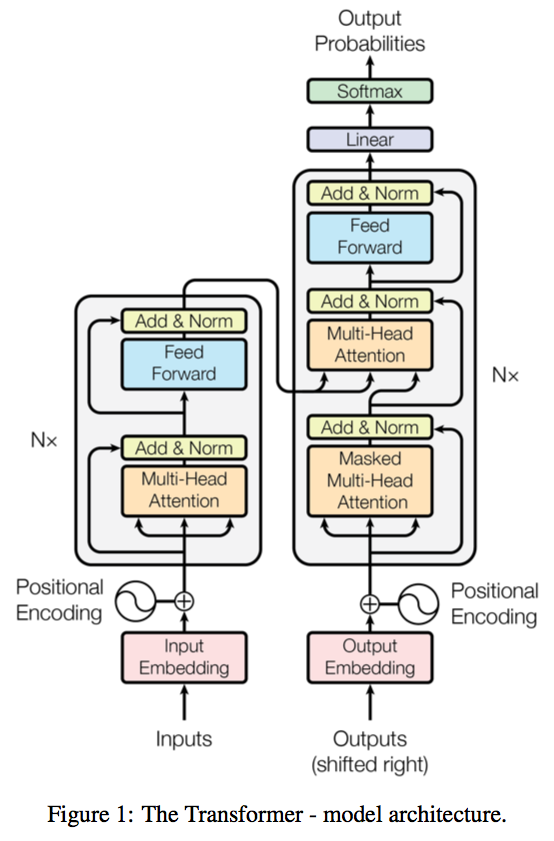
Source: Attention is all you need
There are two key innovations that make transformers particularly adept for large language models: positional encodings and self-attention.
- Positional encoding embeds the order of which the input occurs within a given sequence. Essentially, instead of feeding words within a sentence sequentially into the neural network, thanks to positional encoding, the words can be fed in non-sequentially.
- Self-attention renders RNNs and convolutions unnecessary for sequential data then assigns a weight to each part of the input data while processing it. This weight signifies the importance of that input in context to the rest of the input. In other words, models no longer have to dedicate the same attention to all inputs and can focus on the parts of the input that actually matter. This representation of what parts of the input the neural network needs to pay attention to is learnt over time as the model sifts and analyzes mountains of data.
These two techniques in conjunction allow for analyzing the subtle ways and contexts in which distinct elements influence and relate to each other over long distances, non-sequentially.
The ability to process data non-sequentially enables the decomposition of the complex problem into multiple, smaller, simultaneous computations. Naturally, GPUs are well suited to solve these types of problems in parallel, allowing for large-scale processing of large-scale unlabelled datasets and enormous transformer networks.
What is self-attention?
The analogy of self-attention is that imagine you're at a cocktail party trying to understand the story your friend is telling (which we'll think of as the current word we want to process). As your friend speaks, you're not only listening to them but also paying attention to the context:
- Other friends chiming in with comments (other words in the sequence)
- The background music and noise (irrelevant information)
- The expressions and gestures of your storytelling friend (accentuating certain words or meanings)
In this analogy, your brain is performing a kind of self-attention. It's figuring out which pieces of information (inputs) are important to focus on so that you can fully understand the story your friend is telling (processing the current word). Just like in the GPT model, some inputs (comments, noise, gestures) are given more weight than others, and that affects your understanding of the story.
To demonstrate this, let’s imagine the desired model is a transformer-based model to predict the next words for the following input sentence:
Mary had a little lamb.
Attention mechanisms – or, rather, self-attention layers that are based on attention mechanisms – would first calculate attention weights for each word in our input. Attention weights represent the importance of each token, so the more weight a token is assigned, the more important it's deemed. For example, the attention mechanism might give more weight to the word "lamb" than the word "a," as it’s likely to have more influence on the final output. The model would then use these weights to dynamically emphasize or downplay each word as it generates output. If one assumes that the most weight was assigned to the word “lamb,” the model may produce a continuation such as:
"whose fleece was white as snow"
To determine how important each token is, self-attention layers examine its relationships with other tokens in a sequence:
- If a token has many relevant relationships with other tokens with respect to the task being performed, then that token is deemed as important and, potentially, more important than other tokens in the same sequence.
