Context Engineering
Why Context Engineering Matters
Modern agents interleave LLM calls with tool use, scratchpads, and persistence. While foundation models keep improving, their outputs are limited by a finite context window — think of it as the RAM for an LLM “CPU.”
- If context is managed poorly, agents suffer:
- Context poisoning → when a hallucination or bad data slips into context and contaminates reasoning.
- Context distraction → when too much context overwhelms the model and lowers accuracy.
- Context confusion → when irrelevant or superfluous details bias the response.
- Context clash → when different parts of the context contradict each other, reducing consistency.
👉 Context engineering is the discipline of filling the context window intelligently — ensuring the right data, in the right format, with the right tools, at the right time.
This is becoming the #1 job of AI engineers because bigger models and longer context lengths don’t solve the deeper issue: which information matters most right now, and how should it be delivered?
The Four Core Strategies of Context Engineering
LangChain’s framework highlights four complementary strategies:
- Write Context
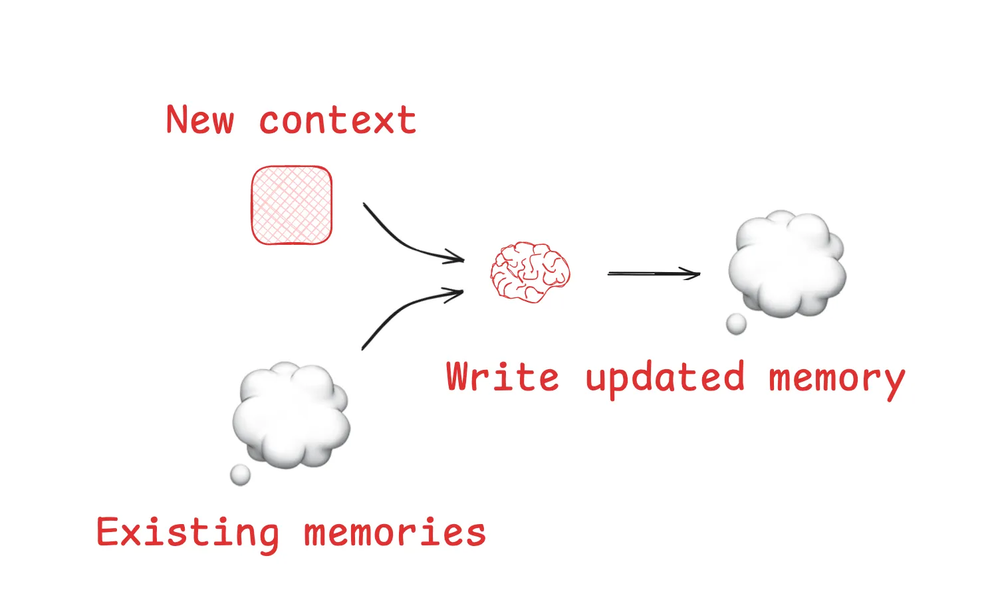
- Store knowledge outside the context window for later reuse.
- Examples: scratchpads for intermediate reasoning; memories (short-term or long-term) for persistence.
- Select Context
- Choose the most relevant subset to bring back into the window.
- Approaches: embeddings, retrieval rules, knowledge graphs, policies.
- Challenge: wrong selection feels like hallucination, even if the model is accurate.
- Compress Context
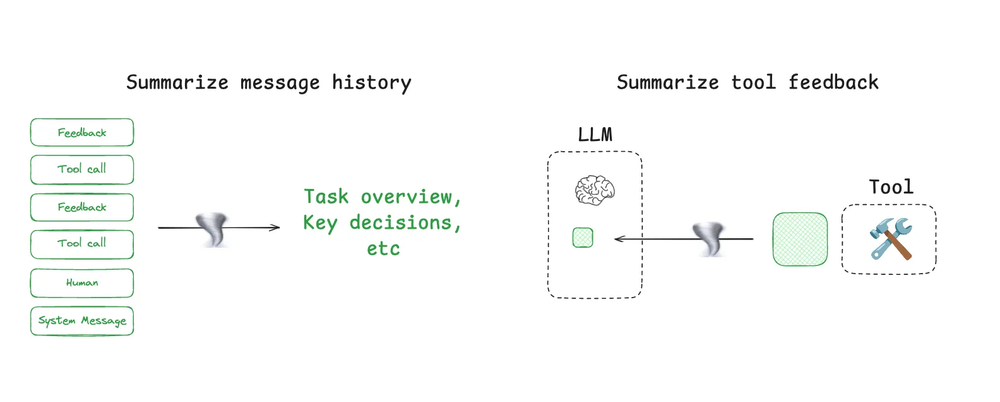
- Fit more signal into fewer tokens.
