From “Basic Prompting to “Prompting for Agents”
TL;DR
- Classic prompting aims for deterministic structure and outputs.
- Agent prompting aims for useful autonomy under constraints (tools, loops, budgets, verification).
- Ship with: (policy prompt, (good tools, (observability + guardrails, (small but real evals that gate releases.
Prompting 101
Five Basic Prompt Structure Elements

- 1-2 sentences to establish a persona and high-level task description – briefly explain the AI's identity and primary goal.
- Dynamic/Searchable Content – include dynamic data to be processed, such as user preferences and location information.
- Detailed Task Instructions – specify the steps and rules for executing the task.
- Examples/n-shot (optional) – provide input and output examples to guide the model.
- Repeat Key Instructions – for particularly long prompts, reiterate the most important instructions at the end. For further studying, check:
When handling more complex tasks, the prompt structure can be expanded to 10 elements:
Expanding to a More Detailed 10-Point Structure

- Task context – A more detailed description of the role and background
- Tone context – Explicitly define the tone, style, and personality of the response
- Background information, documents, and images – All static reference materials
- Detailed task description and rules – Complete execution steps, judgment criteria, and processing rules
- Examples – Input and output examples for multiple different scenarios
- Conversation history – Reference previous conversations if necessary
- Immediate task description or request – The specific task to be handled in the current round
- Step-by-step prompt – Include prompts such as "Think step by step" or "Take a deep breath"
- Output formatting – Detail the structure, format, and style of the response
- Prefilled response – Prefill a portion of the response to guide the model (Editor's note: This is a feature available only in the Claude API that allows you to prefill Assistant responses. The OpenAI API (This feature is not available)
This extended version is particularly suitable for handling complex tasks that require multiple considerations. Each element has its own specific purpose and can be selected based on actual needs.
 Extended thinking is great for development-time introspection (see how the model reasons) but costs tokens and hurts reproducibility. Use it to refine prompts; don’t rely on it in steady state.
Extended thinking is great for development-time introspection (see how the model reasons) but costs tokens and hurts reproducibility. Use it to refine prompts; don’t rely on it in steady state.
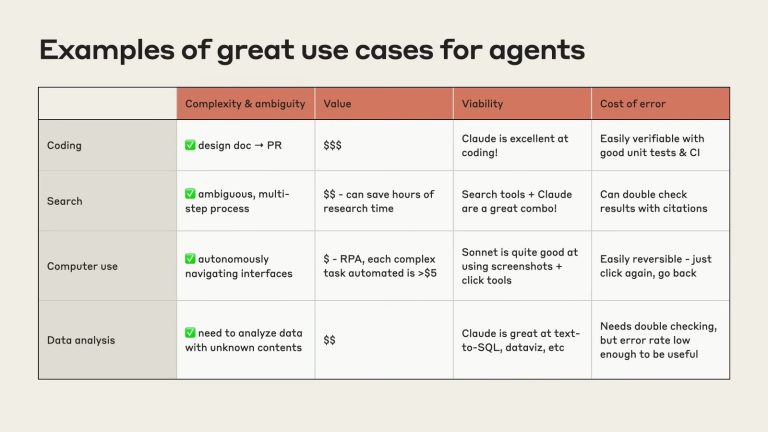
When to use an agent (and when not)
Use agents when the task is complex + valuable, requires tool use, and the path is uncertain. By “path” I mean the sequence of intermediate decisions and actions needed to get from a goal to a finished result: which tool to call first, what to search for, how to react to partial answers or errors, whether to branch, when to stop, and how to verify.
When the path is uncertain, you can’t reliably specify that sequence up-front because it depends on information you don’t yet have (or on non-deterministic environments). That’s why it matters: agents (models using tools in a loop) are designed to discover and adapt the path at runtime. If the path is fixed and predictable, a single prompt or a scripted workflow is cheaper, faster, and more reliable.

Agent prompting
7 principles you can ship
- Think like your agent — simulate the tool environment; if a new grad couldn’t succeed with your tool names/descriptions, neither will the agent.
- Give crisp heuristics, not scripts — budgets, stop criteria, preferred sources, and “good-enough” rules.
- Tool selection is design — fewer, orthogonal tools with excellent names + descriptions beat many near-duplicates.