- If a token doesn’t have many relationships with other tokens, or if they are irrelevant to a specific task, that token is considered less important or completely unimportant. This means the model will virtually ignore it when generating the output.
So, by enabling models to handle context more effectively, attention mechanisms allowed them to generate more accurate outputs than models based on RNNs and LSTMs. Simultaneously, this new approach to data processing also allowed transformer-based models to generate outputs more quickly than RNN- and LSTM-based models.
Yet, transformers face a challenge due to non-sequential data processing. Changes in word order can distort meaning or lead to nonsensical variations. Transformers use positional encodings to overcome this issue, retaining position information.
Positional encodings to overcome non-sequential word order
LSTMs and RNNs need more time to generate output because they process input sequentially. To
clarify what this means, let’s explore how LSTMs would approach processing our original input
sentence: Mary had a little lamb.
Since LSTMs process data sequentially, they would need to process one word in our sequence at a time: Mary, had, a, little, lamb. This significantly slows down inference, especially with longer data sequences. For example, just imagine how long it would take LSTMs and RNNs to process a single Wikipedia page. Too long.
Transformers, on the other hand, process data in parallel, which means they “read” all input tokens at once instead of processing one at a time. It also means they are able to perform NLP tasks faster than LSTMs and RNNs.
However, despite being slow, sequential data processing has one big advantage. By processing one word at a time, LSTMs and RNNs are always able to tell which word came first, second, and so on. They know the word order of the input sequence because they use that same order to process it. Conversely, transformers are not initially “aware” of the original word order because they process data non-sequentially. While this may seem like only a minor problem at first, analyzing the sentences below may illustrate otherwise:
1. Mary had a little lamb.
2. A little lamb had Mary.
3. Had a little lamb Mary.
Sentence (2) shows how a slight change in word order can distort the intended meaning, while sentence (3) exemplifies an even bigger issue — how changes in word order can result in completely nonsensical and grammatically incorrect variations.
To overcome this challenge, transformers use positional encodings that help them retain position information. Positional encodings are additional inputs, or vectors, associated with each token. They can be fixed or trainable, depending on whether the desire is for the model to refine them during training or not
Transformer Language models
GPT
TL;DR - GPT, developed by OpenAI, is one of the most famous large language models. It's known for its impressive text generation capabilities and can be fine-tuned for various NLP tasks.
Generative Pre-training Transformer (GPT) models were first launched in 2018 by openAI as GPT-1. The models continued to evolve over 2019 with GPT-2, 2020 with GPT-3, 2022 with InstructGPT and ChatGPT and most recently GPT-4 in 2023.
| Feature/Version | GPT-2 | GPT-3 | GPT-4 |
|---|---|---|---|
| Parameters | 1.5 billion | 175 billion | Estimated over 175 billion (not officially released) |
| Dataset | WebText (40GB) | Common Crawl, WebText2, Books1, Books2, and additional data (570GB) | Unspecified, but likely larger and more diverse than GPT-3 |
| Tuning | Supervised fine-tuning possible but not a main feature | Few-shot, one-shot, and zero-shot learning capabilities | Presumably improved few-shot, one-shot, and zero-shot learning with more sophisticated fine-tuning |
| Architecture | Transformer-based neural network with 48 layers | Transformer-based neural network with 96 layers | Expected to be a more advanced version of transformer architecture, potentially with more layers |
| Performance | High-quality text generation with some limits in coherence over long passages | Significantly improved performance with better context understanding and coherence over longer passages | Expected to surpass GPT-3 in performance, coherence, context understanding and possibly in handling more nuanced prompts |
All GPT models leverage the transformer architecture, which means they have an encoder to process the input sequence and a decoder to generate the output sequence. Both the encoder and decoder have a multi-head self-attention mechanism that allows the model to differentially weight parts of the sequence to infer meaning and context. In addition, the encoder leverages masked-language-modeling to understand the relationship between words and produce more comprehensible responses.
The self-attention mechanism that drives GPT works by converting tokens (pieces of text, which can be a word, sentence, or other grouping of text) into vectors that represent the importance of the token in the input sequence. To do this, the model,
- Creates a query, key, and value vector for each token in the input sequence.