- Techniques: summarisation, clustering, higher-level abstraction.
- Benefits: reduces cost, latency, and distraction while retaining essentials.
- Isolate Context
- Separate streams so they don’t interfere.
- Examples: keep execution logs apart from system instructions; route different tasks through different subgraphs; isolate tool access as well as text.
Prompt engineering is just one piece of this puzzle — focused on clever wording inside a single prompt.
Context engineering is broader: it designs the entire dynamic system that decides which information, examples, tools, and formats get delivered to the model at runtime.
Memory in Context Engineering
Among the four strategies, memory is the backbone. Without it, every LLM call starts from zero. With poorly designed memory, agents bloat, drift, or leak. With well-designed memory, agents become adaptive, personal, and persistent.
Beyond generic context issues, persistent memory introduces its own design challenges:
- Over-insertion vs over-updating → if memory always creates new entries, it bloats; if it always overwrites, important history is lost. Use schema validation and evaluation tooling (e.g. LangSmith) to tune behaviour.
- Leakage across tasks → without namespace isolation, one thread’s memory can bleed into another. Scope memories tightly and enforce retrieval policies.
- Cold vs hot confusion → real-time (hot) memories may conflict with background-distilled summaries. A clear strategy for merging prevents clutter or contradictions.
These pitfalls are less about token limits and more about how memories are written, organised, and recalled in persistent systems.
Memory Types (What is Stored)
| Memory Type | What is Stored | Human Example | Agent Example |
|---|---|---|---|
| Semantic | Facts | Things I learned in school | User profile, preferences, known facts |
| Episodic | Experiences | Things I did | Past trips, previous tool-call traces |
| Procedural | Instructions | Instincts or motor skills | Agent system prompt, planning policies |
Memory Scope (Where it is Stored)
- Short-Term (Thread-Scoped)
- Lives only for the duration of a conversation or task.
- Tracks active state: conversation history, scratchpads, retrieved docs, or temporary constraints.
- Long-Term (Cross-Thread)
- Persists across sessions in a memory store organised as
(namespace, key, value). - Stores durable knowledge and patterns for reuse.
- Persists across sessions in a memory store organised as
Memory Matrix: Scope × Type
| Scope → / Type ↓ | Semantic (Facts) | Episodic (Experiences) | Procedural (Rules) |
|---|---|---|---|
| Short-Term | “This trip’s budget is £1,000.” | “Earlier in this chat, the user liked when the itinerary included evening walks.” | “Format today’s answers as bullet points.” |
| Long-Term | “User is vegetarian and lives in London.” | “Last summer, the user booked a Kraków trip and liked the food market tour.” | “Always include transport options in itineraries.” |
Memory Lifecycle
Defining memory types and scope explains what and where information is stored.
But in practice, building effective agents also requires managing the lifecycle of memory:
- Writing and updating memories during or after interactions.
- Storing and retrieving them in a structured way for later use.
This section covers how memories are created, updated, stored, and recalled — turning abstract concepts like “semantic” or “episodic” memory into concrete design choices that affect cost, latency, and user trust.
Writing and Updating Memories
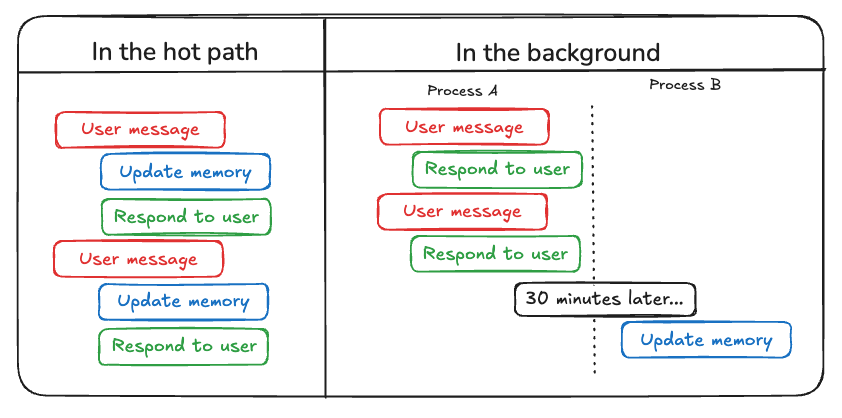
- In the hot path — immediate writes during runtime (e.g., saving a new preference mid-chat).