- Guide the thinking — plan first, then interleave tool calls with reflection and verification.
- Expect side-effects — “always find best source” → infinite search; add time/tool/token budgets and timeouts.
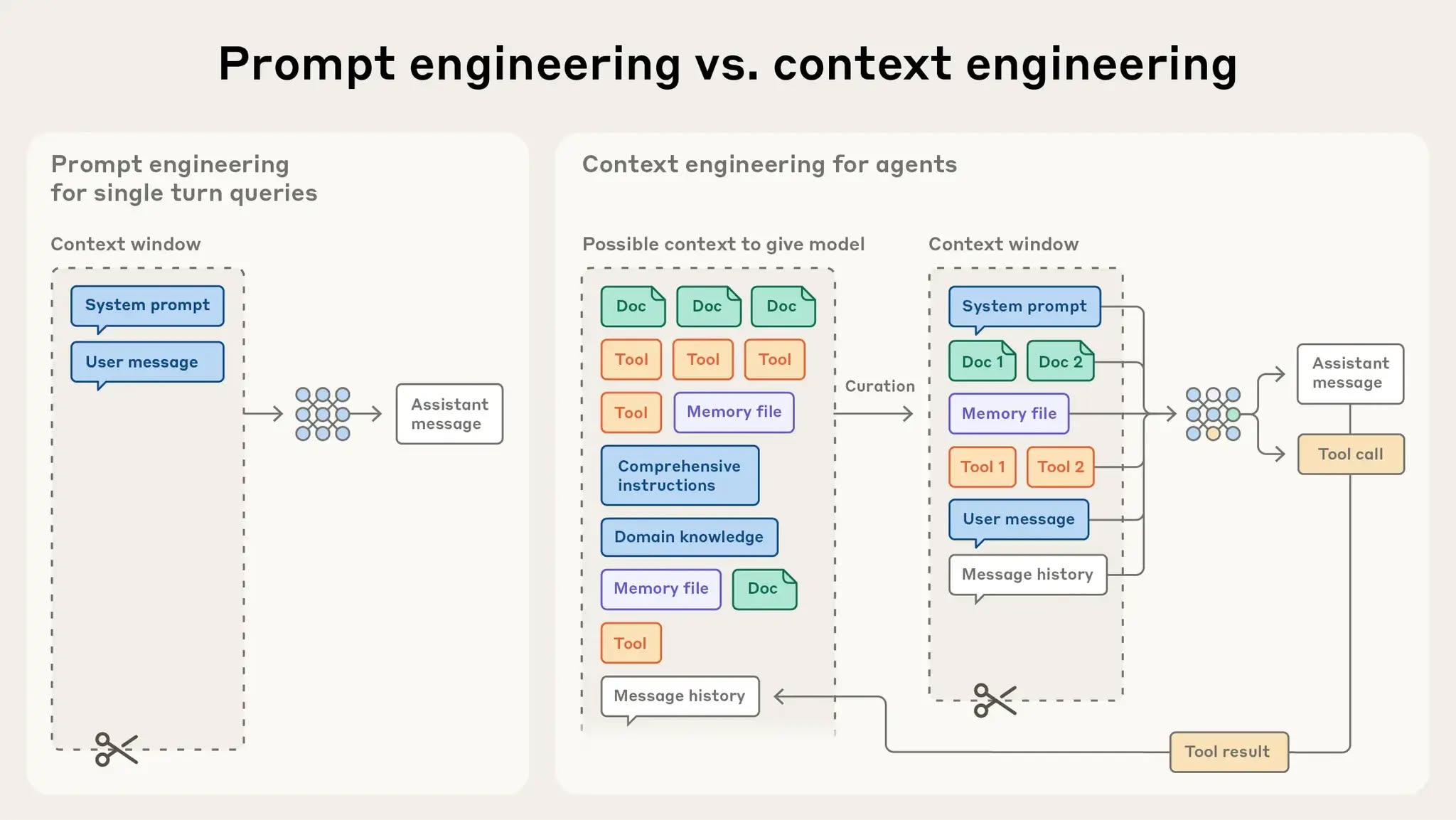
- Manage context — compaction, external scratch files, and sub-agents to avoid context bloat.
