Safeguarding Agentic Systems
Agentic systems (plan, retrieve, call tools, act) are high-leverage—and high-risk. This guide distills defense-in-depth patterns you can ship today, mapping conceptual guardrails to concrete implementation (especially on AWS Bedrock).
Threats → Layers → Controls (one mental model)
Direct prompt injection (user tries to jailbreak) and indirect prompt injection (malicious text inside webpages/PDFs/KB) are the core threats. Design countermeasures at each choke point—Input, Retrieval, Tool Use, Output, Observability—so one miss doesn’t become a breach.
Guardrail Layers vs Threats
| Layer | What It Protects | Threats Mitigated | Typical Controls |
|---|---|---|---|
| Input | User prompts & uploads | Direct prompt injection; illegal/toxic content; PII | Dual moderation (input), Prompt-Attack filter, instruction isolation, rate limits |
| Retrieval | External/KB text fed to the LLM | Indirect prompt injection; hidden instructions; malicious HTML | Sanitize HTML/scripts; allow/deny domain lists; PI heuristics; “facts-only” summarization |
| Tool Use | APIs/DBs/emails the agent can call | Unauthorized actions; data exfiltration | Tool allowlist; JSON-schema validation; RBAC/IAM scoping; human-in-the-loop for sensitive ops |
| Output | What reaches users or triggers actions | Harmful/off-topic/false responses; jailbreak leakage | Dual moderation (output); relevance & fact-check validators; URL checks; schema-locked results |
| Observability | Posture & drift | Silent bypass; misconfig | Guardrail trace; CloudTrail on config changes; CloudWatch dashboards/alerts; anomaly detection |
Defense-in-Depth Flow
Guardrails in practice (catalog + visuals)
Source: datacamp: Top 20 LLM Guardrails With Examples
Guardrails fall into five major categories. Each maps to different risks in an agentic system, and each can be implemented with either managed services (like Bedrock Guardrails) or custom validators (LangChain/LangGraph nodes, regex, or lightweight LLMs).
🔒 Security & Privacy
These guardrails protect against unsafe or unauthorized content entering or leaving your system. They typically include filters for toxic or offensive language, detection and redaction of personally identifiable information (PII), and prompt injection shields. Example: Bedrock Guardrails can redact phone numbers from user input before the model sees them. In custom stacks, you might run Microsoft Presidio to flag SSNs or emails.
🎯 Response & Relevance
Even if an LLM is polite, it can still drift off-topic or fabricate irrelevant details. Response validators ensure the model answers the question asked, provides citations, and that any URLs it includes actually resolve. Example: Compute cosine similarity between the input query embedding and the generated answer embedding to reject “off-topic” answers. Use a simple HTTP HEAD request to verify URLs.
📝 Language Quality
Output should be clear, professional, and free from low-quality artifacts. Language quality guardrails detect duplicated sentences, ensure readability is within a target level, and verify translations are accurate. Example: A validator LLM grades readability (e.g., “Is this answer clear for a non-technical reader?”) or detects if the model output accidentally repeated a phrase 3+ times.
✅ Content Validation & Integrity
These controls verify that structured claims in the output are consistent, accurate, and safe to show. They block competitor mentions, check price quotes against a pricing API, or confirm that references exist in the knowledge base. Example: If the model claims “The ticket price is $125,” a content validator can query the official API and refuse to pass through mismatched values.
⚙️ Logic & Functionality
Finally, logic guardrails focus on whether the model’s structured outputs are valid for downstream use. This includes schema validation for JSON tool calls, logical flow checks (e.g., “departure time can’t be after arrival time”), and OpenAPI response validation. Example: Use a JSON schema to validate tool calls—if invalid, reject or repair with a repair-prompt before invoking the tool.
Inputs & Retrieval as a single gate (stop junk early)
Dual moderation + instruction isolation at ingress prevents a lot of nonsense. For RAG, treat retrieved text as untrusted code:
- Strip scripts/HTML, drop base64 blobs, kill
<style>/hidden text. - Run PI heuristics (regex + small LLM) and quarantine or summarize to facts.
- Maintain allow/deny domain lists; attribute sources for later fact checks.