- Pros: instant relevance, transparency.
- Cons: adds latency, increases agent multitasking.
- In the background — batch jobs that summarise or merge profiles (e.g., nightly consolidation).
- Pros: cleaner consolidation, no latency overhead.
- Cons: freshness lag, scheduling complexity.
👉 Best practice: use hot path for critical facts, background for large-scale summarisation.
Storing and Retrieving Memories
Designing memory is not just about what to store, but also how to organise and retrieve it efficiently. In LangGraph, every memory entry follows the schema:
(namespace, key, value)
- Namespace – like a folder (e.g.,
user_id,trip_id,application_context). - Key – like a filename (e.g.,
"profile","trip-Apr2025"). - Value – a JSON object holding facts, examples, or instructions.
This structure enables hierarchical organisation: for instance, one namespace might contain all memories for a single user, while another groups organisation-wide knowledge.
Profiles vs Collections
Two common ways to structure long-term semantic memory:
- Profiles → a single JSON doc that is updated continuously (e.g.,
"profile"with dietary restrictions, budget, home city). Pro: easy to query in one go. Con: harder to update safely — risk of overwriting fields incorrectly. - Collections → many smaller memory objects (each preference or fact stored separately). Pro: easier to extend with new items. Con: harder to query comprehensively; requires aggregation/search.
Search and Retrieval
Agents rarely need the entire memory store. Instead, they retrieve selectively:
- Filter by metadata (namespace, labels, keys) → efficient and precise, but brittle if schemas change.
- Semantic search (vector embeddings) → finds relevant items by meaning, not just by key.
- Hybrid retrieval → combine metadata filters (“user=123, type=trip”) with semantic similarity (“budget-friendly European itineraries”).
Cross-namespace search is also supported, allowing an agent to pull data across users or contexts if designed to.
Retrieval Workflow
- Write — save new facts, experiences, or rules as
(namespace, key, value). - Select — filter and rank candidates using metadata and embeddings.
- Compress — summarise long docs into concise
{goals, constraints, outcomes}. - Isolate — route semantic → constraints, episodic → examples, procedural → instructions.
Example: User asks: “Plan 3 days in Kraków with food and history focus.” The retrieval pipeline might fetch:
- Semantic →
"diet": "no pork","budget": "mid". - Episodic → examples of past 3-day cultural itineraries.
- Procedural → “Offer pacing options if >10km walking/day.”
Pitfalls and Evaluation
- Over-insertion vs over-updating → some models keep adding duplicates, others overwrite aggressively. Schema validation and evaluation help balance this.
- Quality of recall is as important as storage. Tools like LangSmith let you audit what was retrieved and injected into context, so debugging isn’t limited to model outputs alone.
Diagram: Memory-Centric Context Flow
Practical Guidance for Builders
Implementation Checklist
- Design schema first — define semantic, episodic, procedural slots.
- Choose write strategy — hot path for critical facts, background for profiles/exemplars.
- Add guardrails — schema constraints, moderation, rollback/versioning.
- Select precisely — retrieval quality is as important as model choice.
- Compress smartly — summarise into goals, constraints, outcomes.
- Isolate channels — separate instructions, memory recall, and scratchpads.
- Observe context assembly — trace what was retrieved and injected (LangSmith helps here).
- Measure performance — track “memory hit rate” and “user trust,” not just accuracy.
Key Lessons
- Context engineering is as critical as model tuning. Bigger windows don’t fix bad selection.
- Memory is the backbone. Short-term = smooth conversation; long-term = durable knowledge.
- Retrieval quality = user trust. Wrong recalls feel like hallucinations.
- Tools and formatting are context too. A well-structured JSON can matter more than an extra 1k tokens.
- Design for confidence, not just accuracy. Schema, isolation, reversibility, and transparency are adoption drivers.
✅ The real differentiator in agents isn’t smarter models, but smarter context engineering.