- Let the model be the model — start minimal; only add constraints where failures are observed.
For further studying, check:
Memory & context strategy
- Short-term (scratchpad): ephemeral thoughts + recent results.
- Long-term (external file/DB): decisions, artefacts, and facts with provenance; reload on resume.
- Compaction: summarise near 90–95% of context window; keep identifiers and decisions verbatim.
- Sub-agents: delegate heavy search/synthesis; compress results back to a lead agent.
Tooling that doesn’t sabotage you

When designing tools, use simple, accurate names that distinguish them from others. Avoid creating six similar search tools, making it difficult for the model to distinguish which to use. Consider merging tools if they are similar.
Tool descriptions should be detailed and well-formatted, including information about what the tool returns and how to use it. Avoid overly similar tool names or descriptions.
Tools that perform a single action are most effective, with no more than one level of nested parameters (e.g., three separate tools are better than one tool with multiple action parameters). Of course, be sure to test your tools to ensure that the agent can use them properly.
Evaluations that actually gate releases
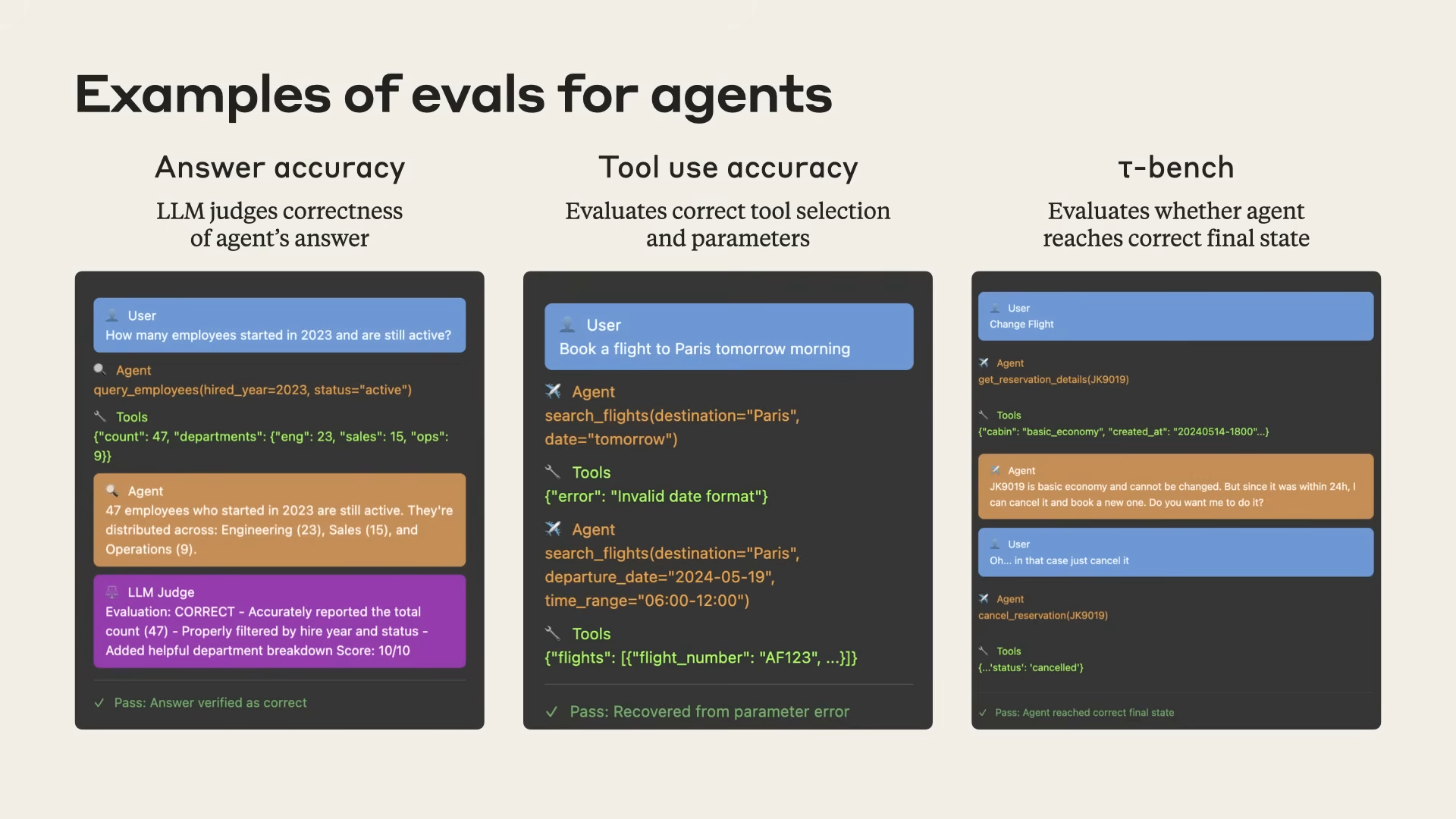
Start small but real; automate later.