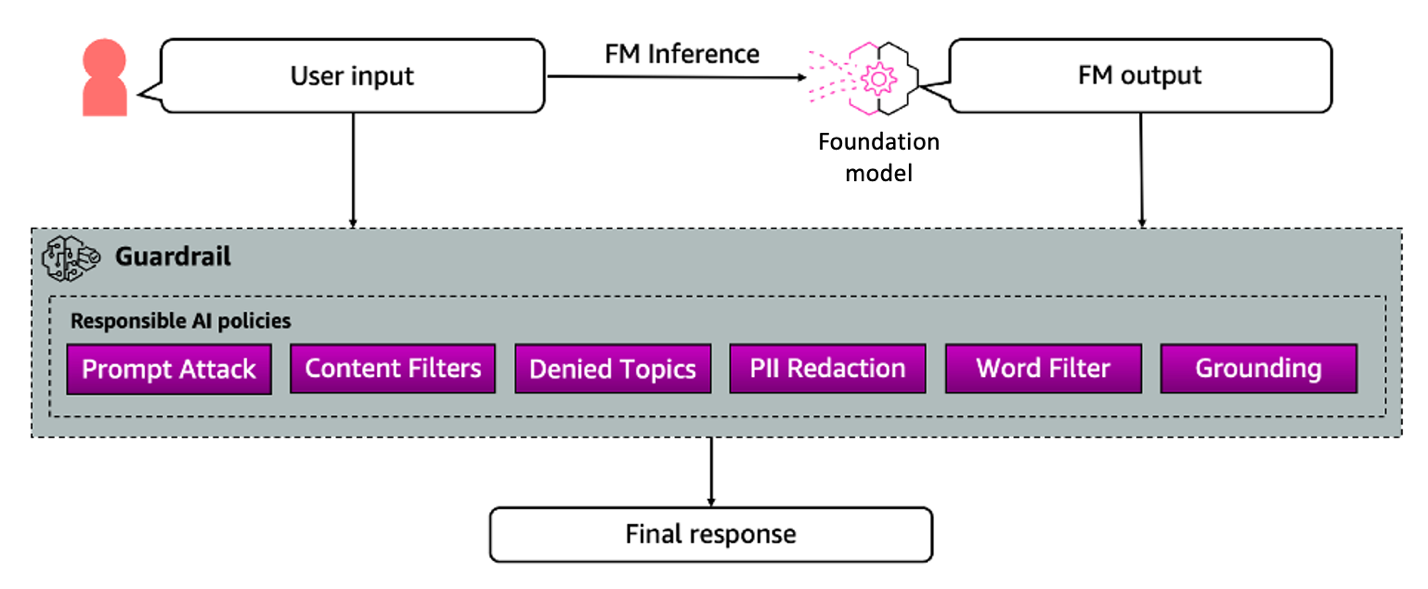
Source: AWS: Safeguard your generative AI workloads from prompt injections
Tool calls & outputs (where incidents actually happen)
Tool invocation is the riskiest part of an agentic system because it can create real-world effects — from sending an email to deleting a database record. That means the model’s freedom must be tightly constrained:
- Tool allowlist + JSON schema lock
Only expose a curated set of tools, and validate every tool call against a strict schema. Reject or repair malformed calls before they touch an API.
Example: A payment tool that expects
{"amount": 100, "currency": "USD"}will reject{ "amount": "delete all" }. - RBAC/IAM per tool
Scope each tool to the minimum privileges it needs. Even if a malicious prompt slips through, IAM boundaries prevent escalation.
Example: A “Calendar read” tool role should never have
DeleteEventpermission. - Human-in-the-loop (HITL) Route sensitive operations (fund transfers, account deletions) to a manual approval queue. Example: Wire transfers require operator confirmation before execution.
- Output validators before commit Don’t trust the model blindly. Run relevance checks, fact validation, URL availability checks, and readability scoring before persisting results or invoking tools.
Bedrock implementation + monitoring (ship it)
Amazon Bedrock Guardrails give you managed moderation, but you still need to know the difference between creating a guardrail and attaching it at runtime.