- Calculates the similarity between the query vector from step one and the key vector of every other token by taking the dot product of the two vectors.
- Generates normalized weights by feeding the output of step 2 into a softmax function.
- Generates a final vector, representing the importance of the token within the sequence by multiplying the weights generated in step 3 by the value vectors of each token.
The ‘multi-head’ attention mechanism that GPT uses is an evolution of self-attention because it allows the model to simultaneously attend to information from different representation subspaces at different positions. Instead of focusing on one single aspect of the data by performing steps 1–4 once, multi-head attention aggregates multiple perspectives by performing steps 1-4 in parallel, enabling the model to capture a more comprehensive understanding of the context. This leads to improvements in capturing nuances and complex relationships within the data, thereby enhancing the performance on tasks such as language translation, question-answering, and text generation. Each "head" in multi-head attention can be seen as an independent feature detector, and collectively they provide a multifaceted representation of the input sequence.
ChatGPT is a spinoff of InstructGPT, which introduced a novel approach to incorporating human feedback into the training process to better align the model outputs with user intent. Reinforcement Learning from Human Feedback (RLHF) is described in depth in openAI’s 2022 paper Training language models to follow instructions with human feedback and is simplified below.
InstructGPT is a variant of the GPT (Generative Pre-trained Transformer) language model developed by OpenAI, specifically fine-tuned to better understand and follow user instructions. Unlike the standard GPT models which generate text based on a given prompt, InstructGPT is trained to respond more accurately to prompts that require specific actions or outputs, such as creating a list, summarizing information, or providing explanations. It aims to be more aligned with the intentions behind user requests, providing more relevant and useful responses.
BERT
Google's BERT (Bidirectional Encoder Representations from Transformers) is a pioneering transformer-based language model. It's bidirectional and more accurate than unidirectional models, as it considers both sides of masked tokens.
To illustrate this, let’s imagine that a model is given the following input sentence:
"I [have] a mask."
BERT’s task is to predict the masked word “have.” It does so by analyzing the tokens on both of its sides, namely "I,", "a," and “mask.” This is what makes it bidirectional, as well as more accurate than previous language models that could only consider the context on the left of the masked token. In this case, unidirectional models would only consider the word “I” when predicting the masked word, which provides little context. The chances of a unidirectional model generating the right predictions are smaller.
BERT was the first model to show how bidirectionality can model performance NLP tasks. It benefited various applications, including Google's search engine's enhanced query understanding. It demonstrated the potential of transformer-based models for NLP tasks, marking a significant shift in the field.
Other LLMs
- LLaMA Announced February 2023 by Meta AI, the LLaMA model is available in multiple parameter sizes from 7 billion to 65 billion parameters. Meta claims LLaMA could help democratize access to the field, which has been hampered by the computing power required to train large models. Try it here
- RoBERTa (A Robustly Optimized BERT Pretraining Approach): RoBERTa is a variant of BERT developed by Facebook AI. It optimizes pretraining tasks and data to improve performance on a wide range of NLP benchmarks.
- ALBERT (A Lite BERT): ALBERT, by Google Research and Toyota Technological Institute at Chicago, focuses on model efficiency and reducing the number of parameters while maintaining performance.
These large language models have played a significant role in advancing natural language processing tasks, making them more accurate, context-aware, and versatile across a wide range of applications.
Unsupervised and Self-Supervised Learning
Unsupervised and self-supervised learning have been pivotal in the development of advanced natural language models like BERT. BERT's significance lies not only in its bidirectional nature but also in its unsupervised learning approach, which involves pattern recognition from unlabeled data, making it a pure form of AI. Both unsupervised and self-supervised learning models benefit from feedback loops, although self-supervised learning relies on supervisory signals generated automatically from data, eliminating the need for human annotation. This minimizes data labeling and human feedback, making model training more efficient.
Benefits of GPT Vs Bert
- How the model works
- GPT, a generative model, excels at generating coherent sentences from scratch, making it suitable for language generation tasks such as text completion, summarization, and question answering.
- On the other hand, BERT is a discriminative model that classifies sentences or tokens into categories like sentiment analysis, named entity recognition, and text classification. It considers both left and right contexts for word meaning, making it effective for tasks like sentiment analysis and question answering.