Three layers
- Answer accuracy: LLM-as-judge with a rubric (accept ranges, verify citations).
- Tool-use accuracy: programmatically assert which tools must be called how many times.
- T-Bench (Final-state assertions): database/file/system state matches the requested change.
Release gates (suggested)
- Budgets respected (tool_calls/tokens/time/context).
- 0 schema violations; 0 destructive calls without confirmation.
- Rubric score ≥ threshold on a “golden” task pack; canary tasks pass.
- Incident playbook tested (abort/rollback).
Agent prompting: what’s unique (and why it matters)
Agent prompting is principle-driven, not step-scripted. Instead of long, linear recipes, you encode heuristics and policies that let the model plan, act, and adapt safely.
- Path = the sequence of intermediate decisions/actions from goal → result. Use agents when the path is uncertain (needs discovery, branching, verification, or deals with non-deterministic environments).
- Heuristics over scripts: budgets (tool calls/tokens/time), “good-enough” stop rules, preferred source order (internal → trusted APIs → web), and irreversibility rules (dry-run + confirm).
- Thinking guidance: plan first; interleave tool calls with reflection/verification before finalising.
- Context strategy: compaction near window limits, small external scratch files, or sub-agents; keep the lead agent’s context lean.
- Minimal few-shot: use examples sparingly; too many over-constrain behaviour.
- Operational guardrails: schema-validated outputs, corroboration for web facts (e.g., two independent sources or one primary), and deny-by-default for destructive tools.
Quick litmus tests (to avoid over-engineering):
- Recipe test: if a 5–7 step recipe works >95% of the time, don’t use an agent.
- Budget test: if a fixed, small number of tool calls doesn’t hurt quality, don’t use an agent.
- Oracle test: if banning lookups/verification craters quality, do use an agent.
Agent prompt design: structure & the key differences (vs classic prompting)
Recommended structure (production-oriented)
- Role & high-level task — what the agent is accountable for.
- Principles & heuristics — tool-selection policy, budgets, stop criteria, irreversibility controls.
- Thinking guidance — plan first (sources, budget, success criteria), then act; reflect between tool calls.
- Boundaries & error handling — what to do on tool failures, conflicts, or missing data; verification rules.
- Context strategy — when to compact, what to persist externally, when to delegate to sub-agents.
- Output contract — strict JSON/XML schema (validate downstream).
Key differences: classic prompting vs agent prompting
| Dimension | Classic prompting (ICL) | Agent prompting (policy) |
|---|---|---|
| Spec style | Step-by-step recipe | Principles & heuristics (budgets, stop rules, tool policy) |
| Examples | Few-shot common | Minimal; avoid over-constraining |
| Control | Order of operations, output schema | Plan-act-reflect loop, verification before final |
| State | Stateless, one-shot | Accumulating state; compaction, scratch files, sub-agents |
| Primary risks | Hallucination, format drift | Infinite search, tool thrash, context bloat |
| When to use | Deterministic tasks (classification, extraction, rewriting) | Uncertain path, tool use, high value/complexity |
Shipping tip: If you pick an agent, treat it like a service: add budgets, success criteria, verification, schema validation, tracing, and release-gating evals (answer accuracy, tool-use accuracy, final-state assertions).
Conclusion
Treat agents as services: policy-driven behaviour, high-quality tools, measured with budgets and final-state assertions. Keep prompts lean, tools sharp, and evals real. Add constraints only where failures appear. That’s how you get reliable autonomy in production.