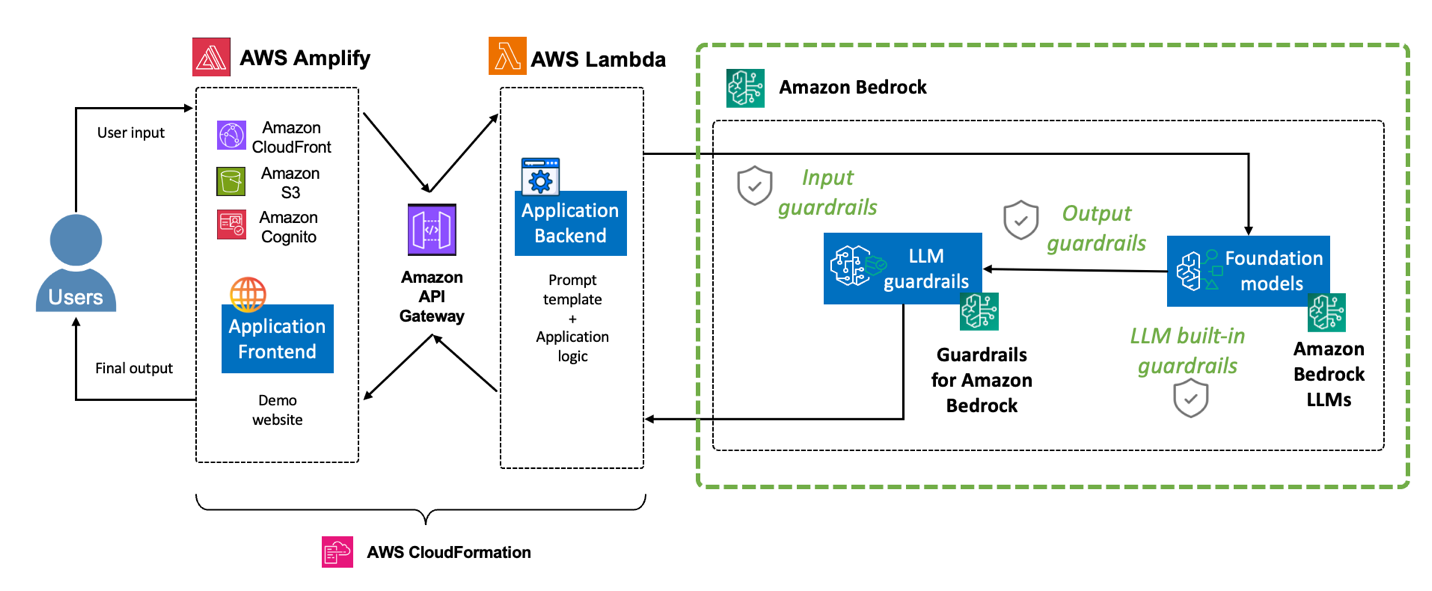
Source: AWS: Safeguard your generative AI workloads from prompt injections
Creating a Guardrail
- Console: Define denied topics, PII redaction, profanity filters, and Prompt Attack detection in the Bedrock UI.
- API/SDK: Use
CreateGuardrail/UpdateGuardrail. Each guardrail gets an immutableguardrailVersion. - Infrastructure as Code: Guardrails can also be created via AWS CDK or CloudFormation, so they’re versioned alongside your infrastructure. Recommended for production.
Attaching guardrails at runtime
Once created, reference them via guardrailConfig in model invocations:
resp = bedrock.converse(
modelId="anthropic.claude-3-5-sonnet",
messages=messages,
guardrailConfig={
"guardrailId": GUARDRAIL_ID,
"guardrailVersion": "1",
"trace": "enabled"
}
)
trace = resp.get("amazon-bedrock-trace", {})
if trace.get("interventions"):
return safe_refusal(trace) # log, explain, or route to human review
data = json.loads(resp.output_text) # enforce structure
jsonschema.validate(data, TOOL_CALL_SCHEMA) # reject or repair
- Input moderation happens before text reaches the model.
- Output moderation happens before the response is returned.
- Trace gives you logs of blocked/redacted items for observability.
Ops checklist
- CloudTrail → alerts on Guardrail config changes.
- CloudWatch → dashboards of block vs pass rates, anomalies.
- Invocation logs → monitor for jailbreak attempts or token spikes.
Minimal viable safety (then iterate)
If you’re starting fresh, don’t try to implement every guardrail at once. Begin with a core four that cover 80% of real-world risks:
- Input + Output moderation (Prompt Attack ON)
- Create a guardrail with Prompt Attack enabled.
- Attach it on every Bedrock call (
guardrailConfig).
- Instruction isolation
- Keep user input separate from system instructions.
- Use XML/JSON tags so the model can’t confuse the two.
<system>Always follow company rules</system>
<user>{query}</user> - Tool allowlist + JSON schema lock
- Register only approved tools in your framework (LangChain, LangGraph).
- Validate tool calls with
jsonschemabefore execution.
- CloudWatch + Guardrail trace dashboards
- Enable tracing and export metrics.
- Set alarms for spikes in blocked prompts or suspicious activity.
From here, layer on retrieval sanitization, fact-checking validators, and HITL approval for sensitive tools as your system matures.