Architecturally, GPT uses a unidirectional transformer, considering only the left context when predicting, while BERT employs a bidirectional transformer, accounting for both left and right contexts. Both GPT and BERT are influential models in NLP, with their choice depending on the specific task at hand. Often, a combination of both models is used to achieve optimal results in NLP applications.
Both GPT and BERT are powerful models that have revolutionized the field of NLP. Their choice depends on the specific task at hand, and researchers and practitioners often use a combination of both models to achieve optimal results.
How Enterprises Can Benefit From Using Large Language Models
Challenges of LLMs
Enterprises venturing into the use of large language models (LLMs) should be cautious of several common pitfalls, which apply irrespective of whether they customize, fine-tune, or build LLMs from the ground up. These include:
- Vulnerability to Adversarial Examples: LLMs can be tricked by specially crafted inputs, posing security concerns, especially in sensitive industries like healthcare or finance.
- Lack of Interpretability: Some LLMs may lack interpretability, making it challenging to understand their decision-making processes. This can be problematic in high-stakes scenarios and industries requiring transparency.
- Generic Responses: LLMs may provide generic, uncustomized answers, sometimes reproducing trained text data. This raises ethical and legal issues, necessitating techniques like Reinforcement Learning from Human Feedback for improvement.
- Ethical Considerations: The ethical use of LLMs in decision-making tasks, like candidate selection, without human supervision, should be questioned. Furthermore, their use for tasks typically performed by human white-collar workers requires assessment.
- Generation of Inappropriate Content: LLMs, often trained on extensive Internet texts, may produce toxic, biased, and inappropriate content. Enterprises should be cautious of this potential issue.
Building proprietary LLMs from scratch introduces additional challenges, including the need for sufficient computing resources, datasets, expertise, and financial backing for development, implementation, and maintenance.
Ways of building LLMs
Building large language models from scratch is often impractical, especially for enterprises not specialized in AI or NLP. Customizing existing base models is a more viable approach. This process involves three main steps:
- Selecting a Foundation Model/Base model: Choosing an appropriate base model involves considering factors like model size, training tasks, datasets, and LLM providers.
- Fine-Tuning: Base models can be fine-tuned for specific use cases, such as sentiment analysis or legal terminology, by training them on relevant data.
- Optimization: Further enhancements can be achieved through techniques like Reinforcement Learning from Human Feedback (RLHF), which fine-tunes the model based on human feedback.
Alternatively, parameter-efficient methods like adapters and p-tuning can be used to customize base models. Customization is particularly effective when the base model aligns with the selected downstream tasks, leveraging the knowledge gained during training for improved performance.
A video that I found super useful if you want to know how LLM works visually
How to Evaluate LLMs
LLMs employ deep learning techniques to process and generate natural language, making them versatile for tasks like language translation, text summarization, and question-answering. Evaluating LLM performance involves considering several key factors:
- Training Data: The quality and diversity of the training data are vital. It should represent the target language and domain to allow effective pattern learning and generalization. Annotation with relevant labels is often required for supervised learning, a common approach in LLMs.
- Model Size: Larger models generally perform better, but they demand more computational resources. Researchers must strike a balance between model size and performance, tailored to the specific task and available resources. Larger models may also be more susceptible to overfitting.
- Inference Speed: Real-world LLM applications require efficient inference processing. Faster inference times enhance data processing capabilities. Techniques like pruning, quantization, and distillation help reduce model size and improve inference speed.
To assess LLM performance, researchers often rely on standardized benchmarks, which provide datasets and evaluation metrics for specific language-related tasks. These benchmarks, such as GLUE, SuperGLUE, and CoQA, facilitate fair comparisons between different LLM models and methods, highlighting their strengths and weaknesses.
Example applications
- Content generation - Marketing content and copy, paraphrasing, email composition
- Summarization - Legal summarization, news summarization
- Translation - Language translation, code translation
- Classification - Toxicity classification, sentiment analysis, fraud analytics
- Chatbot support - EQA and ODQA chatbots, AI companions
- Tools and technologies - Character generation
It’s worth noting that large language models can be applied to other content categories besides text. They’re currently widely used for speech-, image-, and video-related tasks, such as image generation or video classification.